Introduction
MarkLogic provides the ability to modify how the server tokenizes text in certain parts of documents by changing how particular characters are classified. Characters classified as space or punctuation will break tokens and not be included in the index. Characters classified as symbol or word characters will be included in the index, and will or will not break tokens, respectively.
Characters can even be removed entirely: neither appearing in the index nor breaking tokens. With this simple mechanism you achieve some powerful effects. Let’s see how.
The Problem: Searching Tweets
Imagine a database loaded with tweets with some metadata providing information about where and when the tweet was sent and the person who sent them. Tweets use some punctuation in special ways: at signs (“@”) mark user names, and hash marks (“#”) mark topics. So "@NASA" is the official NASA user, and "#NASA" indicates a tweet about NASA.
Here are some sample tweets encoded in XML:
<doc> <user>spacecadet47</user> <mobilemobile>>(650)701-1212</ <impact-score>45.21</impact-score> <dt>2013-11-01T12:00:22</dt> <location lat="34.156111" long=""-118.1319443>Pasadena</location> <tweet>@NASA thanks for inviting me to the social! I'm learning so much!</tweet> </doc>
<doc> <user>zsmspif</user> <mobilemobile>>3612125678</ <impact-score>2.01</impact-score> <dt>2013-03-08T01:19:13</dt> <location lat="47.471944" long="19.050278">Budapest</location> <tweet>Rumour has it NASA is announcing MSL finding organic carbon at press conference Tuesday.</tweet> </doc>
<doc> <user>ndtchgrlz</user> <mobilemobile>>701 6509921</ <impact-score>139.87</impact-score> <dt>2012-12-12T18:20:03</dt> <location lat="46.877222" long="-96.789444">Fargo</location> <tweet>Streambed on Mars! #NASA #MSL</tweet> </doc>
Suppose I want to explore this data and distinguish between tweets directed at NASA from those about NASA. Since this is a large database, my application will be using unfiltered search for better performance, so I want the matches found in the index to be as accurate as possible, with no need for filtering. For this application, when I search for the user "@NASA" I want the index to only return tweets containing "@NASA" and not those with just the word "NASA" or the topic "#NASA". And when I search for the word "NASA" I do not want the index to return matches for the user "@NASA".
Punctuation is not indexed in MarkLogic, however, so "@NASA", "#NASA", and "NASA" will all show up in the indexes and the lexicons exactly the same way: as "NASA". Estimates and unfiltered searches will not distinguish these in any way.
So the following searches (fetching results from a REST server configured on port 8003):
Get / search?q=NASAGET /search?q=@NASAGET /search?q=%23NASA
Will all return the same set of tweets:
<tweet>@NASA thanks for inviting me to the social! I'm learning so much!</tweet> <tweet>Rumour has it NASA is announcing MSL finding organic carbon at press conference Tuesday.</tweet> <tweet>Streambed on Mars! #NASA #MSL</tweet>
Why is this? Let’s enable the return-plan search option so that we can see how the query is being resolved. Create the following tweet_options.xml file and POST it to the REST server:
When we search for "@NASA" we will see that the query sent to the index doesn’t even include the punctuation mark:
<search:plan>
<qry:query-plan xmlns:qry="https://marklogic.com/cts/query">
<qry:info-trace>xdmp:value("xdmp:plan(cts:search(fn:collection(),cts:query($query),$options,...")</qry:info-trace>
<qry:info-trace>Analyzing path for search: fn:collection()</qry:info-trace>
<qry:info-trace>Step 1 is searchable: fn:collection()</qry:info-trace>
<qry:info-trace>Path is fully searchable.</qry:info-trace>
<qry:info-trace>Gathering constraints.</qry:info-trace>
<qry:word-trace text="NASA">
<qry:keyqry:key>>3178996703552976097</
</qry:word-trace>
<qry:info-trace>Search query contributed 1 constraint: cts:word-query("@NASA", ("lang=en"), 1)</qry:info-trace>
<qry:partial-plan>
<qry:term-query weight="1">
<qry:keyqry:key>>3178996703552976097</
<qry:annotation>word("NASA")</qry:annotation>
</qry:term-query>
</qry:partial-plan>
<qry:info-trace>Executing search.</qry:info-trace>
<qry:final-plan>
<qry:and-query>
<qry:term-query weight="1">
<qry:keyqry:key>>3178996703552976097</
<qry:annotation>word("NASA")</qry:annotation>
</qry:term-query>
</qry:and-query>
</qry:final-plan>
<qry:info-trace>Selected 3 fragments</qry:info-trace>
<qry:result estimate="3"/>
</qry:query-plan>
</search:plan>
The Solution: Customized Tokenization
Customized tokenization allows you to control how specific Unicode codepoints will be classified by the tokenizer, which affects how the tokenizer breaks up the text, which ultimately affects how indexing and search will handle those tokens.
Searching for Users
For this application, when I search for the user "@NASA" I want the index to only return tweets containing "@NASA" and not those with just the word "NASA" or the topic "#NASA". And when I search for the word "NASA" I do not want the index to return matches for the user "@NASA". To achieve this goal, I am going to instruct the tokenizer to treat the at sign as a normal word character when it appears in the body of a tweet.
The procedure is simple:
- Define a field that encompasses the body of the tweet.
- Define a tokenizer override for that field that reassigns the
"@"character to thewordtokenizer class. - Reindex the data using the new tokenization rules.
- Define the field as a query constraint if it is to be used through the higher level APIs, such as the REST interface.
Since tokenization can only be customized on fields, the first step is to create a field. This can be done through the Admin Interface as described in the Overview of Fields in the Administrator’s Guide. It is also possible to script this using the Admin API, but here I will just use the Admin user interface to create a field over the tweet child of my documents and add the customized tokenization settings.
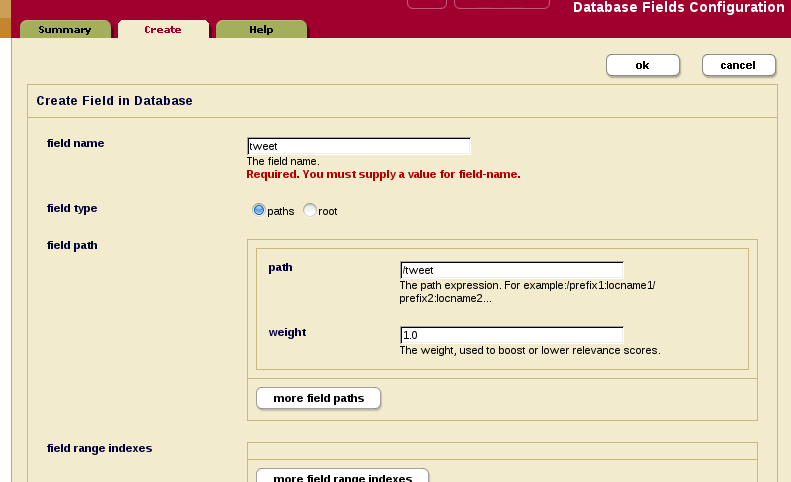
Tokenization overrides are set on the same page in the Admin Interface (see below):
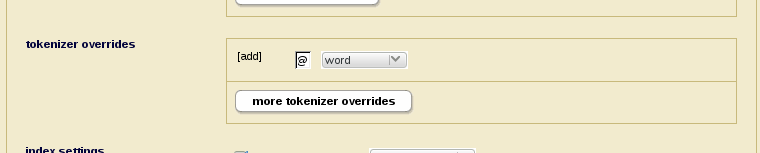
Reindexing is necessary to apply the new tokenization rules to data already in the database. On a large database you want to be sure to set up the tokenization rules before loading data to avoid having to reindex a lot of data.
If we want to make use of the field in the higher level APIs, such as through REST or Java, we’ll want to make a binding for it in the search options.
Adding the Field ‘tweet’
That’s it! Searches against the new field will produce different results from word searches within those elements. The search for "@NASA" only matches the tweet that has that user name in it, but the other searches are unaffected.
GET /search?options=tweet&q=tweet:NASA |
<tweet>Rumour has it NASA is announcing MSL finding organic carbon at press conference Tuesday.</tweet> <tweet>Streambed on Mars! #NASA #MSL</tweet> |
GET /search?options=tweet&q=tweet:@NASA |
<tweet>@NASA thanks for inviting me to the social! I'm learning so much!</tweet> |
GET /search?options=tweet&q=tweet:%23NASA |
<tweet>Rumour has it NASA is announcing MSL finding organic carbon at press conference Tuesday.</tweet> <tweet>Streambed on Mars! #NASA #MSL</tweet> |
A look at the query plan explains these results: now the at sign is regarded as part of the word and is sent intact to the index:
Searching for Topics
For this application, when I search for the topic "#NASA" I want the index to only return tweets containing "#NASA" and not those with just the word "NASA" or the user "@NASA". And when I search for the word "NASA" I do not want the index to return matches for the user "@NASA", but I do want to see matches for tweets containing the topic "#NASA". This time, instead of instructing the tokenizer to treat the hash mark as a normal word character when it appears in the body of a tweet, I will instruct it to treat the hash mark as a symbol. As a symbol it will still be included in the index, but as a separate word token.
Since I already have the field defined, all I need to do is add the tokenizer override in that field to reassign the "#" character to the symbol tokenizer class. This can be done in the field configuration page in the Admin interface.
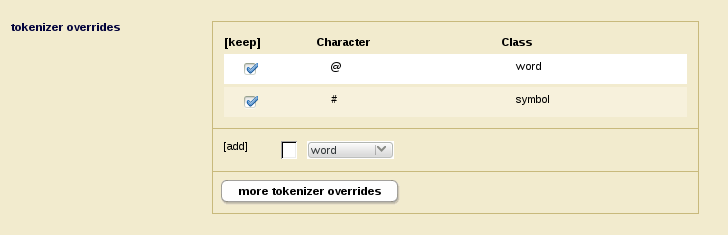
Now we get different results for the searches for "NASA" and "#NASA" within the field:
GET /search?options=tweet&q=tweet:NASA |
<tweet>Rumour has it NASA is announcing MSL finding organic carbon at press conference Tuesday.</tweet> <tweet>Streambed on Mars! #NASA #MSL</tweet> |
GET /search?options=tweet&q=tweet:@NASA |
<tweet>@NASA thanks for inviting me to the social! I'm learning so much!</tweet> |
GET /search?options=tweet&q=tweet:%23NASA |
<tweet>Streambed on Mars! #NASA #MSL</tweet> |
This works because now "#NASA" is seen as a phrase of the two words "#" and "NASA". We won’t find a match to this phrase in the tweet that has the bare word "NASA". On the other hand, the bare word "NASA" will find a match against the phrase "#NASA" in a tweet, just as a word search for "Mars" will match the phrase "on Mars" in the document.
Searching for Phone Numbers
Phone numbers are stored in an inconsistent format: some have no punctuation at all, while others uses spaces or parentheses and hyphens. I want to be able to search for a phone number as the whole number, or with wildcarding and correctly match the actual phone number, ignoring the formatting. This could be solved at ingestion time by normalizing the phone numbers, but we can also use custom tokenization to achieve the same result.
First, consider the following queries and matching phone numbers, assuming the database has been configured for trailing wildcards:
GET /search?options=tweet&q=6507011212 |
|
GET /search?options=tweet&q=701-650-9921 |
|
GET /search?options=tweet&q=650* |
(650)701-1212 701 6509921 |
GET /search?options=tweet&q=701-650* |
(650)701-1212 701 6509921 |
Since the punctuation and spacing is inconsistent and creates inconsistent token boundaries, it is hard to find searches that give consistent results. The solution is to create another field that covers the mobile child of the document in which the relevant punctuation and space characters are redefined to the remove tokenizer class. When a character is in this class, it is as if it didn’t appear in the text stream as far as the search and indexing is concerned.
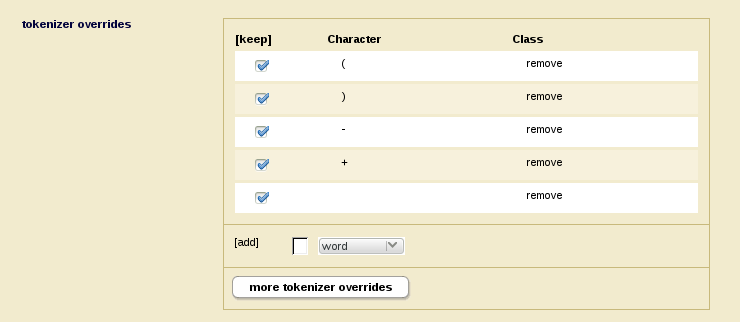
Search Options for Field with Phone Numbers
<options xmlns="https://marklogic.com/appservices/search">
<search-option>unfiltered</search-option>
<quality-weight>0</quality-weight>
<return-plan>true</return-plan>
<debug>true</debug>
<constraint name="tweet">
<word>
<field name="tweet"/>
</word>
</constraint>
<constraint name="phone">
<word>
<field name="phone" />
</word>
</constraint>
</options>
# update options curl --anyauth --user user:password -X DELETE \ -i -H "Content-type:application/xml" \ https://localhost:8003/v1/config/query/tweet curl --anyauth --user user:password -X POST -d@'./tweet_options.xml' \ -i -H "Content-type:application/xml" \ https://localhost:8003/v1/config/query/tweet
Now we can search for phone numbers in this field and it doesn’t matter if the phone number was formatted in either the query or the document. In effect, the proper matches are found:
GET /search?options=tweet&q=phone:6507011212 |
(650)701-1212 |
GET /search?options=tweet&q=phone:701-650-9921 |
701 6509921 |
GET /search?options=tweet&q=phone:650* |
(650)701-1212 |
GET /search?options=tweet&q=phone:701-650* |
701 6509921 |
Analytics
The new rules can be used for more than just search. Suppose I want to find out which users are mentioned in a tweet about a certain word. To do that, first I set up a field word lexicon on my “tweet” field. Again, this can be scripted or done on the field configuration page in the Admin interface.
Next the field word lexicon needs to be setup as the suggestion source in the query options.
Adding a Suggestion Source
<options xmlns="https://marklogic.com/appservices/search">
<search-option>unfiltered</search-option>
<quality-weight>0</quality-weight>
<return-plan>true</return-plan>
<debug>true</debug>
<constraint name="tweet">
<word>
<field name="tweet"/>
</word>
</constraint>
<constraint name="phone">
<word>
<field name="phone" />
</word>
</constraint>
<default-suggestion-source>
<word>
<field name="tweet" collation="https://marklogic.com/collation/codepoint"/>
</word>
</default-suggestion-source>
</options>
curl --anyauth --user user:password -X DELETE \ -i -H "Content-type:application/xml" \ https://localhost:8003/v1/config/query/tweet curl --anyauth --user user:password -X POST -d@'./tweet_options.xml' \ -i -H "Content-type:application/xml" \ https://localhost:8003/v1/config/query/tweet
By constraining the suggestions to what starts with "@" only mentioned users will be returned.
GET /suggest?options=tweet&partial-q=@&q=social |
<search:suggestions xmlns:search= "https://marklogic.com/appservices/search"> <search:suggestion>@NASA</search:suggestion> </search:suggestions> |
It should be noted, however, that on a large database this technique may not perform well, and adding explicit markup is probably a better option.
Set Up Scripts
This section describes the scripts required to produce the final working setup.
-
- Execute the XQuery script setup1.xqy. You can copy this entire script into a QConsole buffer and execute it there.
- Execute the shell script setup2.sh. It assumes you have
curlavailable as well as the tweet_options.xml file.
See the code below for the scripts below:
xquery version "1.0-ml";
(: Create the database and forest on current host :)
import module namespace admin="https://marklogic.com/xdmp/admin"
at "/MarkLogic/admin.xqy";
let $config := admin:get-configuration()
let $config :=
admin:database-create($config, "tweets",
xdmp:database("Security"), xdmp:database("Schemas"))
let $config := admin:forest-create($config, "tweetsF1", xdmp:host(), ())
return admin:save-configuration($config)
;
xquery version "1.0-ml";
(: Associate forest with the database :)
import module namespace admin="https://marklogic.com/xdmp/admin"
at "/MarkLogic/admin.xqy";
let $config := admin:get-configuration()
let $dbid := admin:database-get-id($config, "tweets")
let $asid := admin:forest-get-id($config, "tweetsF1")
let $config := admin:database-attach-forest($config, $dbid, $asid)
return admin:save-configuration($config)
;
xquery version "1.0-ml";
(: Create the fields 'tweet' and 'phone' with their overrides and
add a field word lexicon to 'tweet' :)
import module namespace admin = "https://marklogic.com/xdmp/admin"
at "/MarkLogic/admin.xqy";
let $config := admin:get-configuration()
let $dbid := xdmp:database("tweets")
let $f1 := admin:database-field("tweet", fn:false())
let $config := admin:database-add-field($config, $dbid, $f1)
let $e1 := admin:database-included-element("", "tweet", 1.0, "", "", "")
let $config :=
admin:database-add-field-included-element($config, $dbid, "tweet", $e1)
let $config :=
admin:database-add-field-tokenizer-override(
$config, $dbid, "tweet",
(admin:database-tokenizer-override("@","word"),
admin:database-tokenizer-override("#","symbol"))
)
let $l1 :=
admin:database-word-lexicon("https://marklogic.com/collation/codepoint")
let $config :=
admin:database-add-field-word-lexicon($config, $dbid, "tweet", $lexicon)
let $f2 := admin:database-field("phone", fn:false())
let $config := admin:database-add-field($config, $dbid, $f2)
let $e2 := admin:database-included-element("", "phone", 1.0, "", "", "")
let $config :=
admin:database-add-field-included-element($config, $dbid, "tweet", $e2)
let $config :=
admin:database-add-field-tokenizer-override(
$config, $dbid, "phone",
(admin:database-tokenizer-override("-","remove"),
admin:database-tokenizer-override("(","remove"),
admin:database-tokenizer-override(")","remove"),
admin:database-tokenizer-override("+","remove"),
admin:database-tokenizer-override(" ","remove"))
)
return admin:save-configuration($config)
;
xquery version "1.0-ml";
(: Create a REST server and associate it with the database :)
import module namespace boot-util="https://marklogic.com/rest-api/bootstrap-util"
at "/MarkLogic/rest-api/lib/bootstrap-util.xqy";
boot-util:bootstrap-rest-server("tweets", "Modules", "Default", "TweetServer", 8003)
;
# make sure tweet_options.xml is in your current directory and # replace user:password with your credentials and replace localhost with hostname as needed curl --anyauth --user user:password -X POST -d@'./tweet_options.xml' \ -i -H "Content-type:application/xml" \ https://localhost:8003/v1/config/query/tweet
<?xml version="1.0" encoding="UTF-8"?>
<options xmlns="https://marklogic.com/appservices/search">
<search-option>unfiltered</search-option>
<quality-weight>0</quality-weight>
<return-plan>true</return-plan>
<debug>true</debug>
<constraint name="tweet">
<word>
<field name="tweet"/>
</word>
</constraint>
<constraint name="phone">
<word>
<field name="phone"/>
</word>
</constraint>
<default-suggestion-source>
<word>
<field name="tweet" collation="https://marklogic.com/collation/codepoint"/>
</word>
</default-suggestion-source>
</options>