MarkLogic has the ability to call out to C++ code to do Map/Reduce calculations. This lets you add any kind of aggregation function your project needs, in a highly performant way. You pass in one or more range indexes and MarkLogic farms them out to the stand level for computation.
MarkLogic also has some built-in aggregate functions, like covariance and standard deviation. To play around with this feature, I built a User-Defined Function (UDF) to calculate how many results fall on each day of the week.
The Problem
Suppose I have a set of data, such as incidents of crime in an area, and I’d like to do some analysis to see on what day of the week events happen. The data set includes the date on which the incidents occur, but not the day of the week. The data might be GitHub checkins, blog posts, or rainy days, but you get the picture: I want to slice the data in a way the data don’t already support.
Previous Approach
Before UDFs were available, I would have implemented that feature by recording the day of week at ingest time: call xs:date element and add a new element or attribute to store it. Let’s say I have something like this (0 = Sunday):
<incident-date dow="0">2012-01-01</incident-date>
Once that’s done, I can run fast queries on the day of the week, in this case looking for what happened on weekends:
xdmp:estimate(cts:search(
fn:doc(),
cts:element-attribute-value-query(xs:QName("incident-date"), xs:QName("dow"), ("0", "6"))
))
With an index on the attribute, I can even build a Search API facet:
<options xmlns="https://marklogic.com/appservices/search">
<constraint name="dow">
<range type="xs:int" facet="true">
<element ns="" name="incident-date"/>
<attribute ns="" name="dow"/>
</range>
</constraint>
</options>
Now when I call search:search(), I’ll have counts for each day of the week.
Okay, so I’ve just shown I can do a day-of-week facet without User-Defined Functions. But to do it, I had to modify my original data and set up an additional index, both of which take up more space. Maybe I’m okay with that, maybe not. Maybe I’ve got a really big database and just now figured out that days of the week would be interesting to look at. Do I need to modify all that data?
Nope. MarkLogic provides a new option in the eternal tradeoff of space-versus-time.
New Approach
A User-Defined Function is C++ code that runs with range indexes as inputs. You’ll find the documentation in the User Defined Function section of the updated Application Developer’s Guide, but here’s the process in a nutshell:
- Write the C++ code that executes the calculations you want.
- Build it using the MarkLogic-provided Makefile (which not only sets up the correct links and include directories, but packages your code as a plugin for MarkLogic.
- Load the plugin.
- Run the
cts:aggregate()function to use your UDF
MarkLogic now ships with examples that help illustrate #1 — on Linux, you’ll find them in /opt/MarkLogic/Samples/NativePlugins/ 1 . For my example, I copied SamplePlugin.cpp and Makefile from that directory to one of my own, modified the code and did a simple “make”. Just like that, I had a plugin. Well, after working through a bunch of reminders of how long it’s been since I wrote C++.
Let’s take a closer look.
Building the UDF
I copied SamplePlugin.cpp to DayOfWeek.cpp. That file defines multiple UDFs, so I stripped out all but one and renamed that class to DayOfWeek. (Note that the file and class don’t need to have the same name; I could call it Temporal.cpp and add some other time-related UDFs.) Now I can go function by function, defining what I need.
Start
This function gets a sequence of arguments, which can be optionally passed to your UDF to clarify the work the UDF needs to do. These arguments would be in addition to whatever range indexes get passed in later. I didn’t need any additional parameters for this UDF, so I didn’t need to do anything here. I decided I would do one thing: log a message that the UDF had started.
Each of the functions that we override includes a Reporter parameter, which we can use to log progress.
void DayOfWeek::start(Sequence& arg, Reporter& reporter)
{
reporter.log(Reporter::Info, "DOW start()");
}
This function will get called just once, on the e-node where the UDF first gets called.
Map
Next we’ll tackle the map method. When a UDF runs, it farms out the work down to the stand level (database -> forest -> stand). At that level, the UDF does calculations on the range index values present in that stand. Suppose there are 100 documents in a particular stand and each document has one <posted-on> element. When the UDF’s map method gets called with the posted-on element’s range index, the method will get those 100 posted-on values as an iterator, figure out the day of the week for each and sum up each day’s count.
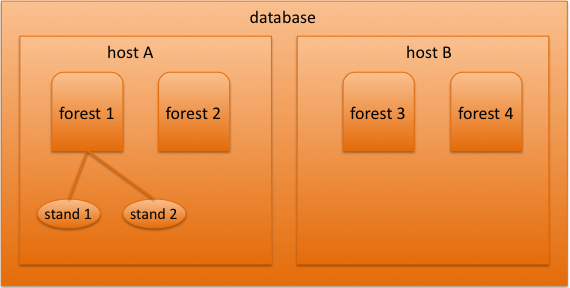
Figure 1: Database, forests, and stands
void DayOfWeek::map(TupleIterator& values, Reporter& reporter)
{
marklogic::DateTime v;
time_t iVal;
struct tm timeval;
int dow;
for(; !values.done(); values.next()) {
if(!values.null(0)) {
values.value(0, v);
iVal = v;
localtime_r(&iVal, &timeval);
dow = timeval.tm_wday;
counts[dow] += values.frequency();
}
}
}
When this function ends, the counts array will have values representing this particular stand. Separately, the same method will be called for every other stand in the database, on as many MarkLogic nodes as have forests for the database. Thus, we end up with a bunch of different DayOfWeek objects, each holding a set of counts.
Reduce
To consolidate the DayOfWeek UDF objects, we enter the reduce phase. Every time we call this function we take two of these objects and consolidate into one, in this case combining the counts arrays of each. In the diagram above, the values from Forest 1′s two stands will get reduced together, forest 2′s stands will get reduced together, and forest 1 and 2′s values will get reduced together. Eventually these will be combined with the values from host B, resulting in a single, consolidated set of values.
void DayOfWeek::reduce(const AggregateUDF* _o, Reporter& reporter)
{
const DayOfWeek*o = (const DayOfWeek*)_o;
for (int i=0; i<7; i++) {
counts[i] += o->counts[i];
}
}
Since we reduce two into one with each call, you can imagine that this function gets called one less time than we called map(), ultimately resulting in a single DayOfWeek object with a single set of counts values.
Finish
Once the reduce stage has gotten down to a single object, it’s time for that object to format the results in the way MarkLogic expects to receive them. MarkLogic will build an XQuery map:map() object from the results, so the finish method writes out its data in a way that can be used to build a map.
void DayOfWeek::finish(OutputSequence& os, Reporter& reporter)
{
reporter.log(Reporter::Info, "DOW finish()");
char key[2];
os.startMap();
for (int i=0; i<7; i++) {
sprintf(key, "%d", i);
os.writeMapKey(key);
os.writeValue(counts[i]);
}
os.endMap();
}
To do this, we use an OutputSequence, which knows how to build a map from a set of values. We tell it to start the map, then we alternate specifying a key and a value. We end the map, and MarkLogic takes it from there. I also threw in another reporter.log() call for tracking. These reports will end up in the usual MarkLogic ErrorLog.txt.
Encode and Decode
If your database has forests on multiple nodes, then at some point MarkLogic will need to transfer UDF objects between nodes in order to reduce them. To accomplish this, a UDF must implement the encode and decode methods, showing how to serialize and deserialize the data. For the DayOfWeek UDF, this just means writing and reading the contents of the counts array.
void DayOfWeek::encode(Encoder& e, Reporter& reporter)
{
for (int i=0; i<7; i++)
e.encode(counts[i]);
}
void DayOfWeek::decode(Decoder& d, Reporter& reporter)
{
for (int i=0; i<7; i++)
d.decode(counts[i]);
}
This task is made easier by the Encoder and Decoder objects passed into the methods. These classes are provided by MarkLogic. All I need to do is call the encode and decode methods on the respective objects in the same order.
Making the UDF Available
There are additional details I could get into with the UDF implementation, but I want to keep this example pretty simple. Let’s move on to how to use the UDF. We first need to tell MarkLogic about it. There are a few steps in this process.
Registering a Name
The first step happens in the code, where we specify how this UDF should be registered. You’ll find examples of this at the end of SamplePlugin.cpp. Here’s what I did for DayOfWeek:
extern "C" PLUGIN_DLL void
marklogicPlugin(Registry& r)
{
r.version();
r.registerAggregate<DayOfWeek>("day-of-week");
}
This associates a name (“day-of-week”) with the class (DayOfWeek). We’ll use this name when we actually want to call the UDF.
Building
Naturally we would compile and build while developing the UDF, to catch any syntax errors. We can use the MarkLogic-provided Makefile to do this. Simply calling make without specifying a target will build a dynamically-loaded library based on the platform where the build is done (.dll, .so, .dylib) and zip it up along with a manifest expected by the MarkLogic plugin loader.
Installing
Next, we use Query Console to tell MarkLogic about the ZIP file, using the XQuery function plugin:install-from-zip():
xquery version "1.0-ml";
import module namespace plugin = "https://marklogic.com/extension/plugin"
at "MarkLogic/plugin/plugin.xqy";
plugin:install-from-zip("native",
xdmp:document-get("/Users/dcassel/project/plugin/day-of-week.zip")/node())
MarkLogic will read in the ZIP file and copy the contents to a safe place where it will be able to find it (on my Mac, it was ~/Library/Application Support/MarkLogic/Data/Lib/native/day-of-week/; on Linux /var/opt/MarkLogic/Lib/native/day-of-week.) At this point, the UDF is considered a native plugin and is available to be used — MarkLogic will see it when the UDF is called without any need to restart MarkLogic itself.
Calling
Last but not least, we can call the UDF.
cts:aggregate(
"native/day-of-week",
"day-of-week",
cts:element-reference(xs:QName("postedTime"), "type=dateTime"),
(),
(),
"soccer"
)
Here I’ve called the cts:aggregate() XQuery function, which is the gateway to using UDFs. I’ve specified which native plugin to use and the name of the UDF that I want. The cts:element-reference() call is a new way to specify what I want to target, in this case the element range index on postedTime, which has the dateTIme type. In the last parameter, I threw in a “soccer” query, so the day-of-week calculation will take place on postedTime values in fragments that match the word query “soccer”.
Running this in Query Console, I get back a map:map(), as you would expect from looking at the finish method above. The results map from day-of-week code (0 = Sunday) to the count of dateTimes that fell on that day of the week. I’ve got some future posts in mind where we’ll look at what to do with the map data once you have it.
The ability to define UDFs, along with the newly provided build-in aggregation functions, opens up new ways to look at your data. I’m curious what you come up with. Leave a comment with an idea for a useful UDF!