MarkLogic is an enterprise-class NoSQL database that includes a REST enabled full-text search feature. This tutorial will walk you through a series of HOWTOs for working with MarkLogic exclusively through its REST API.
MarkLogic’s REST API allows you to create, read, update, and delete documents (CRUD), as well as search documents and perform analytics on the values they contain. The REST API gives you the building blocks you need for a faceted search application’s data layer, using your language of choice (e.g., Ruby, Python, PHP, etc.). For purposes of this tutorial, you’ll be using the cURL command-line utility to interactively learn the REST API. If you have a Windows OS, we recommend you use Cygwin to make sure the cURL commands run as-is.
Set Up
To create a REST-based application using MarkLogic, you first need three things:
- a database,
- a RESTful application server (called a “REST API instance”), and
- some users with the appropriate privileges.
You’ll create each of these in this section.
This tutorial assumes the following configuration. You can use different values than these; you’ll just have to modify each example accordingly:
- REST host —
localhost - REST port —
8011 - rest-writer user —
rest-writer - rest-writer password —
x - rest-admin user —
rest-admin - rest-admin password —
x
Install MarkLogic
This tutorial assumes you already have MarkLogic installed locally and that a user with the credentials of admin/admin is provided with an admin role. Check out the Installation Guide for detailed instructions.
Create a REST API instance
The setup steps require certain privileges. To run these steps we will use the “admin” user you created when you installed MarkLogic. This tutorial assumes that your admin user’s password is “admin” — hopefully you picked something more secure; adjust the commands below to use your password.
We’ll use cURL to send commands to the Management API. Any other tool that can send HTTP requests is fine, too. Notice that the Management API is on port 8002.
Conveniently, MarkLogic comes with a built-in application server. HTTP application servers can be set up with default REST API capabilities. The following command creates one on port 8011. It also creates a content database called “TutorialDB” and a modules database called “Tutorial-Modules”. The command also automatically creates and attaches forests for each of these as well.
curl -v -X POST --anyauth -u admin:admin \
--header "Content-Type:application/json" \
-d '{"rest-api": { "name": "TutorialServer", "port": "8011", "database": "TutorialDB", "modules-database": "Tutorial-Modules" } }' \
'http://localhost:8002/v1/rest-apis'
Create REST users
MarkLogic has a powerful and flexible security system. Before you can run the tutorial examples, you’ll first need to create a user with the appropriate execute privileges. You of course could use the “admin” user (which has no security restrictions), but as a best practice, we’re going to create two users:
- one with the “rest-writer” role, and
- one with the “rest-admin” role.
(There is also a “rest-reader” role available, which provides read-only access to the REST API, but we won’t be using that.)
Once again, the Management API provides the functionality that we need.
curl -v -X POST --anyauth -u admin:admin \
--header "Content-Type:application/json" \
-d '{"user-name":"rest-writer", "password": "x", "role": ["rest-writer"]}' \
'http://localhost:8002/manage/v2/users'
curl -v -X POST --anyauth -u admin:admin \
--header "Content-Type:application/json" \
-d '{"user-name":"rest-admin", "password": "x", "role": ["rest-admin"]}' \
'http://localhost:8002/manage/LATEST/users'
You can verify that your new users exist by going to http://localhost:8002/manage/v2/users in a browser window.
MarkLogic Basics
The basic unit of organization in MarkLogic is the document. Documents can occur in one of four formats:
- XML
- JSON
- text
- binary
Each document is identified by a URI, such as “/example/foo.json” or “bar.xml” or “baz”, which is unique within the database. The suffix does not affect, nor reflect, the content of the document, but is often used for readability.
Organizing documents
Documents can be grouped into directories via URI. For example, the document with the URI “/docs/plays/hamlet.xml” resides in the “/docs/plays/” directory. As with files on a filesystem, a document can only belong to one directory. It is important to note that this “directory” is not present in the actual filesystem.
Documents can also be grouped (independently of their URI) into collections. A collection is essentially a tag (string) associated with the document. A document can have any number of collection tags associated with it. Collections represent one kind of metadata that can be associated with documents.
Rest API Basics
While the REST API exposes a number of endpoints, this tutorial focuses on the following five endpoints:
| Endpoint | What you can do with it |
|---|---|
/documents |
Manage document content and metadata |
/search |
Search using a string-based or structured query |
/values |
Retrieve values and aggregates of values |
/config/query |
Create or update stored configuration options for/search and /values |
For the full list of endpoints, see the Client API reference.
The version of the API (v1or LATEST) appears as a prefix to the endpoint. For example, to search for “apple” across all documents, you’d make a GET request to:
http://localhost:8011/LATEST/search?q=apple
Since you haven’t loaded any documents yet, this search will yield an empty result. If you click the link, you’ll see the (empty) results are in XML format. You also have the option of getting the results in JSON format instead:
http://localhost:8011/LATEST/search?q=apple&format=json
This is true for all five of the above endpoints. You can use the format parameter to indicate which format you want the results in—json or xml (the default).
You could also make the above request using cURL (or wget), specifying the user and password on the command line. Copy and paste the following command and run it at the command line:
curl -X GET \ --anyauth --user rest-writer:x \ 'http://localhost:8011/LATEST/search?q=chicken&format=json'
We will be giving cURL examples for PUT, POST, and DELETE requests in this tutorial. For GET requests, we’ll often just show the link itself since the browser makes it convenient.
CRUD
To manage documents, you use the /documents endpoint. In the normal manner of a RESTful interface, you use the corresponding HTTP method:
| Task | HTTP method |
|---|---|
| Create or update one document | PUT |
| Create or update multiple documents | POST |
| Read | GET |
| Delete | DELETE |
| Update a part of one document | PATCH |
| Check for existence of a document | HEAD |
In addition, you can use a HEAD request to retrieve just the HTTP headers that a GET would give you.
Create a JSON document
Let’s get started by loading a JSON document into the database. Run the following command to load a simple JSON document into the database at the URI /example/recipe.json:
curl -v -X PUT \
--digest --user rest-writer:x \
-d'{"recipe": {"name" :"Apple pie", "fromScratch":true, "ingredients":"The Universe"}}' \
'http://localhost:8011/LATEST/documents?uri=/example/recipe.json'
Since we didn’t specify a content type (which we could do with a Content-Type header or with the format=json URL parameter), MarkLogic automatically infers “application/json” based on the default mimetype mapping for URIs ending with “.json”.
Read a JSON document
To confirm that the document has been loaded, GET it using this URL:
http://localhost:8011/LATEST/documents?uri=/example/recipe.json
You can also see that the document is loaded since you will now get search results for “apple”:
http://localhost:8011/LATEST/search?q=apple&format=json
Update a document
To update a document, use exactly the same method as when creating a document (HTTP PUT; see above). The only difference will be in the response (“204 Content Updated” instead of “201 Document Created”).
Alternatively, we could “patch” a document instead and supply only the change that we need to do, instead of submitting the entire document:
curl -v -X PATCH \
--digest --user rest-writer:x \
-d '{"patch":[{"replace-insert":{"select":"extraIngredients","context":"/recipe","content":{"extraIngredients":"awesomenessess"}}}]}' \
'http://localhost:8011/LATEST/documents?uri=/example/recipe.json&format=json'
More information about partial updates are available in the REST Application Developer’s Guide.
Create an XML document
Run the following command to insert an XML document into the database:
curl -v -X PUT \ --digest --user rest-writer:x \ -d'<person><first>Carl</first><last>Sagan</last></person>' \ 'http://localhost:8011/LATEST/documents?uri=/example/person.xml'
Since PUT commands are idempotent, the result of running the command more than once is the same as if you had only run it once.
Read an XML document
To read the document you just loaded, make a simple GET request:
http://localhost:8011/LATEST/documents?uri=/example/person.xml
Create a text document (with metadata)
Inserting a text document is similar, except that you specify the content type as “text/plain”. Regardless of the content type, you can also associate a new document with a collection tag, using the collection parameter. Run the following command:
curl -v -X PUT \ --digest --user rest-writer:x \ -d'This is a text file.' \ -H "Content-type: text/plain" \ 'http://localhost:8011/LATEST/documents?uri=/foo.txt&collection=examples&collection=mine'
The above request creates the text document and associates it with both the “examples” and “mine” collection tags. Recall that collections are just tags, so they don’t need to already exist for you to start using them.
Read a document’s metadata
To confirm that the document you just inserted is in those collections, GET the metadata for the document by using the category parameter with a value of “collections”:
http://localhost:8011/LATEST/documents?uri=/foo.txt&category=collections&format=json
You can also view all of the document’s metadata by specifying “metadata” instead of “collections”:
http://localhost:8011/LATEST/documents?uri=/foo.txt&category=metadata&format=json
See Working with Metadata for full details on the metadata categories and formats.
Create a binary document (with metadata extracted)
There are four kinds of metadata that can be associated with a document:
- collections,
- permissions,
- quality, and
- properties.
Permissions associate roles (such as “rest-writer”) with privileges (such as “update”) for the document. Quality is a signed integer that can be used to boost or reduce a document’s ranking in search results. Properties are arbitrary name/value pairs that you can associate with a document, outside of and in addition to its actual content.
In the next example, you’ll associate a new document with some properties.
Run the following cURL commands. The first downloads a sample image file. The second inserts it into MarkLogic. Since this is a binary document, MarkLogic can automatically extract metadata from it, storing it in the resulting document’s properties. To specify this behavior, you use the extract parameter:
curl http://developer.marklogic.com/media/learn/rest/mlfavicon.png >mlfavicon.png curl -v -X PUT \ --digest --user rest-writer:x \ --data-binary '@mlfavicon.png' \ -H "Content-type: image/png" \ 'http://localhost:8011/LATEST/documents?uri=/example/mlfavicon.png&extract=properties'
To see the resulting properties, make a GET request, setting the category parameter to “properties” (this time using the default XML format):
http://localhost:8011/LATEST/documents?uri=/example/mlfavicon.png&category=properties
You can also specify properties explicitly using the prop:name parameter. For example, to insert a document having a property named “favorite” with a value of “yes”, you would append prop:favorite=yes to the URL.
The REST API provides flexible ways of working with metadata. In addition to specifying metadata using request parameters, you can upload metadata as the body of a PUT request, update only individual property values, or even upload and download document content and metadata together, using multipart/mixed content. For full details, see Manipulating Documents in the REST Application Developer’s Guide.
Delete a document
Run the following command to delete the text document using the HTTP DELETE method:
curl -v -X DELETE \ --digest --user rest-writer:x \ 'http://localhost:8011/LATEST/documents?uri=/foo.txt'
To verify the document has been deleted, try requesting it using GET:
http://localhost:8011/LATEST/documents?uri=/foo.txt
It will return an error that the document does not exist. Alternatively, you could delete documents in bulk. This is possible only if the items you are deleting can be grouped using collection and/or directories:
curl -v -X DELETE --digest --user rest-writer:x 'http://localhost:8011/LATEST/search?collection=delete'
The format of error messages is either XML or JSON, depending on the “error-format” property for your REST API instance. See Error Reporting in the REST Application Developer’s Guide.
Bulk-load documents from a script
In preparation for the search and query examples in the next section, let’s populate the database with more data, including a bunch of JSON, XML, and image files. The JSON documents describe talks from a prior MarkLogic World conference; the XML consists of a set of Shakespeare plays (associated with the “shakespeare” collection on load); and the images are photos with embedded metadata.
Download the following zip file containing the documents: rest-api-tutorial.zip. Unzip the file and run the load.sh shell script (first editing the host/port/user/pass as necessary in scripts.conf). This will load all the documents into the database using the REST API and cURL.
For loading larger amounts of data, check out MarkLogic Content Pump, which provides a number of capabilities to efficiently load data, including splitting some types of files into multiple documents.
Basic Search
Now that we’ve populated our database, let’s start taking advantage of MarkLogic’s real power: search/query. What’s the difference between search and query? For MarkLogic, there’s no difference except in how we use the terms. A query is a search specification, and a search is the execution of a query.
String and structured queries are executed using the /search endpoint. We can also look for content using an example of what we want to find, using the /qbe endpoint (Query By Example).
Find JSON documents by example
Start by finding all the conference talks by speakers who work for MarkLogic-—in other words, all the JSON documents that have this key/value pair: {“affilliation”: “MarkLogic”}. To do that, you use the /qbe endpoint:
http://localhost:8011/LATEST/qbe?query={affiliation:%22MarkLogic%22}&format=json
You can also get the results back in XML format:
http://localhost:8011/LATEST/qbe?query={affiliation:%22MarkLogic%22}&format=xml
Regardless of which format you choose, the results include references to, and snippets of, the first ten matching JSON documents.
Find XML documents by example
You can also search by element value using the /qbe endpoint. Here, you’re searching for all Shakespeare plays that feature the King of France:
- http://localhost:8011/LATEST/qbe?query=%3CPERSONA%3EKING%20OF%20FRANCE%3C/PERSONA%3E&format=xml (XML)
- http://localhost:8011/LATEST/qbe?query=%3CPERSONA%3EKING%20OF%20FRANCE%3C/PERSONA%3E&format=json (JSON)
If your XML documents use namespaces (unlike our sample Shakespeare docs), then you’ll first need to use the /config/namespaces endpoint to configure a namespace prefix binding.
Find documents using a search string
Now let’s use the /search endpoint to perform a string search using the q parameter:
- http://localhost:8011/LATEST/search?q=index+OR+Cassel+NEAR+Hare&format=xml (XML)
- http://localhost:8011/LATEST/search?q=index+OR+Cassel+NEAR+Hare&format=json (JSON)
In either format, the search returns the first ten results, each of which includes snippets of text that matched the query.
In a real-world search application, you’d often insert user-supplied text in the query (what the user types in the search box). In this case, the string query is “index OR Cassel NEAR Hare“. This will find documents (regardless of format) that either contain the word “index” or have the word “Cassel” appearing near the word “Hare”. More information about this “search grammar” is available in the Search Developer’s Guide. What this illustrates is that even a “simple search” can be quite powerful using MarkLogic’s default search configuration (which are called search options). Later on, we’ll see a couple examples of how to customize search options.
Get another page of search results
All the previous examples returned the first ten most relevant results. Now let’s get the third five most relevant results. In other words, let’s use a smaller page size (five results per page) and ask for the third page of results. Use the pageLength parameter to override the default size (10), and the start parameter to indicate the index of the first result to return:
- http://localhost:8011/LATEST/qbe?query={affiliation:%22MarkLogic%22}&pageLength=5&start=11&format=xml (XML)
- http://localhost:8011/LATEST/qbe?query={affiliation:%22MarkLogic%22}&pageLength=5&start=11&format=json (JSON)
Now the search results yield a maximum page size of five, starting at the 11th result (effectively the third page).
Find documents based on their properties
You’ve now seen string-based queries and QBE queries. One example of a structured query (the third kind of query) is what you need for searching properties (at least without defining a constraint option, which we’ll be doing in the next section). To use a structured query, you POST it using either JSON or XML format. Copy, paste, and execute the following command:
curl -v -X POST \
--digest --user rest-writer:x \
-d'{"query":{"properties-query":{"term-query":{"text":"fish"}}}}' \
-H "Content-type: application/json" \
'http://localhost:8011/LATEST/search?format=json'
The above command uses a JSON-based structured query to find all photos of fish (searching the extracted image metadata for “fish”). Here’s the same query using the XML format:
curl -v -X POST \ --digest --user rest-writer:x \ -d'<query xmlns="http://marklogic.com/appservices/search"><properties-query><term-query><text>fish</text></term-query></properties-query></query>' \ -H "Content-type: application/xml" \ 'http://localhost:8011/LATEST/search'
You can also do this with a GET request, using the structuredQuery parameter with the (URL-encoded) structured query in either XML or JSON:
This example hints at the richness of the query language as well as the complexity that string queries hide for you, using the default search grammar. For more details, see Using Structured Search in the Search Developer’s Guide.
Search within a directory
To search within a directory, use the directory parameter. Since the q parameter is absent, the following search will find all documents in the given directory:
- http://localhost:8011/LATEST/search?directory=/images/2012/02/14/&format=xml (XML)
- http://localhost:8011/LATEST/search?directory=/images/2012/02/14/&format=json (JSON)
Search within a collection
Similarly, the collection parameter restricts a search to a particular collection. This query finds all mentions of “flower” in the “shakespeare” collection:
- http://localhost:8011/LATEST/search?q=flower&collection=shakespeare&format=xml (XML)
- http://localhost:8011/LATEST/search?q=flower&collection=shakespeare&format=json (JSON)
We’ve now seen how to perform some basic searches. Now let’s look more closely at the results format.
Understanding search results
As you’ve seen, you have a choice between XML and JSON when it comes to search results. Whichever format you choose, the results provide the data needed to construct a search application. For example, you could use the following excerpted JSON data:
{
"total": 95,
"start": 1,
"page-length": 10
}
to construct a search results pagination widget (as on this website’s search results page):
![]()
Then, you would iterate through each of the objects in the results array:
"results": [
{
"index": 1,
"uri": "/guide/search-dev.xml",
"path": "fn:doc(\"/guide/search-dev.xml\")",
"score": 92032,
"confidence": 0.672178,
"fitness": 0.877356,
"matches": [
{
"path": "fn:doc(\"/guide/search-dev.xml\")/*:guide/*:para[5]",
"match-text": [
"Lexicon and ",
{
"highlight": "Range Index"
},
"-Based APIs..."
},
{
"path": "fn:doc(\"/guide/search-dev.xml\")/*:guide/*:para[20]",
"match-text": [
"no matter what the database size. As part of loading a document, full-text ",
{
"highlight": "indexes"
},
"are created making arbitrary searches fast. Searches automatically use the"
}
]
}
]
to produce the contents of your search results page:
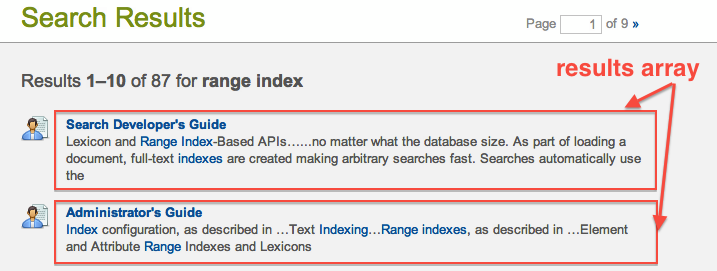
In addition to the document’s score, URI, etc., each result includes a matches array which contains one object for each matching area of text:
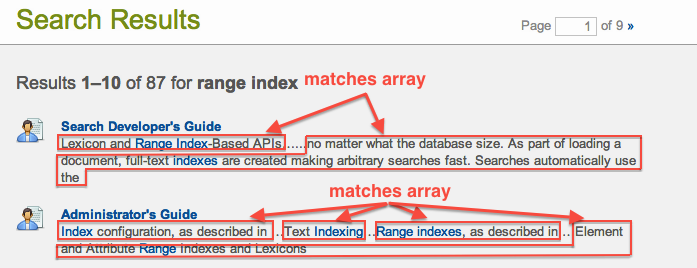
And within each match is a match-text array, which is a list of strings which may or may not be highlighted (highlighted when they contain the actual matching term or terms):
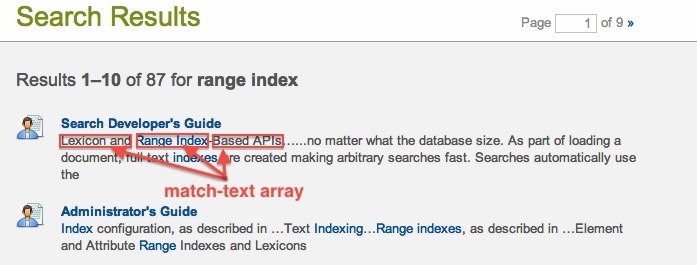
The XML version of the results is generally isomorphic to the JSON version. In place of the results, matches, and match-text arrays are the <search:result>, <search:snippet>/<search:match>, and <search:highlight> elements, respectively:
<!--...-->
<result index="1" uri="/guide/search-dev.xml" path="fn:doc("/guide/search-dev.xml")" score="92032" confidence="0.672178" fitness="0.877356">
<snippet>
<match path="fn:doc("/guide/search-dev.xml")/*:guide/*:para[5]">Lexicon and <highlight>Range Index</highlight>-Based APIs...</match>
<match path="fn:doc("/guide/search-dev.xml")/*:guide/*:para[20]">no matter what the database size. As part of loading a document,
full-text <highlight>indexes</highlight> are created making
arbitrary searches fast. Searches automatically use the</match>
</snippet>
</result>
<!--...-->
The above excerpt of XML results corresponds to the same data as the JSON results we saw.
Custom search
All of the search examples so far in this tutorial have used MarkLogic’s default query options (interchangeably called “search options”). This may suffice for some basic applications, but most of the time you will end up wanting to provide custom options. Custom options let you do things like:
- define named constraints, which can be used in string queries, such as “tag” in “flower tag:shakespeare”
- enable analytics and faceting by identifying lexicons and range indexes from which to retrieve values
- customize the structure of the search results, including snippeting and default pagination
- control search options such as case sensitivity and ordering
Options are grouped into named option sets on your REST API server. You can customize these either by updating the default option set, or by creating a new named option set.
Get a list of the server’s option sets
To see a list of all your server’s option sets, make a GET request to the /config/query endpoint:
- http://localhost:8011/LATEST/config/query?format=xml (XML)
- http://localhost:8011/LATEST/config/query?format=json (JSON)
If you haven’t added any custom options yet, then you’ll see an empty option set: [ ]
A ‘default’ option set is in effect; this may have been more obvious in versions of MarkLogic prior to Version 10. It’s configuration is visible using this REST endpoint:
- http://localhost:8011/LATEST/config/query/default?format=xml (XML)
- http://localhost:8011/LATEST/config/query/default?format=json (JSON)
Whenever you run a search without explicitly specifying an option set (using the options request parameter), this is the option set that will be in effect.
Upload custom search options
Only users with the “rest-admin” role can update option sets. Until now, all the examples in this tutorial have used the “rest-writer” user to connect to MarkLogic. Now, whenever you need to update options, you’ll connect with the “rest-admin” user instead.
Let’s start by building a constraint option. Constraint means something very specific in MarkLogic. Whenever a user types a phrase of the form name:text in their search string, they’re using a constraint (assuming one has been defined for them). For example, they might type “author:melville” to constrain their search to documents with an author element or property with the value “melville”, as opposed to a search for the term anywhere.. But for this to have the intended behavior, a constraint named “author” must first be defined in the server’s query options. For this tutorial, you’re going to define a constraint that enables users to type things like “tag:shakespeare” and “tag:mlw12”.
To create or replace an entire option set, use the PUT method against /config/query/yourOptionsName:
curl -v -X PUT \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"tag","collection":{"prefix":""}}]}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
The above command connects as the rest-admin user and uploads a JSON-based options configuration named “tutorial”. The option set defines one constraint named “tag”:
{
"options": {
"constraint": [
{
"collection": {
"prefix": ""
},
"name": "tag"
}
]
}
}
There are a number of different kinds of constraints. In this case, you’re using a “collection constraint”. The “prefix” field is an optional collection tag prefix, which would be handy if you wanted to power multiple constraints via collection tags such as “author/shakespeare” and “state/california” using the prefixes “author/” and “state/”, respectively. In this case, you’re not doing that; you just want to constrain by the whole collection tag, so you pass an empty prefix (“”).
You can see what the stored options look like by retrieving the newly-created option set: http://localhost:8011/LATEST/config/query/tutorial. Add the “format=json” parameter to see the options in that format.
For syntax details, see Appendix: Query Options Reference in the Search Developer’s Guide.
Confirm that your option set is now available by getting the list again:
- http://localhost:8011/LATEST/config/query?format=xml (XML)
- http://localhost:8011/LATEST/config/query?format=json (JSON)
You should now see your recently created option settutorial.
Search using a collection constraint
Now you’ll make use of the new configuration and run a search using the “tag” constraint. To do that, call /search with the options parameter:
- http://localhost:8011/LATEST/search?q=flower+tag:shakespeare&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/search?q=flower+tag:shakespeare&options=tutorial&format=json (JSON)
The above query searches for occurrences of “flower” in the “shakespeare” collection.
Search using a JSON key value constraint
The rest of the examples in this section include two steps:
- Update the server configuration
- Run a query making use of the updated configuration
You’re going to keep using the “tutorial” options set, but rather than replacing it each time using PUT, you’re going to incrementally add to it, using POST, which will append to the server’s options. Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"company","value":{"json-property":"affiliation"}}]}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
View the options to confirm that you’ve appended to (rather than replaced) them:
- http://localhost:8011/LATEST/config/query/tutorial (XML)
- http://localhost:8011/LATEST/config/query/tutorial?format=json (JSON)
The command you ran above defined a JSON key value constraint called “company”, backed by the “affiliation” JSON key. You can define these options using either JSON or XML:
{
"options": {
"constraint": [
{
"name": "company",
"value": {
"json-property": "affiliation"
}
}
]
}
}
Since this is a value constraint, the searched-for value must match the affiliation exactly.
Run the following search to find all conference talks given by MarkLogic employees and mentioning the word “engineer”, making use of our newly-defined “company” constraint:
- http://localhost:8011/LATEST/search?q=engineer+company:marklogic&options=tutorial (XML)
- http://localhost:8011/LATEST/search?q=engineer+company:marklogic&options=tutorial&format=json (JSON)
Search using an element value constraint
Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"person","value":{"element":{"name":"PERSONA","ns":""}}}]}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
Here we’re defining another value constraint but against an element this time (<PERSONA>) instead of a JSON key. Here’s the representation of the constraint:
{
"options": {
"constraint": [
{
"name": "person",
"value": {
"element": {
"name": "PERSONA",
"ns": ""
}
}
}
]
}
}
Now you can search for the King of France directly in your query text, using the new “person” constraint:
- http://localhost:8011/LATEST/search?q=person:%22king+of+france%22&options=tutorial (XML)
- http://localhost:8011/LATEST/search?q=person:%22king+of+france%22&options=tutorial&format=json (JSON)
Search using a JSON key word constraint
Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"bio","word":{"json-property":"bio"}}]}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
Here, instead of a value constraint, we’re using a word constraint scoped within all JSON “bio” keys:
{
"options": {
"constraint": [
{
"name": "bio",
"word": {
"json-property": "bio"
}
}
]
}
}
Unlike a value constraint (which tests for the value of the key or element), a word constraint uses normal search-engine semantics. The search will succeed if the word is found anywhere in the given context.
Now let’s use the “bio” constraint to find all bios mentioning “strategy”:
- http://localhost:8011/LATEST/search?q=bio:strategy&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/search?q=bio:strategy&options=tutorial&format=json (JSON)
Search using an element word constraint
Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"stagedir","word":{"element":{"name":"STAGEDIR","ns":""}}}]}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
This time you’re using a word constraint against the <STAGEDIR> element:
{
"options": {
"constraint": [
{
"name": "stagedir",
"word": {
"element": {
"name": "STAGEDIR",
"ns": ""
}
}
}
]
}
}
Now we can find all the Shakespeare plays where, for example, swords are involved on stage:
- http://localhost:8011/LATEST/search?q=stagedir:sword&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/search?q=stagedir:sword&options=tutorial&format=json (JSON)
Scoping search using a container constraint
Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"spoken","container":{"element":{"ns":"","name":"SPEECH"}}}]}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
Here we’re defining a container constraint:
{
"options": {
"constraint": [
{
"name": "spoken",
"container": {
"element": {
"ns": "",
"name": "SPEECH"
}
}
}
]
}
}
A container constraint is similar to a word constraint, except that it will match words in the element and any of its descendants. For example, it will match text in <LINE> element children of <SPEECH>. This is useful for searching documents that contain “mixed content” (i.e. text mixed with markup, such as <em> and <strong>).
You can use `json-property` instead of `element` for JSON documents. More information about container constraints are available in the Query Options Reference of the Search Developer’s Guide.
Using this constraint will restrict the search to the spoken lines of text (excluding, for example, stage directions). This will search for mentions of “sword” in the script itself:
- http://localhost:8011/LATEST/search?q=spoken:sword&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/search?q=spoken:sword&options=tutorial&format=json (JSON)
Search using a properties constraint
We can also create a constraint for searching document properties. Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"image","properties":null}]}}' \
'http://localhost:8011/v1/config/query/tutorial'
Document and directory properties are not included in searches by default. The properties constraint enables us to search a document’s properties metadata. In our case, our images have their metadata extracted during ingest and stored as document properties:
- http://localhost:8011/LATEST/documents?uri=/images/2012/02/27/20120227-154053.jpg&category=properties (XML)
- http://localhost:8011/LATEST/documents?uri=/images/2012/02/27/20120227-154053.jpg&category=properties&format=json (JSON)
Our properties constraint allows us to perform word search on these data:
{
"options": {
"constraint": [
{
"name": "image",
"properties": null
}
]
}
}
If we specified an entry for ‘properties’, then our word search will only apply to that document property. Supplying null allows us to search through all of them.
Now it’s easy for a user to search for photos of fish (or anything else):
- http://localhost:8011/LATEST/search?q=image:%22parrot%20fish%22&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/search?q=image:%22parrot%20fish%22&options=tutorial&format=json (JSON)
To be specific, our search matched the following document property:
<xmp_dc_title xmlns="http://marklogic.com/filter">Parrot Fish</xmp_dc_title>
Search using a structured query
We’ve seen how the REST API supports two kinds of queries, both using the /search endpoint:
- string queries
- structured queries
We briefly touched on a structured query for searching properties. Now we’ll take a look at a richer use of it, utilizing the constraints we’ve defined in the “tutorial” options set.
Here we’re going to build up a complex set of criteria. It will find documents:
- Matching any of (OR query):
- Matching all of (AND query):
- bio:product
- company:MarkLogic
- Matching all of (AND query):
- spoken:fie
- stagedir:fall
- person:GRUMIO
- Matching all of (AND query):
- documents whose properties contain “fish”
- documents in the “/images/2012/02/27/” directory
- Matching all of (AND query):
- documents in the “mlw2012” collection
- documents containing the term “fun”
- Matching all of (AND query):
Complex queries like this can be expressed as search strings, but to construct and manipulate them programmatically, it can more convenient to use a structured query. Here’s the above structured query expressed in JSON format:
{"query":
{"or-query":
{"queries":[
{"and-query":
{"queries":[
{"word-constraint-query":
{"constraint-name":"bio",
"text":["product"]}},
{"value-constraint-query":
{"constraint-name":"company",
"text":["MarkLogic"]}}]}},
{"and-query":
{"queries":[
{"element-constraint-query":
{"constraint-name":"spoken",
"and-query":
{"queries":[
{"term-query":
{"text":["fie"]}}]}}},
{"word-constraint-query":
{"constraint-name":"stagedir",
"text":["fall"]}},
{"value-constraint-query":
{"constraint-name":"person",
"text":["GRUMIO"]}}]}},
{"and-query":
{"queries":[
{"properties-query":
{"term-query":
{"text":["fish"]}}},
{"infinite":true,
"directory-query":
{"uri":["/images/2012/02/27/"]}}]}},
{"and-query":
{"queries":[
{"collection-query":
{"uri":["mlw2012"]}},
{"term-query":
{"text":["fun"]}}]}}]}}}
An or-query will find documents matching any of its child queries (union). In contrast, an and-query restricts its results to those documents matching all of its child queries (intersection). To run the query, you can include it as POST data:
curl -v -X POST \
--digest --user rest-writer:x \
-H "Content-type: application/json" \ -d'{"query":{"or-query":{"queries":[{"and-query":{"queries":[ {"word-constraint-query":{"constraint-name":"bio","text":["product"]}}, {"value-constraint-query":{"constraint-name":"company","text":["MarkLogic"]}} ]}}, {"and-query":{"queries":[ {"element-constraint-query":{"constraint-name":"spoken","and-query": {"queries":[{"term-query":{"text":["fie"]}}]} }}, {"word-constraint-query":{"constraint-name":"stagedir","text":["fall"]}}, {"value-constraint-query":{"constraint-name":"person","text":["GRUMIO"]}} ]}}, {"and-query":{"queries":[ {"properties-query":{"term-query":{"text":["fish"]}}}, {"directory-query":{"uri":["/images/2012/02/27/"]},"infinite":true} ]}}, {"and-query":{"queries":[ {"collection-query":{"uri":["mlw2012"]}}, {"term-query":{"text":["fun"]}} ]}}]}}}' \
'http://localhost:8011/LATEST/search?options=tutorial'
Or as the value of the (URL-encoded) structuredQuery parameter in a GET request: http://localhost:8011/LATEST/search?options=tutorial&structuredQuery=…
Note that the search will only give you the expected results if you’ve previously defined the “bio”, “company”, “spoken”, “stagedir”, and “person” constraints (see previous examples in this section).
Alternatively, you can define these constraints as part of the payload such that:
curl -v -X POST \
--digest --user rest-writer:x \
-H "Content-type: application/json" \
-d'{"search":{"options":{"constraint":[{"name":"bio","word":{"json-property":"bio"}},{"name":"company","value":{"json-property":"affiliation"}},{"name":"spoken","element-query":{"name":"SPEECH","ns":""}},{"name":"stagedir","word":{"element":{"name":"STAGEDIR","ns":""}}},{"name":"person","value":{"element":{"name":"PERSONA","ns":""}}}]},"query":{"or-query":{"queries":[{"and-query":{"queries":[{"word-constraint-query":{"constraint-name":"bio","text":["product"]}},{"value-constraint-query":{"constraint-name":"company","text":["MarkLogic"]}}]}},{"and-query":{"queries":[{"element-constraint-query":{"constraint-name":"spoken","and-query":{"queries":[{"term-query":{"text":["fie"]}}]}}},{"word-constraint-query":{"constraint-name":"stagedir","text":["fall"]}},{"value-constraint-query":{"constraint-name":"person","text":["GRUMIO"]}}]}},{"and-query":{"queries":[{"properties-query":{"term-query":{"text":["fish"]}}},{"directory-query":{"uri":["/images/2012/02/27/"]},"infinite":true}]}},{"and-query":{"queries":[{"collection-query":{"uri":["mlw2012"]}},{"term-query":{"text":["fun"]}}]}}]}}}}' \
'http://localhost:9011/LATEST/search'
Here is a better presentation of the payload:
{
"search": {
"options": {
"constraint": [{
"name": "bio",
"word": {
"json-property": "bio"
}
}, {
"name": "company",
"value": {
"json-property": "affiliation"
}
}, {
"name": "spoken",
"element-query": {
"name": "SPEECH",
"ns": ""
}
}, {
"name": "stagedir",
"word": {
"element": {
"name": "STAGEDIR",
"ns": ""
}
}
}, {
"name": "person",
"value": {
"element": {
"name": "PERSONA",
"ns": ""
}
}
}
]
},
"query": {
"or-query": {
"queries": [{
"and-query": {
"queries": [{
"word-constraint-query": {
"constraint-name": "bio",
"text": ["product"]
}
}, {
"value-constraint-query": {
"constraint-name": "company",
"text": ["MarkLogic"]
}
}
]
}
}, {
"and-query": {
"queries": [{
"element-constraint-query": {
"constraint-name": "spoken",
"and-query": {
"queries": [{
"term-query": {
"text": ["fie"]
}
}
]
}
}
}, {
"word-constraint-query": {
"constraint-name": "stagedir",
"text": ["fall"]
}
}, {
"value-constraint-query": {
"constraint-name": "person",
"text": ["GRUMIO"]
}
}
]
}
}, {
"and-query": {
"queries": [{
"properties-query": {
"term-query": {
"text": ["fish"]
}
}
}, {
"directory-query": {
"uri": ["/images/2012/02/27/"]
},
"infinite": true
}
]
}
}, {
"and-query": {
"queries": [{
"collection-query": {
"uri": ["mlw2012"]
}
}, {
"term-query": {
"text": ["fun"]
}
}
]
}
}
]
}
}
}
}
Notice how we no longer supply `&options=tutorial` in the URL and we include `options` properties in the payload.
More information about dynamic query options and combining them with structured query is available in the REST Application Developer’s Guide.
For more details on what structures are allowed in both the XML and JSON representations of structured queries, see Structured Search XML Node and JSON Keys in the Search Developer’s Guide.
For more details on the kinds of constraints you can define, see “Constraint Options” in the Search Developer’s Guide.
Analytics
“Analytics” is used to describe a class of functionality in MarkLogic that relates to retrieving values and frequencies of values across a large number of documents. With search/query, we’re interested in finding documents themselves. With analytics, we’re interested in extracting all the unique values that appear within a particular context (such as an XML element or JSON property), as well as the number of times each value occurs. An example of analytics in a MarkLogic application is the message traffic chart on MarkMail.org:
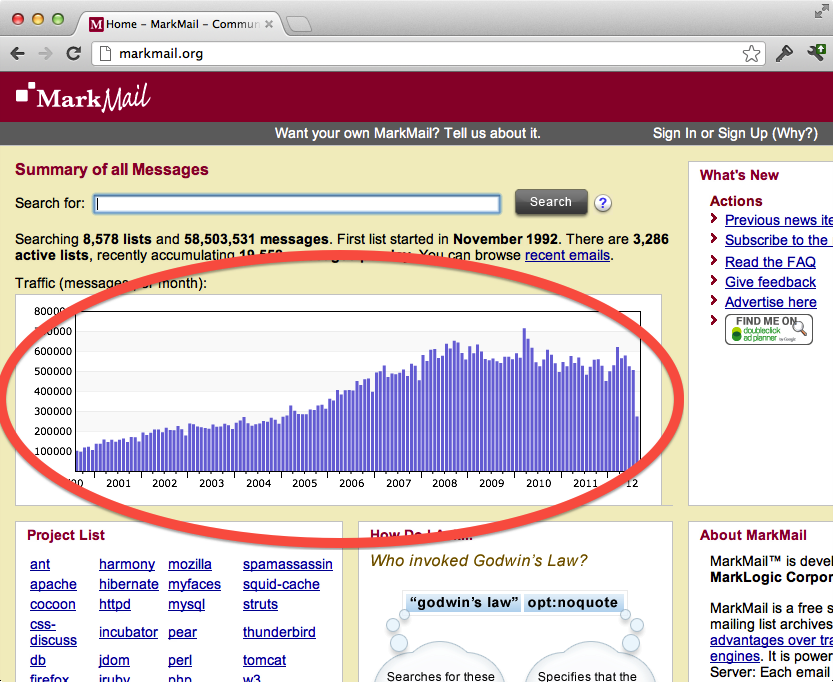
The above chart portrays ranges of email message dates bucketed by month, as well as the number of messages that appear each month. Since MarkMail hosts over 50 million messages, it of course does not go read all those messages when you load the page. Instead, whenever a new document (email message) is loaded into the database, its date is added to a sorted, in-memory list of message dates (values), each associated with a count (frequency). This is achieved through an administrator-defined index (called a range index).
A range index is one kind of lexicon. Whenever you want to perform analytics, you need to have a lexicon configured. In addition to range indexes, other lexicons include the URI lexicon, the collection lexicon, and word lexicon (useful for creating word clouds). Each of these must be explicitly configured in the database.
Retrieve all collection tags
For this example, you need to have the collection lexicon enabled. Fortunately, collection lexicon is enabled by default. Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"values":{"name":"tag","collection":{"prefix":""}}}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
This option exposes the database’s collection tags as a set of values we’re naming “tag”:
{
"options": {
"values": {
"name": "tag"
"collection": {
"prefix": ""
}
}
}
}
<options xmlns="http://marklogic.com/appservices/search">
<values name="tag">
<collection prefix=""/>
</values>
</options>
The name of the values option is the name we’ll be using when we fetch the values (“tag”). The child of the values option defines the source of those values. In this case, “collection” indicates the collection lexicon as the source.
Now that you’ve configured the values, retrieve them using a GET request using the /values/name endpoint:
- http://localhost:8011/LATEST/values/tag?options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/values/tag?options=tutorial&format=json (JSON)
The results show all the distinct values of collection tags and their frequency of usage (in other words, how many documents are in each collection):
{
"values-response": {
"metrics": {
"aggregate-resolution-time": "PT0.000017S",
"total-time": "PT0.001675S",
"values-resolution-time": "PT0.000189S"
},
"distinct-value": [
{
"_value": "mlw2012",
"frequency": 88
},
{
"_value": "photos",
"frequency": 140
},
{
"_value": "shakespeare",
"frequency": 22
}
],
"type": "xs:string",
"name": "tag"
}
}
<values-response name="tag" type="xs:string" xmlns="http://marklogic.com/appservices/search">
<distinct-value frequency="88">mlw2012</distinct-value>
<distinct-value frequency="140">photos</distinct-value>
<distinct-value frequency="22">shakespeare</distinct-value>
<metrics>
<values-resolution-time>PT0.000195S</values-resolution-time>
<aggregate-resolution-time>PT0.000017S</aggregate-resolution-time>
<total-time>PT0.001873S</total-time>
</metrics>
</values-response>
Retrieve all document URIs
This example requires the URI lexicon to be enabled. It’s enabled by default since MarkLogic 6, so again we’re ready to go. This example is almost identical to the previous one except that we’re choosing a different values name (“uri”) and a different values source (the URI lexicon):
curl -v -X POST \ --digest --user rest-admin:x \ -H "Content-type: application/xml" \ -d'<options xmlns="http://marklogic.com/appservices/search"><values name="uri"><uri/></values></options>' \ 'http://localhost:8011/LATEST/config/query/tutorial'
The uri element or property indicates the URI lexicon as the source:
{
"options": {
"values": {
"name": "uri",
"uri": null
}
}
}
<options xmlns="http://marklogic.com/appservices/search">
<values name="uri">
<uri/>
</values>
</options>
Retrieve the values using a GET request:
- http://localhost:8011/LATEST/values/uri?options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/values/uri?options=tutorial&format=json (JSON)
This will return all the document URIs in the database, as well as how many documents they’re each associated with (the frequency). For all the JSON and XML document URIs, the answer of course is just one per document. But you might be surprised to see that each image document URI yields a count of two. That’s because each image document has an associated properties document which shares the same URI.
Set up some range indexes
Before we can run the remaining examples in this section, we need to enable some range indexes in our database. Since we have a small number of documents, it won’t take long for MarkLogic to re-index everything. At a much larger scale, you’d want to be careful about what indexes you enable and when you enable them. That’s why such changes require database administrator access.
We’re going to set up the following range indexes:
| Scalar Type | Namespace URI | Local Name |
|---|---|---|
| string | empty | SPEAKER |
| string | empty | affiliation |
| int | empty | contentRating |
| unsignedLong | http://marklogic.com/filter | size |
| string | http://marklogic.com/filter | Exposure_Time |
We’ll configure each of these by sending a PUT request to the Management API, using the /manage/v2/databases/[db name or id]/properties endpoint. When we send information about range element indexes, what we send will replace the current range element index configuration. That means we will send all the desired indexes in one message. To remove an index, we simply send a PUT request with all current indexes except the one we want to remove. Here’s the command to add the indexes we need:
curl -X PUT --anyauth --user admin:admin --header "Content-Type:application/json" \
-d '{"word-positions": true,
"element-word-positions": true,
"range-element-index":
[ { "scalar-type": "string",
"namespace-uri": "",
"localname": "SPEAKER",
"collation": "http://marklogic.com/collation/",
"range-value-positions": false,
"invalid-values": "reject"
},
{ "scalar-type": "string",
"namespace-uri": "",
"localname": "affiliation",
"collation": "http://marklogic.com/collation/",
"range-value-positions": false,
"invalid-values": "reject"
},
{ "scalar-type": "int",
"namespace-uri": "",
"localname": "contentRating",
"collation": "",
"range-value-positions": false,
"invalid-values": "reject"
},
{ "scalar-type": "unsignedLong",
"namespace-uri": "http://marklogic.com/filter",
"localname": "size",
"collation": "",
"range-value-positions": false,
"invalid-values": "reject"
},
{ "scalar-type": "string",
"namespace-uri": "http://marklogic.com/filter",
"localname": "Exposure_Time",
"collation": "http://marklogic.com/collation/",
"range-value-positions": false,
"invalid-values": "reject"
}]}' \
'http://localhost:8002/manage/v2/databases/TutorialDB/properties'
For larger datasets, re-indexing may take some time to complete. Until then, the index will be unusable and MarkLogic will likely throw an error indicating that the index does not exist. The admin database status page may be used to confirm this:
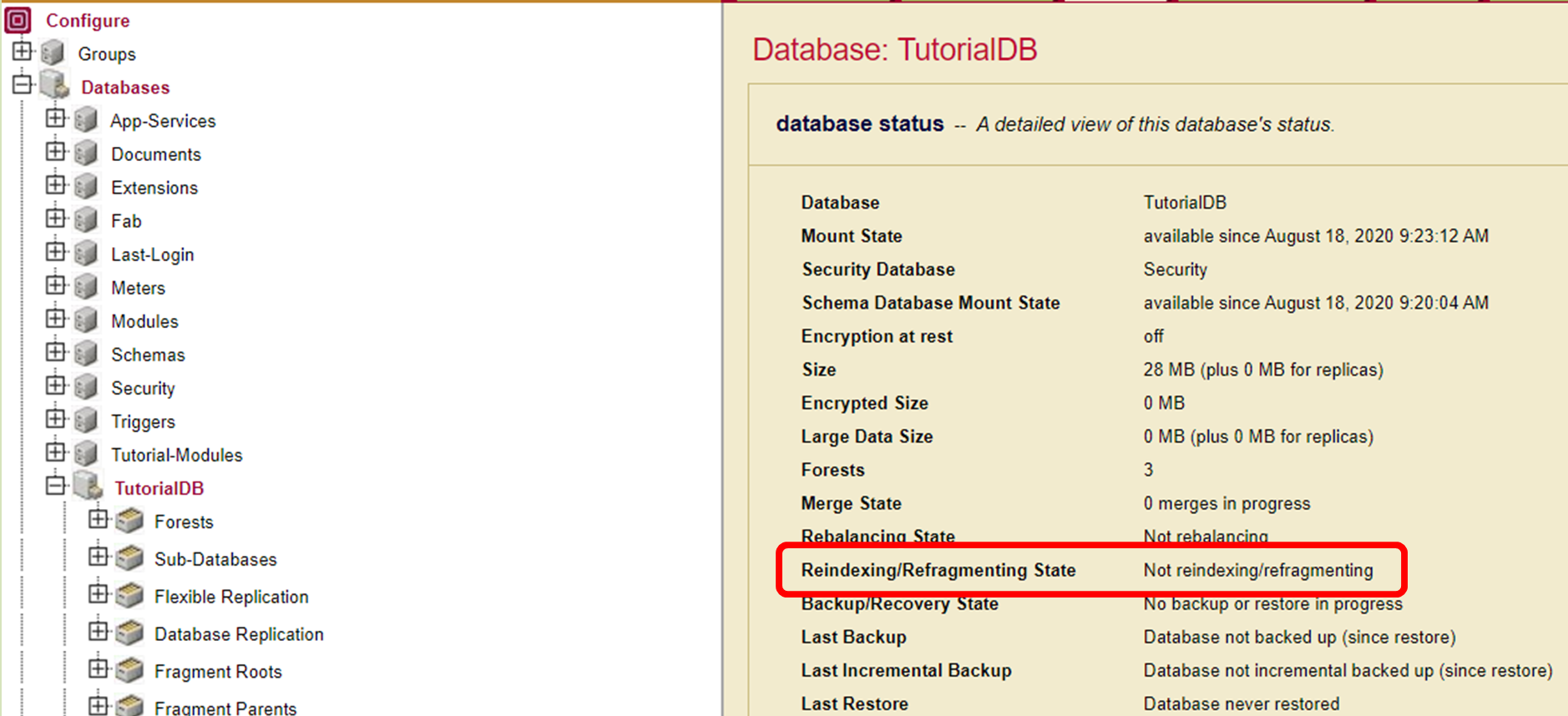
Now that we have the indexes configured, let’s jump back over to the command line.
Retrieve values of a JSON key
We’re now ready to make use of some range indexes. Run the following command:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"values":{"name":"company","range":{"type":"xs:string","collation":"http://marklogic.com/collation/","json-property":"affiliation"},"values-option":["frequency-order"]}}}' \
'http://localhost:8011/v1/config/query/tutorial'
As with collection and URI values, we start by choosing a name (“company”). This time, instead of “uri” or “collection”, we use a “range” field to indicate that a range index is the source of the values. We identify the range index by the name of the JSON key (“affiliation”) and the type of the indexed values (string, using the default collation). Here, we must make sure that the configuration lines up exactly with the range index that’s configured in the database. Otherwise, we’ll get an “index not found” error when we try to retrieve the values.
{
"options": {
"values": {
"name": "company",
"range": {
"collation": "http://marklogic.com/collation/",
"json-property": "affiliation",
"type": "xs:string"
},
"values-option": [
"frequency-order"
]
}
}
}
<options xmlns="http://marklogic.com/appservices/search">
<values name="company">
<range type="xs:string" collation="http://marklogic.com/collation/">
<json-proprety>affiliation</json-property>
</range>
<values-option>frequency-order</values-option>
</values>
</options>
The last thing to point out above is that, rather than return the values in alphabetical (collation) order, we want to get them in “frequency order” (using the corresponding “values-option”). In other words, return the most commonly mentioned companies first. That’s what the “frequency-order” option lets you do.
Retrieve the values by making a GET request:
- http://localhost:8011/LATEST/values/company?options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/values/company?options=tutorial&format=json (JSON)
Unsurprisingly, you’ll see that MarkLogic was the most common company affiliation at the MarkLogic World conference.
Retrieve values of an element
In this example, we’ll using an element range index to indicate the source of our “speaker” values:
{
"options": {
"values": {
"range": {
"collation": "http://marklogic.com/collation/",
"type": "xs:string",
"element": {
"ns": "",
"name": "SPEAKER"
}
},
"name": "speaker",
"values-option": [
"frequency-order"
]
}
}
}
<options xmlns="http://marklogic.com/appservices/search">
<values name="speaker">
<values-option>frequency-order</values-option>
<range type="xs:string" collation="http://marklogic.com/collation/">
<element ns="" name="SPEAKER"/>
</range>
</values>
</options>
Run the following command to upload the values configuration:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"values":{"name":"speaker","range":{"type":"xs:string","collation":"http://marklogic.com/collation/","element":{"name":"SPEAKER","ns":""}},"values-option":["frequency-order"]}}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
To make use of the new “speaker” values, retrieve them using a GET request:
- http://localhost:8011/LATEST/values/speaker?frequency=item&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/values/speaker?frequency=item&options=tutorial&format=json (JSON)
Run the program to see all the unique speakers in the Shakespeare plays, starting with the most garrulous.
Compute aggregates on values
Not only can we retrieve values and their frequencies; we can also perform aggregate math on the server. MarkLogic provides a series of built-in aggregate functions such as avg, max, count, and covariance, as well as the ability to construct user-defined functions (UDFs) in C++ for close-to-the-database computations.
In this example, we’re going to access an integer index on the “contentRating” JSON key, exposing it as “rating” values:
{
"options": {
"values": {
"range": {
"json-property": "contentRating",
"type": "xs:int"
},
"name": "rating"
}
}
}
<options xmlns="http://marklogic.com/appservices/search">
<values name="rating">
<range type="xs:int">
<json-property>contentRating</json-property>
</range>
</values>
</options>
Run this command to upload the new option:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"values":{"name":"rating","range":{"type":"xs:int","json-property":"contentRating"}}}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
This time, in our GET request, we’ll also request the mean and median averages by using the aggregate parameter. And to specify that we want the results in descending order (highest ratings first), we can use the direction parameter:
- http://localhost:8011/LATEST/values/rating?aggregate=avg&aggregate=median&direction=descending&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/values/rating?aggregate=avg&aggregate=median&direction=descending&options=tutorial&format=json (JSON)
Fetch the results to see how many conference talks scored 5 stars, how many scored 4 stars, etc.—as well as the mean and median rating for all conference talks:
"aggregate-result": [
{
"_value": "3.71839080459770115",
"name": "avg"
},
{
"_value": "4",
"name": "median"
}
]
<options xmlns="http://marklogic.com/appservices/search">
<values name="rating">
<range type="xs:int">
<json-property>contentRating</json-property>
</range>
</values>
</options>
Now, when you retrieve the values, restrict the values to come only from those documents matching a particular query by using the q parameter:
- http://localhost:8011/LATEST/values/rating?aggregate=avg&aggregate=median&q=company:marklogic&direction=descending&options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/values/rating?aggregate=avg&aggregate=median&q=company:marklogic&direction=descending&options=tutorial&format=json (JSON)
Run the program to see the ratings of all talks given by MarkLogic employees (documents matching the “company:marklogic” string query).
Retrieve tuples of values (co-occurrences)
In addition to retrieving values from a single source, you can also retrieve co-occurrences of values from two different value sources. In other words, you can perform analytics on multi-dimensional data sets. The following JSON document configures tuples (named “size-exposure”) backed by two different range indexes. In particular, it will enable you to get all the unique pairings of photo size and exposure time in image metadata:
{
"options": {
"tuples": [
{
"name": "size-exposure",
"range": [
{
"type": "xs:unsignedLong",
"element": {
"ns": "http://marklogic.com/filter",
"name": "size"
}
},
{
"collation": "http://marklogic.com/collation/",
"type": "xs:string",
"element": {
"ns": "http://marklogic.com/filter",
"name": "Exposure_Time"
}
}
]
}
]
}
}
<options xmlns="http://marklogic.com/appservices/search">
<tuples name="size-exposure">
<range type="xs:unsignedLong">
<element ns="http://marklogic.com/filter" name="size"/>
</range>
<range type="xs:string" collation="http://marklogic.com/collation/">
<element ns="http://marklogic.com/filter" name="Exposure_Time"/>
</range>
</tuples>
</options>
Run the following command to upload the options:
curl -v -X POST \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"tuples":[{"name":"size-exposure","range":[{"type":"xs:unsignedLong","element":{"name":"size","ns":"http://marklogic.com/filter"}}, {"type":"xs:string","collation":"http://marklogic.com/collation/", "element":{"name":"Exposure_Time","ns":"http://marklogic.com/filter"} } ]}]}}' \
'http://localhost:8011/LATEST/config/query/tutorial'
To view the tuples, make a GET request:
- http://localhost:8011/LATEST/values/size-exposure?options=tutorial&format=xml (XML)
- http://localhost:8011/LATEST/values/size-exposure?options=tutorial&format=json (JSON)
The results include unique pairings of distinct values:
"tuple": [
{
"distinct-value": [
{
"_value": "60641",
"type": "xs:unsignedLong"
},
{
"_value": "1/100",
"type": "xs:string"
}
],
"frequency": 1
}
]
Search with facets
MarkLogic’s real power lies in the combination of search and analytics. In the following example, we will define a constraint that functions as a facet configuration as well. These facets can then be used to interactively explore your data.
For this example, we’ll use a different options set instead of the “tutorial” options. Run the following command to upload the new options set (“tutorial2”):
{
"options": {
"constraint": [{
"name": "rating",
"range": {
"type": "xs:int",
"json-property": "contentRating",
"facet-option": "descending"
}
}, {
"name": "company",
"range": {
"type": "xs:string",
"collation": "http://marklogic.com/collation/",
"json-property": "affiliation",
"facet-option": "frequency-order"
}
}
]
}
}
<options xmlns="http://marklogic.com/appservices/search">
<!-- expose the "contentRating" JSON key range index as "rating" values -->
<constraint name="rating">
<range type="xs:int" facet="true">
<json-property>contentRating</json-property>
<!-- highest ratings first -->
<facet-option>descending</facet-option>
</range>
</constraint>
<!-- expose the "affiliation" JSON key range index as "company" values -->
<constraint name="company">
<range type="xs:string" facet="true" collation="http://marklogic.com/collation/">
<json-property>affiliation</json-property>
<!-- most common values first -->
<facet-option>frequency-order</facet-option>
</range>
</constraint>
</options>
Run the following command to deploy this search option.
curl -v -X PUT \
--digest --user rest-admin:x \
-H "Content-type: application/json" \
-d'{"options":{"constraint":[{"name":"rating","range":{"type":"xs:int","json-property":"contentRating","facet-option":"descending"}}, {"name":"company","range":{"type":"xs:string","collation":"http://marklogic.com/collation/","json-property":"affiliation","facet-option":"frequency-order"}} ]}}' \
'http://localhost:8011/LATEST/config/query/tutorial2'
GET the options to verify they’ve been uploaded:
- http://localhost:8011/LATEST/config/query/tutorial2?format=xml (XML)
- http://localhost:8011/LATEST/config/query/tutorial2?format=json (JSON)
The above configuration makes the “rating” and “company” constraints available for users to type in their query search string. You may be thinking “Isn’t that only going to be useful for power users? Most users aren’t going to bother learning a search grammar.” That’s true, but with a UI that supports faceted navigation, they won’t need to. All they’ll have to do is click a link to get the results constrained by a particular value. For example, the screenshot below from MarkMail shows four facets: month, list, sender, and attachment type:
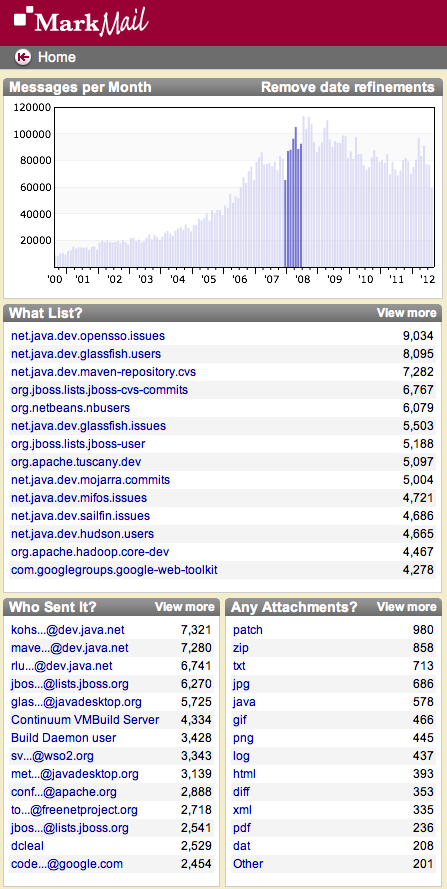
Each of these is a facet, whose values are retrieved from a range index. Moreover, users can drill down and pick various combinations of facets simply by clicking a link, or in the case of the histogram, swiping their mouse pointer.
MarkLogic’s REST API gives you everything you need to construct a model for faceted navigation. We’re not building any UI in this tutorial, but we can simulate faceted search by trying out different links representing a series of searches a user might make.
Find all conference talks (and list all facets):
- http://localhost:8011/LATEST/search?q=&collection=mlw2012&options=tutorial2&format=xml (XML)
- http://localhost:8011/LATEST/search?q=&collection=mlw2012&options=tutorial2&format=json (JSON)
Find and list facets for only the talks given by MarkLogic employees:
- http://localhost:8011/LATEST/search?q=company:MarkLogic&collection=mlw2012&options=tutorial2&format=xml (XML)
- http://localhost:8011/LATEST/search?q=company:MarkLogic&collection=mlw2012&options=tutorial2&format=json (JSON)
Find and list facets for MarkLogic talks that garnered a 5-star rating:
- http://localhost:8011/LATEST/search?q=company:MarkLogic+rating:5&collection=mlw2012&options=tutorial2&format=xml (XML)
- http://localhost:8011/LATEST/search?q=company:MarkLogic+rating:5&collection=mlw2012&options=tutorial2&format=json (JSON)
Find talks mentioning “java” that were rated 4 or higher:
- http://localhost:8011/LATEST/search?q=java+rating+GE+4&collection=mlw2012&options=tutorial2&format=xml (XML)
- http://localhost:8011/LATEST/search?q=java+rating+GE+4&collection=mlw2012&options=tutorial2&format=json (JSON)
In addition to the normal search results listing documents and their matching snippets, the results of a faceted search include lists of facets:
{
"options": {
"values": {
"range": {
"json-property": "contentRating",
"type": "xs:int"
},
"name": "rating"
}
}
}
<search:facet name="rating" type="xs:int"> <search:facet-value name="5" count="61">5</search:facet-value> <search:facet-value name="4" count="54">4</search:facet-value> <search:facet-value name="3" count="34">3</search:facet-value> <search:facet-value name="2" count="11">2</search:facet-value> <search:facet-value name="1" count="2">1</search:facet-value> <search:facet-value name="0" count="12">0</search:facet-value> </search:facet> <search:facet name="company" type="xs:string"> <search:facet-value name="MarkLogic" count="38">MarkLogic</search:facet-value> <search:facet-value name="Avalon Consulting, LLC" count="2">Avalon Consulting, LLC</search:facet-value> <search:facet-value name="Overstory, Ltd." count="2">Overstory, Ltd.</search:facet-value> <!--...--> </search:facet>
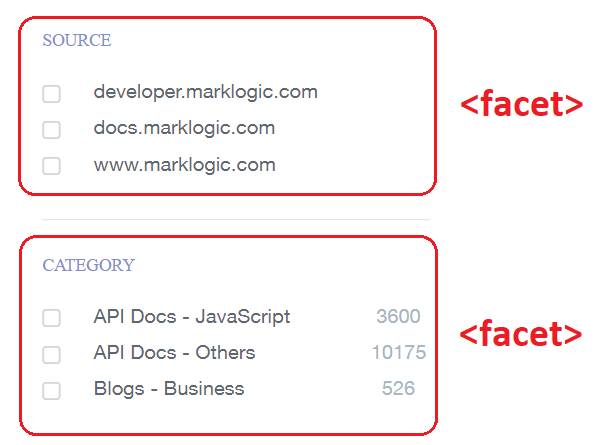
These values can be used to drive a faceted navigation UI. We saw earlier how the results structure maps to the search results on this website. Now we can see how it maps to facet results. One facet (“Category”) is represented by a <facet> element (or the “facets” array in JSON):
And its values are modeled by <facet-result> elements (or the facet-results array in JSON):
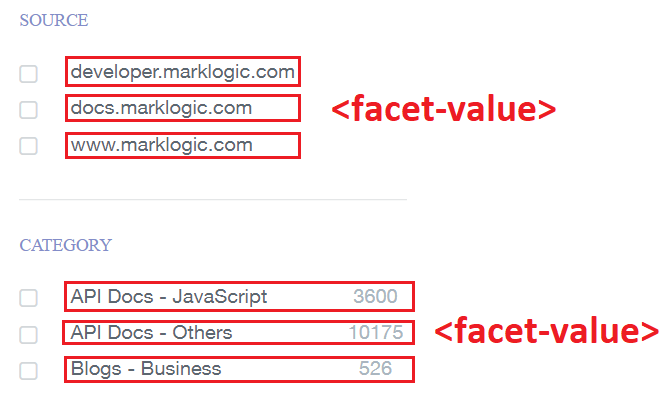
When a user clicks on one of these values, it takes them to a new automatically constrained search results page. For example, if they click “Blogs – Business,” it will re-run their search with the additional constraint ‘category:“Blogs – Business”’.
There is more to the REST API that we have not covered. Make sure to check out other features like snippeting, stemming, type ahead, ranged facets, and more. Don’t miss out on MarkLogic Grove and how it makes it easy to generate your first web-based search application that showcases everything we discussed above.