This document gives you an informal introduction to MarkLogic Server, the XQuery language, and the developer resource site dedicated to both. XQuery is one of two languages available to run inside MarkLogic, the other being JavaScript. If you’d rather explore with JavaScript, take a look at the Server-side JavaScript Getting Started.
Getting Your Bearings
The first stop on our tour today is MarkLogic Server.
MarkLogic Server is an Enterprise NoSQL database.
It is a document-centric, transactional, search-centric, structure-aware, schema-agnostic, XQuery- and JavaScript-driven, high performance, clustered, database server.
MarkLogic fuses together database internals, search-style indexing, and application server behaviors into a unified system. It uses XML and JSON documents, along with RDF triples, as its data model, and stores the documents within a transactional repository. It indexes the words and values from each of the loaded documents, as well as the document structure. And, because of its unique Universal Index, MarkLogic doesn’t require advance knowledge of the document structure (its “schema”) nor complete adherence to a particular schema. Through its application server capabilities, it’s programmable and extensible.
MarkLogic clusters on commodity hardware using a shared-nothing architecture and differentiates itself in the market by supporting massive scale and fantastic performance — customer deployments have scaled to hundreds of terabytes of source data while maintaining sub-second query response time.
It’s probably easiest to understand MarkLogic with a demonstration. At MarkMail.org you’ll find a web-based application that allows you to explore some 50 million messages from public mailing lists focused on technology and open source. You can drill down into the database based on search terms (including stemming where searcing for ‘win’ also matches on ‘wins’ and ‘won’) , or specific data facets like author, mailing list, date, attachment type, or message type.
Getting MarkLogic Server
The best way to understand what you can do with MarkLogic is to get a copy and play with it. Under the Developer License, individual developers can use a free copy of MarkLogic for development purposes. You’ll find a big button on the front page of the developer site, which points to https://developer.marklogic.com/download/. Check the information on that page for details of the license and specific system requirements. There’s one binary download for each platform.
For all platforms, there is a single shared installation guide, which we highly recommend reading. We’ll pause the tour now while you follow the guide’s instructions and install the database. It takes just a couple minutes.
Administering MarkLogic Server
The install guide should have walked you through the process of browsing to the admin interface at https://localhost:8001 to enter the license key. Now you can go to the same web address to administer the server. The admin interface lets you control the creation, management, and configuration of databases, forests, servers, and hosts. (There is also a Management API to make it easier to script configuration.) In the Admin UI, the left navigation bar contains the “nouns”. Use it to select the item you want to act upon. The top right tabs contain the “verbs”. Select the verb after selecting the noun. Under the tab is a data entry area for making changes.
The main thing you need to understand when using the admin pages is the database topology. Documents are stored in forests. One or more forests are gathered together to form a database. Databases are logical units against which you can assign HTTP, WebDAV and XDBC (for XCC Java connectivity) servers and set various runtime configuration options. The name forests comes from the fact that XML documents are tree structures, and a collection of trees is a forest. Databases exist as a logical abstraction because in a distributed environment it can be useful to have the same logical database spread across different hosts, perhaps one host with two forests and another with three.
There’s a full Administrator’s Guide, which you can use as your guide through the port 8001 administration pages.
Writing XQuery
Now that you have a database installed and had a chance to poke around the admin screens, I’ll bet you’re itching to dive in deeper and write your own XQuery code. There’s more than one way to do it: in the browser, or by creating files on the file system to name a few.
MarkLogic ships with a tool called Query Console. It’s a web-based application useful for writing quick queries.
Visit https://localhost:8000/qconsole to see a form where XQuery (along with JavaScript, SPARQL, and SQL) can be entered and evaluated. A drop-list on the page lets you choose which database and App Server to use when evaluating your XQuery. Note: Query Console is a powerful tool. Use it with care.
Try running the following query in Query Console:
(: This is welcome.xqy :)
<big xmlns="https://www.w3.org/1999/xhtml">
Welcome to { xdmp:product-name() }
{ xdmp:version() }
{ xdmp:product-edition() } Edition!
</big>
Understanding XQuery
XQuery is a potentially huge subject, but as the prior section showed, it can be very easy to get started. In Query Console, you can load a simple demo built from the XQuery Use Cases specification. In the Query Console, click the “Workspace” link (towards the upper right corner of Query Console) and select “Import Workspace…”. Navigate to <marklogic-dir>/Samples/w3c-use-cases.xml. The <marklogic-dir> is where MarkLogic is installed on your machine (e.g., c:/Program Files/MarkLogic/Samples on Windows, /opt/MarkLogic/Samples on Linux, or ~/Library/MarkLogic/Samples on OS X). Then click the “Import” button. You should see something like this on your screen:
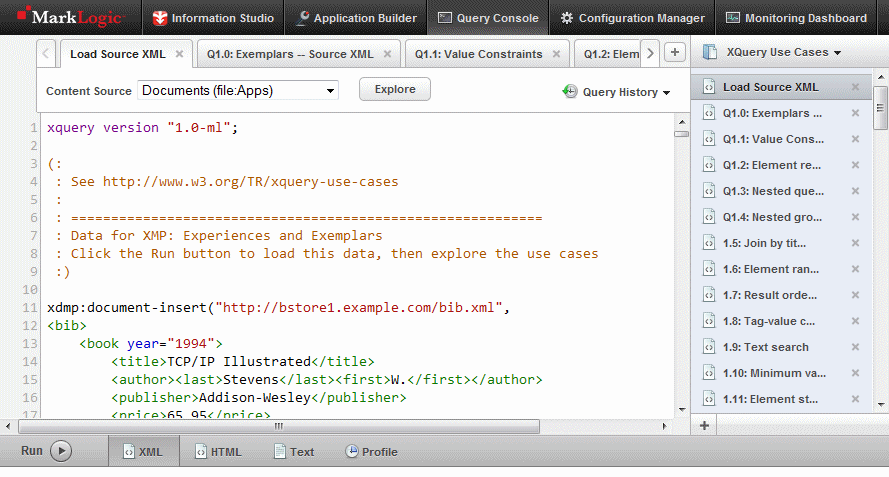
To get started:
- Choose the database you want to load the sample documents into, e.g., the default “Documents” database.
- Select the “Load Source XML” query at the top of the list on the right-hand side of the window, if it’s not already selected.
- Click the “Run” button.
This will load the sample documents into the database. Now, select another sample query from the list on the right-hand side of the window, and click “Run” to see its results (in your choice of XML, HTML, or Text format) at the bottom of the screen.
You can use these examples to get a taste for what XQuery code looks like. You can also enter your own custom query into the textarea. Here’s an example:
(: Try this in the textarea :) for $i in fn:collection() return fn:document-uri($i)
Running this gives you an unsorted listing of all the documents held within the database. The fn:collection() function returns a sequence of document nodes while fn:document-uri($i) returns the URI (the identifier) for document $i. This query might time out when run against larger databases—more efficient means to iterate URIs exist for larger data sets.
For some explanation on the XQuery Use Cases, I’ll point you toward the Getting Started with MarkLogic Server Guide.
XQuery is a language designed to efficiently query large collections of XML data. Examples include medical records, textbook content, office documents, or web pages. In this model, you store the documents directly into the XQuery database—possibly going through a conversion to XML. Then you query the documents to extract the bits and pieces deemed important. Increasingly XQuery is getting used for application logic as well, and thus becoming a one-stop-shopping language for building Web Apps.
Loading Documents
Standard XQuery leaves certain areas underspecified. An additional specification called “XQuery Update” provides a way to put things into the database, though it’s not yet widely implemented. Plain old XQuery also lacks built-in support for efficient full-text search, though the W3C is working on that too. MarkLogic addresses these gaps with numerous built-in functions. This section explains a few of the methods you need to understand in order to make the most of MarkLogic Server.
Watch out! If you’re new to XQuery and skipped over the Getting Started links above, you’re going to find the XQuery code in this section a little heavy. That’s OK. I’ll just assume you’re having such a great time here that you can’t wait to continue. Learn what you can. You can always come back.
When it comes to getting your content into the database, the most important MarkLogic Server built-in function is xdmp:document-load(). The first argument points to a local file to load, and by default also forms the database URI used to store the file. But if you desire the document to reside at a different database URI, you can pass in a second parameter with options (see the online docs for an example). Here’s a simple example: xdmp:document-load("/tmp/bib.xml")
This loads the file /tmp/bib.xml to the database under the name /tmp/bib.xml.
The xdmp:document-load() call returns the empty sequence on success and throws an error in case of problems. To print “Loaded” after a load, use the following trick:
xdmp:document-load("/tmp/bib.xml"),
"Loaded"
When you start writing code like this you’ll know you’re an XQuery master. This bit of code evaluates as a sequence of two items, the empty sequence (the output from the xdmp:document-load() function) followed by a string (“Loaded”). Put together, the result is the simple string “Loaded”. In case of error, the xdmp:document-load() call errors out and the trailing “Loaded” gets ignored. To handle errors, you can use try/catch (another extension to the language):
try {
xdmp:document-load("/tmp/bib.xml"),
"Loaded"
}
catch ($e) {
(: * below matches the element without need of declaring the namespace :)
<span>Problem loading { $e/*:message/text() }.</span>
}
The caught error is an XML node with elements like <message> that explains the reason for the error.
To view the content of a loaded document, use the standard fn:doc() function: fn:doc("/tmp/bib.xml")
This returns the document node associated with the given URI. To view a list of all loaded documents:
for $i in fn:collection() return fn:document-uri($i)
You saw this query earlier when you typed it into the use-cases textarea. Bringing the two queries together lets you produce a “list and view” script:
let $uri := xdmp:get-request-field("uri")
return
if (empty($uri) or $uri eq "") then
(
xdmp:set-response-content-type("text/html"),
<ul>
{
for $i in fn:collection()
let $doc := fn:document-uri($i)
return
<li><a href=
"view.xqy?uri={xdmp:url-encode($doc)}"
>{$doc}</a></li>
}
</ul>
)
else
(
xdmp:set-response-content-type("text/xml"),
if (empty(fn:doc($uri))) then
<error>No content</error>
else
fn:doc($uri)
)
To give this query a spin, paste it into Query Console or put it in a file where it will be served by an app server.
When a client requests a query file using the special extension .xqy, MarkLogic executes the query file content and returns the result. It’s basically CGI for XQuery. And because XQuery so easily constructs dynamic XHTML output, it’s an amazingly convenient development and deployment model. There’s no need to use something like Java classes in processing the result (although you can, as we’ll see later).
You’ll see a <ul> listing of all the documents in the database. Each is clickable, and when you click on the document you see its raw content. (Because the script doesn’t have any throttle support, be careful not to use it with long listings or large documents. Browsers don’t always like showing <ul> lists of more than a thousand items or XML files of more than a megabyte.)
The script first fetches the uri query string parameter. If it’s empty, then it treats it as a request for a listing. If it’s not empty, then it’s a request for the given URI to be displayed. To handle listings, we set the content type to text/html and print every fn:document-uri() linking to itself. To handle a document view, we set the content type to text/xml and print the fn:doc($uri) result or give a polite error note if the document couldn’t be found for any reason.
Guru Tip: The parentheses (notice they’re not curly braces) are required because the expression within a then or else clause has to be a single expression, and parentheses make the multiple items into a single, comma-separated sequence.
Searching Documents
Text search forms the core of a database. Search is the process of selecting from a collection of elements, those “relevant” to some search condition. MarkLogic includes a library called the Search API that makes it simple to perform powerful “Google-like” searches.
A simple search can be quite straightforward:
xquery version "1.0-ml";
import module namespace search = "https://marklogic.com/appservices/search" at
"/MarkLogic/appservices/search/search.xqy";
search:search("for sale")
This returns the top ten most relevant mentions of for and sale across all documents.
By passing in an options element node as the second argument you can get as sophisticated as your searching needs require. You can find more details in the Search API: Understanding and Using chapter of the Search Developer’s Guide or by viewing the 5-minute Guide to the Search API.
Hint: by default searches are case insensitive for all-lowercase tokens but case sensitive for tokens containing any uppercase characters. The logic is, if you bothered enough to capitalize, you probably meant it. To override this behavior, you can pass in settings via an options element node.
REST API Queries
While it’s easy to develop complete apps from within MarkLogic, there are times when you want to directly connect to the database from a separate application. For this, the database exposes a REST API interface. To learn how to work with the REST API, there are a few resources available:
- Quick introduction: The REST API in 5 Minutes
- More comprehensive tutorial: Learning the MarkLogic REST API
- Video tutorial: MarkLogic REST API
- Documentation: REST Application Developer’s Guide