Introduction
This document provides general data modeling design guidelines for XML and/or JSON documents in MarkLogic. We will start by reviewing the data modeling process with relational database back ends and then discuss how XML/JSON document modeling is different, before providing guidelines for data modeling in a document-oriented database. This content parallels a presentation given by Damon Feldman titled “Moving from Relational Modeling to XML and MarkLogic Data Models“.
Generally, because a document database is schema-agnostic, the fastest path to productivity is ingesting data “as is” and then modeling based on desired outputs. Unlike relational data where the data determines the ideal normal form, we track more to the expected services and types of analytics. Basically the standard ETL (extract, transform, and load) is turned around to ELT (extract, load, and transform).
Relational Data Modeling
Let’s start with reviewing the data modeling process in a relational database. Figure 1 provides a good overview of the components generally needed to create an application based on a relational database. As we can see, most of the data providers, data consumers, and data processing consist of hierarchical tree like structures; however, the persistence layer is very different. When building such applications, programmers generally start by looking at the business requirements and create objects that match those needs. Relational databases with normal form-focused data designs “shred” those data sets across multiple tables.
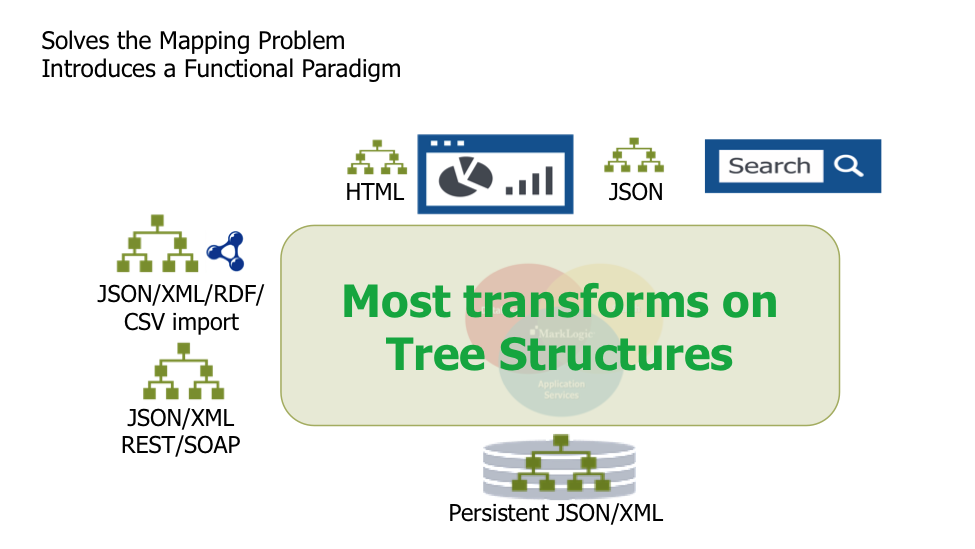 Figure 1: Relational database impedance mismatch
Figure 1: Relational database impedance mismatch
In order to abstract away this complexity, developers deploy logical modeling tools and object relational mapping (ORM) tools. Searching through those data sets requires yet another set of products with the accompanying need to synchronize the indexes with the ever-changing data. Communicating with the front end GUI is usually done through HTML or JSON (tree structures). Communicating with other services via APIs is usually performed through REST/SOAP with content in JSON/XML (still more tree structures). Reference data is imported via JSON, XML, RDF, or CSVs (a lot of which can be modeled as trees or semantic relationships).
Digging a little deeper, in relational database design, with third normal form (3NF), the data drives the model much more than the usage patterns do. The upside of this type of modeling is that it reduces duplicate data and provides a very flexible query capability. On the other hand, there are a significant number of issues: The need to perform lots of joins can cause performance issues. Models that are good for operations are not good for analytics and reporting, requiring the creation of copies of the data in data warehouse with star-schemas or other custom de-normalized views. The data shredding can lead to data consistency issues. The proliferation of tables and the need to combine many tables to get a simple view of the business object of interest makes these models hard to understand (think huge wall-sized data model plots). This complexity introduces the need for other database-related infrastructure such as logical data models and ORM tools.
Because relational databases don’t model the incoming data naturally (as is), the bulk of the programming effort in these applications is mapping or translation, the T in ETL. This impedance mismatch and the need to synchronize multiple models consumes countless development resource cycles as well as CPU cycles and is what a good document-oriented data model will solve.
NoSQL Document Modeling Benefits
MarkLogic simplifies the modeling problem by removing the mismatch between the way data is stored and the way it is consumed. Figure 2 again shows that most of the data providers, data consumers, and application layer are hierarchical in nature. Here is where the document-oriented databases really help, because the datasets can now be persisted in the way they are ingested and naturally used. The goal of data modeling here is to identify application or enterprise-wide business-focused objects and model documents that naturally fit those objects.
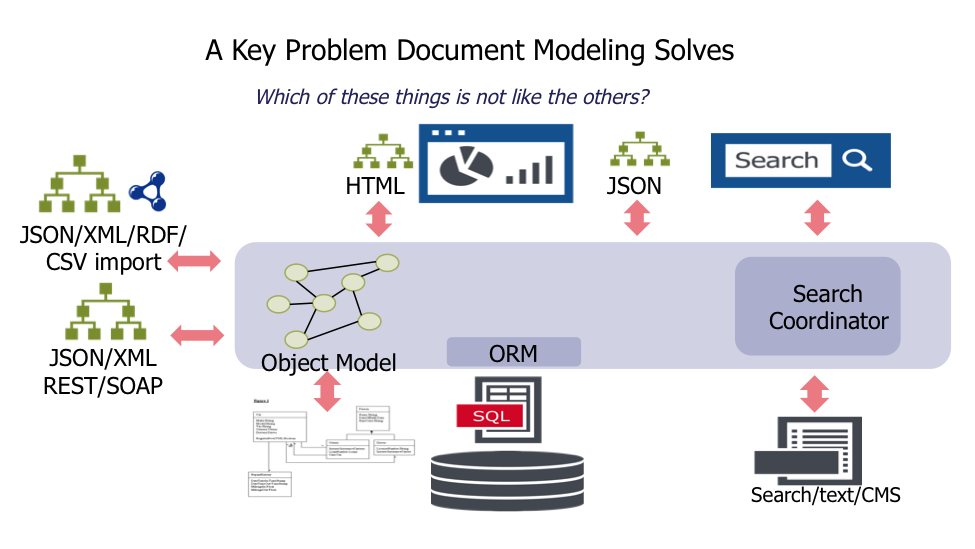
Figure 2: Common data provider, consumer, and persistence
Document-Oriented Database
Now that we have a system-wide baseline of why MarkLogic, with its hierarchical data model and RDF support, is much better as a persistence model for applications and enterprise-wide operational databases/data warehouses, let’s explore what to not do and what to do with regards to document-oriented data modeling.
Here are things to avoid when modeling in a document-oriented database:
- Rows: Don’t think in terms of tables.
- Normalization: Avoid too much normalization. Focus on natural business groupings and human readable/understandable formats. Avoid reference tables. With built-in full text/token search, updating de-normalized values is much easier.
- Cardinality: Don’t split out data into separate documents based solely on cardinality. Try to include 1:1 and 1:many relationships in your natural business groupings.
- Constraints: Reduce the need for cross-document constraints by keeping natural relationships within a document.
- Logical Models: When working with relational databases, it’s often necessary to create a logical model as a simplified view of the complex physical model (the schema). For documents, this generally isn’t necessary. Focus on intuitive documents from the start.
- Data Warehouse: Don’t build out another data warehouse database. Use your operational database as your data warehouse. Scale out as necessary to support the performance you need.
Document Models
Here are things to do when modeling data in document models:
- Data modeling focus: Build human-oriented intuitive models that are readable and understandable by non-technical users. If you show a recipe XML document to someone, he or she will easily see that the root element labels it as a recipe, that the recipe has ingredients and steps, and so on.
- Queries: Think about the application and queries/searches that you want to run and model your documents to answer those queries (e.g. customer centric models versus marketing/product-centric models). If your end-users will search for books and authors, those are good candidates for high-level document types in your database.
- Number of models: Maintain as few types of models as possible. An example pattern that work well is “as is” and/or “as used”. Depending on whether your application is write-heavy or read-heavy consider separate persistence for “as is” and/or “as used” models.
- “As is” lets you get the data in quickly, trace back to source data sets easily, and manage / detect data updates more readily.
- “As used” lets you create very high performing models because they require very little computation or mapping before being presented to data consumers. If someone has already done some enterprise modeling, you want to leverage that and use it. Be especially careful to use the same namespaces across as many data consumers as possible. Re-use as many chunks of data (e.g. a level of hierarchy) within documents across consumers. Shoot for one consistent model: industry standards and/or enterprise-wide standards.
- Cardinality: As stated above 1:1 (book:title) and 1:many (book:chapters) should be included in documents to the extent possible. Many:many (book:author) should use documents of each type with constraints with cross-document linking performed via unique IDs that at either in the documents themselves, or are stored as document collection tags. These unique IDs should be indexed with “range indexes” to allow for fast joins between the different types of documents. Alternatively RDF relations could be leverage here.
- De-normalization: Sometimes you want to de-normalize some basic elements (e.g. dates & names) from one document type to another in order to perform queries without having to do joins. For instance, a book document might include an author name (for quick searches or faceting) and an ID (to retrieve additional information), but not the author’s birthdate, home location, and so on.
- Persistence: A key pattern that gets used when persisting data is the Envelope pattern, where extra report/query-related data or metadata gets recorded in a metadata section of the document, leaving the original unmodified.
- Good examples of metadata: CRUD time stamps, software version used to edit the data, data format version, internal numeric indexes …
- Minimize the transforms: Easier and faster to implement. Easier to query internally. Create standards-based rules.
- Put discrete pieces of data into their own elements. In other words, rather than having an address element with the full address, make street, city, country, and other elements below the address element. This allows access to those discrete pieces of data without having to use wildcards on strings.
Additional considerations
Here are a few additional considerations for NoSQL data modeling:
- Documents are like very flexible rows that contain built-in relationships. Take advantage of as many relationships as possible through the appropriate use of hierarchical tags.
- In MarkLogic, documents are ACID compliant for cluster-wide updates.
- Collections are much more flexible than tables. Remember a document can be in multiple collections simultaneously. Collections can be use for fast search/joins across disparate documents.
- In MarkLogic, consider the document size when deciding what to include in a single document. The ideal document size for today’s technology ranges from 1K to 100K for JSON/XML documents. Sizes larger than 100K are acceptable depending upon your hardware infrastructure and response time needs. Sizes smaller than 1K are associated with more overhead. 1:1 or 1:many relationships should be done in a single document unless you are running into size constraints.
- Since MarkLogic normally updates documents by writing a completely new document to the database and invalidating the older version, as long as documents are adhering to the above size constraints, the frequency of updates of individual elements should not be a major consideration in partitioning documents unless the frequency of updates is really high.
- Your tags should match queries you need. For example, instead of general unstructured content “address” tag, if you need to search by state or zip consider the following tags: streetAddress1, streetAddress1, city, state, zip, country.
- Documenting the schema of your database may or may not be necessary. Sample documents may be sufficient. If you want to record a format schema, you can do so with an XML Schema (.xsd) or UML.
- Consider your messaging formats and try to include as many reusable chunks as possible between your message formats and your persistence models.