The Data Movement Software Development Kit (DMSDK) is a Java library for applications that need to move large amounts of data into, out of, or within a MarkLogic cluster. For those familiar with the existing MarkLogic ecosystem, it provides the core capabilities of MLCP and CoRB in the vernacular of the Java Client API, which include:
- Ingest data in bulk or streams from any Java I/O source, leveraging your entire cluster for scale-out performance
- Bulk process documents in situ in the database using JavaScript or XQuery code invoked remotely from Java
- Export documents based on a query, optionally aggregating to a single artifact, such as CSV rows
Integrating data from multiple systems starts with getting data from those systems. The Data Movement SDK allows you to do this easily, efficiently, and predictably in a programmatic fashion so that it can be integrated into your overall architecture.
Java is the most widely used language in the enterprise. It has a mature set of tools and an immense ecosystem. MarkLogic provides Java APIs to make working with MarkLogic in a Java environment simple, fast, and secure. The Java Client API is targeted primarily for interactive applications, such as running queries to build a UI or populate a report, or updating individual documents. Its interactions are synchronous—make a request, get a response.
The Data Movement SDK complements the Java Client API by adding an asynchronous interface for reading, writing, and transforming data in a MarkLogic cluster. A primary goal of the Data Movement SDK is to enable integrations with existing ETL-style workflows, for example to write streams of data from a message queue or to transfer relational data via Java DataBase Connectivity (JDBC) or Object-Relational Mapping (ORM).
Setup
The DMSDK is packaged as part of the Java Client API JAR, such that an application can perform a mix of short synchronous requests and long-lived asynchronous work in concert. The JAR is hosted on Maven Central.
Add the following to your project’s build.gradle file:
dependencies {
repositories {
mavenCentral()
mavenLocal()
}
compile 'com.marklogic:marklogic-client-api:4.0.1'
// …other application dependencies
}
MarkLogic publishes the source code and the JavaDoc along with the compiled JAR. You can use these in your IDE to provide context-sensitive documentation, navigation, and debugging.
To configure Eclipse or IntelliJ, add the following section to your application’s build.gradle file and run gradle eclipse or gradle idea from the command line.
plugins {
id "java"
id "eclipse"
id "idea"
}
eclipse {
classpath {
downloadJavadoc = true
downloadSources = true
}
}
idea {
classpath {
downloadJavadoc = true
downloadSources = true
}
}
Or for Maven users, add the following to your project’s pom.xml:
<dependency> <groupId>com.marklogic</groupId> <artifactId>marklogic-client-api</artifactId> <version>4.0.1</version> </dependency>
Writing Batches of Documents
WriteBatcher provides a way to build long-lived applications that write data to a MarkLogic cluster. Using the add() method you can add documents to an internal buffer. When that buffer is filled (that is, reaches the batch size configured with withBatchSize()), it automatically writes the batch to MarkLogic as an atomic transaction. Under the covers, theDataMovementManagerfigures out which host to send the batch using round-robin, in order to distribute the workload in a multi-host cluster. Thus a write batch will remain available in the event of a forest being unavailable, but not a host. A future release will accommodate host failures as well.
The example below creates synthetic JSON documents inline. In a real application, though, you’d likely get your data from some sort of Java I/O. The Data Movement SDK leverages the same I/O handlers that the Java Client API uses to map Java data types to MarkLogic data types.
The onBatchSuccess() and onBatchFailure() callbacks on the WriteBatcher instance provide hooks into the lifecycle for things like progress and error reporting. The following illustrates the general structure of how an application would employ WriteBatcher.
// Set up the connection to the MarkLogic cluster.
// Client instances are designed for reuse. In a real application
// you’d use something like dependency injection to manage this
// externally and share it with other classes.
final DatabaseClient marklogic = DatabaseClientFactory
.newClient("localhost", 8000,
new DatabaseClientFactory.DigestAuthContext("admin", "********")
);
// DataMovementManager is the core class for doing asynchronous jobs against
// a MarkLogic cluster.
final DataMovementManager manager = marklogic.newDataMovementManager();
// In this case, we’re writing data in batches
final WriteBatcher writer = manager
.newWriteBatcher()
.withJobName("Hello, world!")
// Configure parallelization and memory tradeoffs
.withBatchSize(50)
// Configure listeners for asynchronous lifecycle events
// Success:
.onBatchSuccess(batch -> /* … */)
// Failure:
.onBatchFailure((batch, throwable) -> /* … */);
// Start an asynchronous job with the above configuration.
// Use the JobTicket to refer to this job later, for example
// to track status.
final JobTicket ticket = manager.startJob(writer);
// ⬆ One-time job configuration ︎
// ⬇︎ Create documents and send them to the writer
// The WriteBatcher handles all of the nitty-gritty of batching,
// parallelization, and even host failover.
writer.add(/* … */); // (★) See below for a specific implementation
// Override the default asychronous behavior and make the current
// thread wait for all documents to be written to MarkLogic.
writer.flushAndWait();
// Finalize the job by its unique handle generated in startJob() above.
manager.stopJob(ticket);
The above omits the details of the actual data that’s sent to the writer.add() method (★). The simplest implementation might look something like:
/* …snip */
// (★) Implementation that adds 10,000 synthetic JSON documents into a
// collection named 'raw'.
// In a real application you’d probably get JSON or XML documents
// from a message bus, another database, a web service, the file system,
// or any number of other I/O source available to Java.
final String[] statuses = { "active", "in-progress", "closed" };
for (int i = 0; i < 10000; i++) {
final String id = UUID.randomUUID().toString();
final String now = Instant.now().toString();
final String status = statuses[new Random().nextInt(statuses.length)];
// Call add() as many times as you need, even from multiple threads.
writer.add("/" + id + ".json",
new DocumentMetadataHandle().withCollections("raw"),
// Brain-dead example of creating JSON from a String
// Use the Java Client API’s I/O adapters (i.e. *Handle) to formulate
// JSON or XML documents from other sources.
new StringHandle(
"{ \"id\": \"" + id
+ "\",\n\"timestamp\": \"" + now
+ "\",\n\"status\": \"" + status + "\"}"
).withFormat(Format.JSON));
}
/* …snip */
Querying Documents
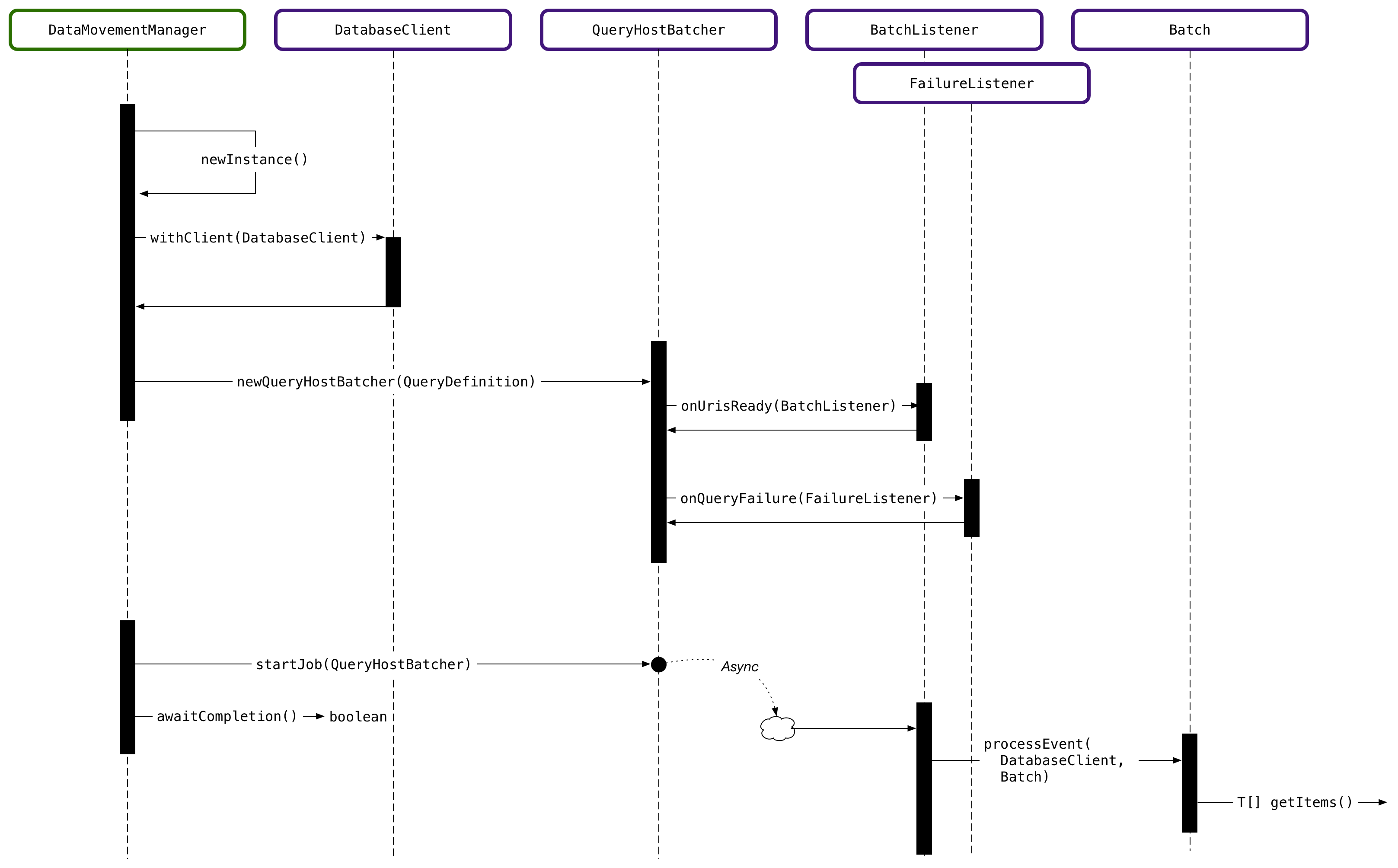
QueryBatcher is the entry point to accessing data already in a MarkLogic database. Its job is to issue a query to scope a set of documents as input to some other work, such as transformation or delete. You express the query using any of the query APIs available in the Java Client API, such as structured query or query by example. The onUrisReady() of QueryBatcher is the key.BatchListener instance that determines what to do with the list of URIs, or unique document identifiers, that it receives by running the query. The DataMovementManager figures out how to efficiently split the URIs in order to balance the workload across a cluster, delivering batches to the BatchListener. A BatchListener implementation can do anything it wants with the URIs.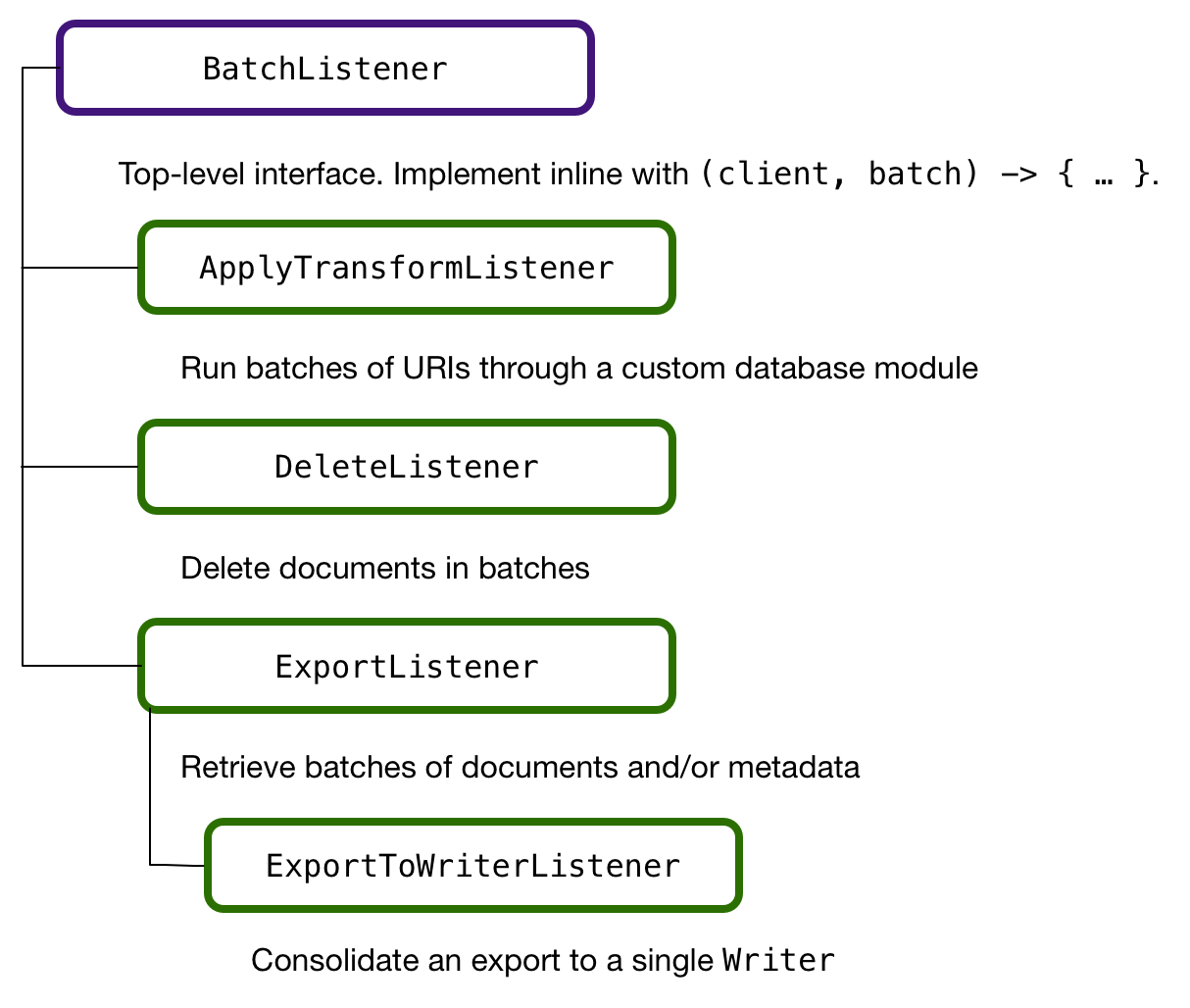
The first example below shows a BatchListener implementation that uses a server-side module named harmonize-entity to transform documents matching a query. The Data Movement SDK uses the same server-side transform mechanism as the rest of the Java Client API to manage and invoke code in the database.
At a high level, this is similar to how other databases use stored procedures. However, MarkLogic transforms are implemented in XQuery or JavaScript and have access to all of the rich built-in APIs available in the database runtime environment.
final DatabaseClient marklogic = DatabaseClientFactory
.newClient("localhost", 8000,
new DatabaseClientFactory.DigestAuthContext("admin", "********")
);
final DataMovementManager manager = marklogic.newDataMovementManager();
// Build query
final StructuredQueryBuilder query = marklogic
.newQueryManager()
.newStructuredQueryBuilder();
// Specify a server-side transformation module (stored procedure) by name
ServerTransform transform = new ServerTransform("harmonize-entity");
ApplyTransformListener transformListener = new ApplyTransformListener()
.withTransform(transform)
.withApplyResult(ApplyResult.REPLACE) // Transform in-place, i.e. rewrite
.onSuccess(batch -> /* … */)
.onSkipped(batch -> /* … */)
.onBatchFailure((batch, throwable) -> /* … */);
// Apply the transformation to only the documents that match a query.
// In this case, those in the “raw” collection.
final QueryBatcher batcher = manager
.newQueryBatcher(query.collection("raw"));
batcher
.onUrisReady(transformListener)
.onQueryFailure(exception -> exception.printStackTrace());
final JobTicket ticket = manager.startJob(batcher);
batcher.awaitCompletion();
manager.stopJob(ticket);
The second example below shows how you’d use the DeleteListener, an implementation of BatchListener, to bulk delete the documents that match a query. Similarly, you can build your own BatchListener implementations.
final DatabaseClient marklogic = DatabaseClientFactory
.newClient("localhost", 8000,
new DatabaseClientFactory.DigestAuthContext("admin", "********")
);
final DataMovementManager manager = marklogic.newDataMovementManager();
final StructuredQueryBuilder sqb = new StructuredQueryBuilder();
final StructuredQueryDefinition query = sqb.and(
sqb.collection("raw"),
sqb.value(sqb.jsonProperty("status"), "closed")
);
final QueryBatcher batcher = manager
.newQueryBatcher(query)
.withBatchSize(2500)
// Run the query at a consistent point in time.
// This means that the matched documents will be the same
// across batches, even if the underlying data is changing.
.withConsistentSnapshot()
// Included QueryBatchListener implementation that deletes
// a batch of URIs.
.onUrisReady(new DeleteListener())
.onQueryFailure(throwable -> throwable.printStackTrace());
manager.startJob(batcher);
Note the use of the withConsistentSnapshot() on the QueryBatcher instance above. This is important whenever it’s possible that the matched documents will change between batches, either as the result of work done in the query batch, such as batches that delete documents, as above, or if other transactions are changing data that matches your query. withConsistentSnapshot() ensures that all batches will see the exact same set of documents as existed at job start and that subsequent updates will not affect which documents match the query.