Introduction to DMSDK
Data Movement SDK (DMSDK) is a set of Java classes which are part of the Java Client API in MarkLogic 9+ and is used for loading and transforming large numbers of documents. The DMSDK is asynchronous, and efficiently distributes (a generally long running) job across a MarkLogic cluster. Along with DMSDK’s ability to read, transform, write, and delete documents, it supports any input source supported by Java, including streaming or file, as well as XQuery or JavaScript for transformations.
While MLCP and the DMSDK are both Java-based tools that can read documents and do transformations, MLCP is a relatively simple command-line tool, designed for bulk loading. The DMSDK, on the other hand, is a development kit for Java developers who want the capability to create highly customized load and transformation jobs, processing data such as Java message queues, a real-time Twitter pipeline, or a workflow where documents are periodically dropped into a directory.
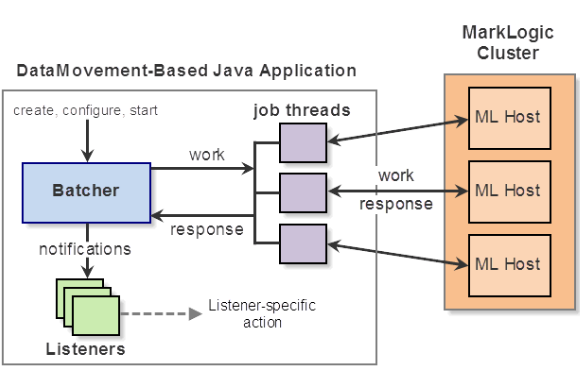
Figure 1: A Java application using DMSDK distributes jobs across a MarkLogic cluster
Following the diagram in Figure 1, a batcher acts as a job controller and encapsulates the characteristics of a job (e.g., threads, batch size, listeners), controlling the workflow. The sub-interfaces of the batcher determine the workflow, such as reading or writing.
There are two kinds of batcher jobs:
When using DMSDK, there are basic classes which are used in almost every application, creating the required objects and starting the job. Let’s review below.
- A write job sends batches of documents to MarkLogic for insertion into a database. You can insert both content and metadata.
- A query job creates batches of URIs and dispatches each batch to listeners. The batcher gets URIs either by identifying documents that match a query or from a list of URIs you provide as an Iterator. The action applied to a batch of URIs is dependent on the listener. For example, a listener might read the documents specified by the batch from the database and then export them to the filesystem.
Basic DMSDK Classes
Documentation of the classes below is available in the MarkLogic Java Client API.
When using DMSDK, there are basic classes which are used in almost every application, creating the required objects and starting the job. Let’s review below.
- Create database client connection (like in any MarkLogic Java Client API code):
DatabaseClient client = DatabaseClientFactory.newClient( <rest-server-hostname>, <rest-server-port>, new DatabaseClientFactory.DigestAuthContext(<username>, <password>) );
- After you have created client connection in your Java client API code, use the DataMovementManager class as the primary DMSDK job control interface. This object is intended to be long-lived, and should manage multiple jobs.
- Now create a batcher. The type of batcher you create determines the basic job flow.
For a write batcher:
WriteBatcher batcher = dmm.newWriteBatcher();
batcher.onBatchSuccess(batch-> {/* take some action */})
.onBatchFailure((batch,throwable) -> {/* take action */})
// ...additional configuration...
For a query batcher:
QueryBatcher batcher = dmm.newQueryBatcher(query);
batcher.onUrisReady(batch -> {
for (String uri : batch.getItems()) {
System.out.println(uri);
}
})
.onQueryFailure( exception -> exception.printStackTrace()
);
// ...additional configuration...
Configure job characteristics such as batch size and thread count, which can be done using batcher.withBatchSize(<count>)and batcher.withThreadCount(<count>).
Attach one or more listeners to interesting job events. The available events depend on the type of job. Using listeners in a job is shown via more detailed examples below; follow the comments in the example code surrounded by asterisks (***).
4. To submit the DMSDK job, use the startJob method: dmm.startJob(batcher);
Once the job has started, it runs asynchronously and is a non-blocking operation.
Stop the job when you no longer need it, otherwise the job will run indefinitely. A graceful shutdown of a job includes waiting for in-progress batches to complete.
Loading and Transforming Documents
The following example has been derived from our Data Integration course; however, our focus here is to provide an example of a DMSDK job for transforming and loading documents.
Suppose you want to create a set of documents that use the envelope pattern and model with application specific canonical data about the entity while preserving the original source data as-is for compliance reasons. For example:
<envelope>
<instance>
…canonical representation of entity data goes here…
</instance>
<attachments>
….raw source document goes here….
</attachments>
</envelope>
Figure 2: Example of envelope pattern
Load your server-side transformation code (e.g., envelope.xqy, as below) into your modules database.
xquery version "1.0-ml";
module namespace trans = "https://marklogic.com/rest-api/transform/envelope";
declare function trans:transform($context as map:map, $params as map:map,
$content as document-node()) as document-node()
{
let $uri := map:get($context, "uri")
let $envelope :=
document {
element envelope {
element instance {
(: fetch / transform canonical representation of entity data here from $content… :)
},
element attachments { $content }
}
}
return $envelope
};
Figure 3: Example of server-side transformation code, e.g. envelope.xqy
For example, if you use the REST endpoint /v1/config/transforms/<module-name> to load envelope.xqy, your curl loading script may look like this:
curl --anyauth --user admin:admin -X PUT -d@"<location of envelope.xqy>" -i -H "Content-type: application/xquery" https://localhost:<port>/v1/config/transforms/envelope
Create a Maven project that uses the Java Client API. The pom.xml file would have a dependency corresponding to marklogic-client-api (version 4.x).
Create the following two classes in any package you want (the examples here use com.ml.mlu):
Utils.java– reads example properties file and make a database client connection (see Figure 5)LoadAndTransform.java– runs DMSDK job to load and transform document (see Figure 6)
These two classes use this example.properties file:
# properties to configure the examples example.writer_user=admin example.writer_password=admin example.host=localhost example.port=REST enabled http server port number example.authentication_type=digest example.data_path=path from where data needs to be loaded
Figure 4: Sample example.properties
// import statements here
public class Utils {
public static DatabaseClient getDbClient(ExampleProperties props) {
return DatabaseClientFactory.newClient(
props.host, props.port,
new DatabaseClientFactory.DigestAuthContext(props.writerUser, props.writerPassword)
);
}
// Code for reading the example.properties
Figure 5: Example Utils.java
Note that comments surrounded by asterisks in the code sample below reference the steps in the Basic DMSDK Classes section.
// import statements here
public class LoadAndTransform {
static final private String URI_PREFIX = <uri prefix of documents to be processed>;
static final private String[] FILENAMES = {<list of files to be processed>};
static final private String[] COLLECTIONS = {"canonical", "dmsdk_transformed"};
static final private String TRANSFORM = "envelope";
public static void main(String[] args) throws IOException {
run(Utils.loadProperties());
}
public static void run(ExampleProperties props) throws IOException {
System.out.println("settings: " + props.host + ":" + props.port);
System.out.println("Working Directory = " + System.getProperty("user.dir"));
// *** Step 1: Connect the Client ***
DatabaseClient client = Utils.getDbClient(props);
loadData(client, props);
// release the client
client.release();
}
// set up by writing the document content used in the example query
public static void loadData(DatabaseClient client, ExampleProperties props)
throws IOException
{
DocumentMetadataHandle metadata =
new DocumentMetadataHandle().withCollections(COLLECTIONS);
// *** Step 2: Use the DataMovementManager class ***
DataMovementManager dmm = client.newDataMovementManager();
// *** Step 3: Create a batcher ***
WriteBatcher batcher = dmm.newWriteBatcher()
// Add the transform
.withTransform(new ServerTransform(TRANSFORM))
.onBatchSuccess(new WriteBatchListener() {
public void processEvent(WriteBatch batch) {
System.out.println("batch # " + batch.getJobBatchNumber()
+ " - files loaded : " + batch.getJobWritesSoFar());
}
})
.onBatchFailure(new WriteFailureListener() {
public void processFailure(WriteBatch batch, Throwable e) {
System.out.println("FAILED: batch # " + batch.getJobBatchNumber()
+ ", so far: " + e);
e.printStackTrace(); } });
// *** Step 4: Submit the DMSDK job ***
dmm.startJob(batcher);
for (String filename: FILENAMES) {
FileHandle fh = new FileHandle(new File(props.dataPath + filename));
fh.withFormat(Format.XML);
// Add the metadata for the collections
batcher.add(URI_PREFIX + filename, metadata, fh);
}
batcher.flushAndWait();
System.out.println("Finished loading docs");
dmm.stopJob(batcher);
dmm.release();
}
Figure 6: Example LoadAndTransform.java
Exporting Documents to Filesystem Based on String Query
In the example in Figure 7, you will see how to extract documents from a database based on a string query and save them on the filesystem in their native format. Remember, comments surrounded by asterisks in the code sample below reference the steps in the Basic DMSDK Classes section.
// *** Step 1: Assume "client" is a previously created DatabaseClient object.
private static String EX_DIR = "/your/directory/here";
private static String strquery = "your-string-query";
// *** Step 2: Use the DataMovementManager class ***
private static DataMovementManager dmm =
client.newDataMovementManager();
// ...
public static void exportByQuery() {
// Construct a directory query with which to drive the job.
QueryManager qm = client.newQueryManager();
StringQueryDefinition queryDef = qm.newStringDefinition();
queryDef.setCriteria(strquery);
// *** Step 3: Create and configure a batcher ***
QueryBatcher batcher = dmm.newQueryBatcher(query);
batcher.onUrisReady(
new ExportListener()
.onDocumentReady(doc-> {
String uriParts[] = doc.getUri().split("/");
try {
Files.write(
Paths.get(EX_DIR, "output",
uriParts[uriParts.length - 1]),
doc.getContent(
new StringHandle()).toBuffer());
} catch (Exception e) {
e.printStackTrace();
}
}))
.onQueryFailure( exception -> exception.printStackTrace() );
// *** Step 4: Submit the DMSDK job ***
dmm.startJob(batcher);
// Wait for the job to complete, and then stop it.
batcher.awaitCompletion();
dmm.stopJob(batcher);
}
The example code above uses QueryBatcher and ExportListener to read documents from MarkLogic and save them to the filesystem. The job uses a string query to select the documents to be exported.
If sending the contents of each document as-is to the writer does not meet the needs of your application, you can register an output listener to prepare custom input for the writer. Use onGenerateOutput method to register such a listener using class ExportToWriterListener. Each fetched document (and its metadata) is made available to the onGenerateOutput listeners as a DocumentRecord.
In the example in Figure 8, you will see how to create an ExportToWriterListener configured to fetch documents and collection metadata. The onGenerateOutput listener generates a comma-separated string containing the document URI, first collection name, and the document content.
ExportToWriterListener.withRecordSuffix is used to emit a newline after each document is processed. The end result is a three-column CSV file.
FileWriter writer = new FileWriter(outputFile));
// *** Step 3: Create a batcher ***
ExportToWriterListener listener = new ExportToWriterListener(writer)
.withRecordSuffix("\n")
.withMetadataCategory(DocumentManager.Metadata.COLLECTIONS)
.onGenerateOutput(
record -> {
try{
String uri = record.getUri();
String collection =
record.getMetadata(new DocumentMetadataHandle())
.getCollections().iterator().next();
String contents = record.getContentAs(String.class);
return uri + "," + collection + "," + contents;
} catch (Exception e) {
e.printStackTrace();
}
}
);
Figure 8: Example code using ExportToWriterListener and onGenerateOutput
Benefits of Data Movements SDK
These were just a few starting examples of what we can do with the DMSDK, moving data into, out of, and [later] within a MarkLogic cluster.
Java is the most widely used language in the enterprise. It has a mature set of tools and an immense ecosystem. MarkLogic provides Java APIs to make working with MarkLogic in a Java environment simple, fast, and secure. The DMSDK complements the Java Client API by adding an asynchronous interface for reading, writing, and transforming data in a MarkLogic cluster.
Integrating data from multiple systems starts with getting data from those systems. The DMSDK allows you to do this easily, efficiently, and predictably in a programmatic fashion so that it can be integrated into your overall architecture.