In MarkLogic 9, you can define a relational lens over your document data, so you can query parts of your data using SQL or the new Optic API. Templates let you specify which parts of documents make up rows in a view. You can also use templates to define a semantic lens, specifying which values from a document should be added to the index as triples.
Note that the template is entirely independent of the documents– a template doesn’t change your documents in any way, it just changes how the indexes (row index and triple index) are populated based on values in the documents.
Templates let you look at the data in your documents in several ways, without changing the documents themselves. A relational lens is useful when you want to let SQL-savvy users access your data and when users want to create reports and visualizations using tools that communicate using SQL. It is also useful when you want to join entities and perform aggregates across documents. A semantic lens is useful when your documents contain some data that is naturally represented as triples and queried in SPARQL.
System requirements and installation
For the examples in this section you need MarkLogic 9. We assume you are going to run these examples in the Documents database, using Query Console.
Additionally, make sure that your Documents database has its triple index enabled as shown below:

Simple document, relational lens example
Insert a simple document; create and validate a simple template; create a view; show the view and rows; query using SQL. The examples are provided in both JSON and XQuery. If you’re running them choose just one– running both will lead to duplicate results in some of the queries, because you’ll have duplicated templates stored at different URIs.
We start with a text-rich XML or JSON document (your choice) with some metadata. To begin with this first example, run this in Query Console:
declareUpdate();
xdmp.documentInsert(
"/soccer/match/1234567.json",
{
"match": {
"id": 1234567,
"docUri": "/soccer/match/1234567.json",
"match-date": "2016-01-12",
"league": "Premier",
"teams": {
"home": "Bournemouth",
"away": "West Ham United"
} ,
"score": {
"home": 1,
"away": 3
},
"abstract": "Dimitri Payet inspired a West Ham comeback to secure victory over Bournemouth." ,
"report": "Harry Arter had given the hosts the lead with a 25-yard strike. ... "
}
},
xdmp.defaultPermissions(),
["TDE", "source1"]
)
xdmp:document-insert(
"/soccer/match/1234567.xml",
<match>
<id>1234567</id>
<docUri>/soccer/match/1234567.xml</docUri>
<match-date>2016-01-12</match-date>
<league>Premier</league>
<teams>
<home>Bournemouth</home>
<away>West Ham United</away>
</teams>
<score>
<home>1</home>
<away>3</away>
</score>
<abstract>Dimitri Payet inspired a West Ham comeback to secure victory over Bournemouth.</abstract>
<report>Harry Arter had given the hosts the lead with a 25-yard strike. ... </report>
</match>,
(),
("TDE", "source1")
)
You can do interesting queries and searches to find this document using XQuery, Server-Side JavaScript, or one of the MarkLogic client-side APIs (REST, Java, or Node.js). See Getting Started With MarkLogic Server for some of the ways you can search in MarkLogic.
This is a rich text document, with lots of text and some structure. But it’s easy to imagine a relational lens through which you could see a view of a part of this document– say, just the metadata.
Let’s create a Template that defines a view that includes the id, docUri, match-date, and league. We’ll create it in-memory (as a variable), and validate it, then apply it to our match report document to see what the rows look like.
In the template, notice that there are two aspects that define what documents it should apply to. The first is the “context” property or element. This is an XPath expression that defines the lookup node that is used as a starting point for extracting values. If a document doesn’t match this path, the template won’t be applied.
The second is the collection property or element. The template engine will not apply this template to a document unless the document is in the right collection (or set of collections). This is a useful way to ensure that templates intended for different data sources get applied only to the correct documents. In this case, we’re requiring documents to be in the source1 collection, which we applied to our sample document when we inserted it. We’ll return to this idea later.
'use strict'
var myFirstTDE = xdmp.toJSON(
{
"template": {
"context": "/match",
"collections": ["source1"],
"rows": [
{
"schemaName": "soccer",
"viewName": "matches",
"columns": [
{
"name": "id",
"scalarType": "long",
"val": "id"
},
{
"name": "document",
"scalarType": "string",
"val": "docUri"
},
{
"name": "date",
"scalarType": "date",
"val": "match-date"
},
{
"name": "league",
"scalarType": "string",
"val": "league"
}
]
}
]
}
}
);
tde.validate(
[myFirstTDE]
);
let $my-first-TDE:=
<template xmlns="http://marklogic.com/xdmp/tde">
<context>/match</context>
<collections>
<collection>source1</collection>
</collections>
<rows>
<row>
<schema-name>soccer</schema-name>
<view-name>matches</view-name>
<columns>
<column>
<name>id</name>
<scalar-type>long</scalar-type>
<val>id</val>
</column>
<column>
<name>document</name>
<scalar-type>string</scalar-type>
<val>docUri</val>
</column>
<column>
<name>date</name>
<scalar-type>date</scalar-type>
<val>match-date</val>
</column>
<column>
<name>league</name>
<scalar-type>string</scalar-type>
<val>league</val>
</column>
</columns>
</row>
</rows>
</template>
return
tde:validate(
$my-first-TDE
)
Now that you know the template is a valid one, run the template against a document to test that it extracts the rows you expect.
'use strict'
var myFirstTDE = xdmp.toJSON(
{
"template": {
"context": "/match",
"collections": ["source1"],
"rows": [
{
"schemaName": "soccer",
"viewName": "matches",
"columns": [
{
"name": "id",
"scalarType": "long",
"val": "id"
},
{
"name": "document",
"scalarType": "string",
"val": "docUri"
},
{
"name": "date",
"scalarType": "date",
"val": "match-date"
},
{
"name": "league",
"scalarType": "string",
"val": "league"
}
]
}
]
}
}
);
tde.nodeDataExtract(
[cts.doc( "/soccer/match/1234567.json" )],
[myFirstTDE]
);
let $my-first-TDE:=
<template xmlns="http://marklogic.com/xdmp/tde">
<context>/match</context>
<collections>
<collection>source1</collection>
</collections>
<rows>
<row>
<schema-name>soccer</schema-name>
<view-name>matches</view-name>
<columns>
<column>
<name>id</name>
<scalar-type>long</scalar-type>
<val>id</val>
</column>
<column>
<name>document</name>
<scalar-type>string</scalar-type>
<val>docUri</val>
</column>
<column>
<name>date</name>
<scalar-type>date</scalar-type>
<val>match-date</val>
</column>
<column>
<name>league</name>
<scalar-type>string</scalar-type>
<val>league</val>
</column>
</columns>
</row>
</rows>
</template>
return
tde:node-data-extract(
fn:doc( "/soccer/match/1234567.xml" ),
$my-first-TDE
)
The result is below. Note that the return type from tde:node-data-extract is a map:map.
{
"/soccer/match/1234567.json": [
{
"row": {
"schema": "soccer",
"view": "matches",
"data": {
"rowid": "0",
"id": 1234567,
"document": "/soccer/match/1234567.json",
"date": "2016-01-12",
"league": "Premier"
}
}
}
]
}
{
"/soccer/match/1234567.xml": [
{
"row": {
"schema": "soccer",
"view": "matches",
"data": {
"rowid": "0",
"id": 1234567,
"document": "/soccer/match/1234567.xml",
"date": "2016-01-12",
"league": "Premier"
}
}
}
]
}
Now you know what rows will look like when you apply the template. If you’re happy with the result, insert the template. The convenience function tde.templateInsert() / tde:template-insert() will validate the template, insert it into the Schemas database, and assign the special collection “http://marklogic.com/xdmp/tde”. This will create a view, and it will cause MarkLogic to index rows from any documents matching the context.
'use strict'
var tde = require("/MarkLogic/tde.xqy");
var myFirstTDE = xdmp.toJSON(
{
"template": {
"context": "/match",
"collections": ["source1"],
"rows": [
{
"schemaName": "soccer",
"viewName": "matches",
"columns": [
{
"name": "id",
"scalarType": "long",
"val": "id"
},
{
"name": "document",
"scalarType": "string",
"val": "docUri"
},
{
"name": "date",
"scalarType": "date",
"val": "match-date"
},
{
"name": "league",
"scalarType": "string",
"val": "league"
}
]
}
]
}
}
);
tde.templateInsert(
"/test/myFirstTDE.json" ,
myFirstTDE,
xdmp.defaultPermissions(),
["TDE"]
)
import module namespace tde = "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy";
let $my-first-TDE:=
<template xmlns="http://marklogic.com/xdmp/tde">
<context>/match</context>
<collections>
<collection>source1</collection>
</collections>
<rows>
<row>
<schema-name>soccer</schema-name>
<view-name>matches</view-name>
<columns>
<column>
<name>id</name>
<scalar-type>long</scalar-type>
<val>id</val>
</column>
<column>
<name>document</name>
<scalar-type>string</scalar-type>
<val>docUri</val>
</column>
<column>
<name>date</name>
<scalar-type>date</scalar-type>
<val>match-date</val>
</column>
<column>
<name>league</name>
<scalar-type>string</scalar-type>
<val>league</val>
</column>
</columns>
</row>
</rows>
</template>
return
tde:template-insert(
"/test/my-first-TDE.xml" ,
$my-first-TDE ,
xdmp:default-permissions()
)
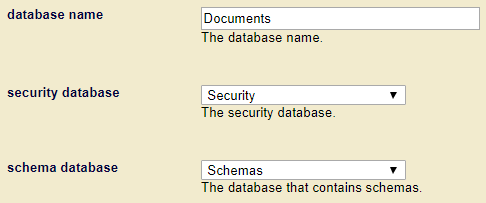
Note that tde.templateInsert() / tde:template-insert() ensures that only valid templates are inserted, and that your template is inserted into the correct database with the correct collection (“http://marklogic.com/xdmp/tde”). Your templates get stored in the configured schema database of your content database. The following image may be used as reference:
Now you can see the rows extracted from the match report without specifying a Template. Just leave out the Template parameter, and MarkLogic will apply all the Templates in scope – all the templates in the Schemas database where the context matches.
tde.nodeDataExtract( [cts.doc( "/soccer/match/1234567.json" )] )
tde:node-data-extract(
fn:doc("/soccer/match/1234567.xml")
)
Result:
{
"/soccer/match/1234567.json": [
{
"row": {
"schema": "soccer",
"view": "matches",
"data": {
"rowid": "0",
"id": 1234567,
"document": "/soccer/match/1234567.json",
"date": "2016-01-12",
"league": "Premier"
}
}
}
]
}
{
"/soccer/match/1234567.xml": [
{
"row": {
"schema": "soccer",
"view": "matches",
"data": {
"rowid": "0",
"id": 1234567,
"document": "/soccer/match/1234567.xml",
"date": "2016-01-12",
"league": "Premier"
}
}
}
]
}
When you inserted the Template in the Schemas database, you created a view. To see the view definition, run this: tde.getView("soccer", "matches").
Result (the IDs in your results will be different):
{
"view": {
"id": "8206293418083457271",
"name": "matches",
"schema": "soccer",
"viewLayout": "identical",
"columns": [{
"column": {
"id": "1695951276079343631",
"name": "id",
"scalarType": "long",
"nullable": false
}
}, {
"column": {
"id": "3697154816723268322",
"name": "document",
"scalarType": "string",
"nullable": false
}
}, {
"column": {
"id": "15119080680848561242",
"name": "date",
"scalarType": "date",
"nullable": false
}
}, {
"column": {
"id": "12176900039416751810",
"name": "league",
"scalarType": "string",
"nullable": false
}
}
]
}
}
When you created the view, you told the indexer to index rows whenever a document matches the Template. So you can now insert (and update and delete) documents, and new row entries will be created in or removed from the index (which, in case you hadn’t already guessed, is based on the Triple Index).
You can also query the new view using SQL. Switch to SQL mode in Query Console and run this:
select * from matches
Result:
soccer.matches.id soccer.matches.document soccer.matches.date soccer.matches.league 1234567 /soccer/match/1234567.json 2016-01-12 Premier
soccer.matches.id soccer.matches.document soccer.matches.date soccer.matches.league 1234567 /soccer/match/1234567.xml 2016-01-12 Premier
Data integration with templates
Before we leave this example, let’s look at what you can do when a new document arrives with the same data, but in a different format — say, with different element names, or in a different structure.
declareUpdate();
xdmp.documentInsert(
"/soccer/match/4485.json",
{
"match": {
"meta": {
"id": "4485",
"documentLocation": "/soccer/match/4485.json",
"event": {
"date": {
"day": "09",
"month": "01",
"year": "16"
},
"competition": "FA Cup"
}
},
"teams": {
"home": "West Ham United",
"away": "Woverhampton Wanderers"
},
"score": {
"home": 1,
"away": 0
},
"abstract": "West Ham progressed into the fourth round of the FA Cup.",
"report": "Nikica Jelavic scored in the 85th minute when he produced a great low-angled half-volley. ..."
}
},
xdmp.defaultPermissions(),
["TDE", "source2"]
)
xdmp:document-insert(
"/soccer/match/4485.xml",
<match id="4485">
<meta>
<document-location>/soccer/match/4485.xml</document-location>
<event>
<date>
<day>09</day>
<month>01</month>
<year>16</year>
</date>
<competition>FA Cup</competition>
</event>
</meta>
<teams>
<home>West Ham United</home>
<away>Wolverhampton Wanderers</away>
</teams>
<score>
<home>1</home>
<away>0</away>
</score>
<abstract>West Ham progressed into the fourth round of the FA Cup.</abstract>
<report>Nikica Jelavic scored in the 85th minute when he produced a great low-angled half-volley. ...
</report>
</match> ,
xdmp:default-permissions(),
("TDE", "source2")
)
Perhaps this match report came from a different application —- it also has the information we want in the view (id, document, date, league) but in different places in the document. Notice that we put it in a different collection, to reflect that it came from a different source.
To address this new format you need a new template that specifies the same view, but with different paths to the information. Create/validate/test my-second-TDE, and insert it.
'use strict'
var tde = require("/MarkLogic/tde.xqy");
var mySecondTDE = xdmp.toJSON(
{
"template": {
"context": "/match",
"collections": ["source2"],
"rows": [
{
"schemaName": "soccer",
"viewName": "matches",
"columns": [
{
"name": "id",
"scalarType": "long",
"val": "meta/id"
},
{
"name": "document",
"scalarType": "string",
"val": "meta/documentLocation"
},
{
"name": "date",
"scalarType": "date",
"val": "fn:concat('20', meta/event/date/year, '-', meta/event/date/month, '-', meta/event/date/day )"
},
{
"name": "league",
"scalarType": "string",
"val": "meta/event/competition"
}
]
}
]
}
}
);
tde.templateInsert(
"/test/mySecondTDE.json" ,
mySecondTDE,
xdmp.defaultPermissions(),
["TDE"]
);
import module "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy";
let $my-second-TDE:=
<template xmlns="http://marklogic.com/xdmp/tde">
<context>/match</context>
<rows>
<row>
<schema-name>soccer</schema-name>
<view-name>matches</view-name>
<columns>
<column>
<name>id</name>
<scalar-type>long</scalar-type>
<val>@id</val>
</column>
<column>
<name>document</name>
<scalar-type>string</scalar-type>
<val>meta/document-location</val>
</column>
<column>
<name>date</name>
<scalar-type>date</scalar-type>
<val>concat( '20', meta/event/date/year, '-', meta/event/date/month, '-', meta/event/date/day )</val>
</column>
<column>
<name>league</name>
<scalar-type>string</scalar-type>
<val>meta/event/competition</val>
</column>
</columns>
</row>
</rows>
</template>
return tde:template-insert(
"/test/my-second-TDE.xml" ,
$my-second-TDE ,
xdmp:default-permissions()
)
Now show all rows again. Let’s re-run our earlier SQL statement.
xdmp:sql('select * from matches')
soccer.matches.id soccer.matches.document soccer.matches.date soccer.matches.league 1234567 /match/1234567.json 2016-01-12 Premier 4485 /match/4485.json 2016-01-09 FA Cup
soccer.matches.id soccer.matches.document soccer.matches.date soccer.matches.league 1234567 /match/1234567.xml 2016-01-12 Premier 4485 /match/4485.xml 2016-01-09 FA Cup
You should see rows from both documents. Congratulations! You have integrated data from two sources, in two different formats, into a single view that you can query using SQL or a composable JavaScript or XQuery API. You can even make this view available to a BI tool using ODBC.
Templates that overlap
Once you get beyond your first Template, you may create Templates that overlap – you can create many Templates that apply to the same document (because the context is the same or overlapping); and you can create many Templates that populate the same view (because they apply to documents of different shapes).
Many Templates apply to one document
In the examples above, both templates have a context of “/match”. The first template expects to find the ID directly under the match. The second looks for it as a property under “meta” (JSON) or as an attribute (XML). We used separate collections to ensure that the templates were applied to the right documents. What would have happened if we hadn’t? By default, the template processor would have thrown an error trying to apply the first template to the second document, because it wouldn’t find the data it needed. This behavior can be changed by specifying invalid-values as “ignore” for each part of the template — but leaving it with the default “reject” value makes it easier to find errors.
Tip: when you are testing/debugging Templates, avoid
<invalid-values>ignore</invalid-values> since <invalid-values>reject</invalid-values> gives you helpful error messages when something is missing or invalid.Many Templates populate the same view
In the examples above, both $my-first-TDE and $my-second-TDE populate the view soccer.matches. In these examples, both Templates specify all columns of that view. If you create a new Template that specifies only some of those columns, it will create rows cells with the missing columns set to NULL. For that to work, the missing columns must be defined as nullable in all Templates.
Similarly, if you create a new Template that specifies columns that are not mentioned in other Templates for the same view, then all Templates must either define those columns as nullable (which requires you to peek into the future when creating Templates) or must define the view as <view-layout>sparse</view-layout>. <view-layout>sparse</view-layout> says “I don’t know what new columns I may specify for this view in future Templates. Allow future Templates to define new columns, and behave as if I had defined those columns as nullable in this Template.”
Summary: When you create a Template that defines a view, if you want to be able to create Templates in the future that define a different set of columns than the current (first) Template, then you must:
- Define the view as
<view-layout>sparse</view-layout>in all Templates for that view.
The default for view-layout is identical, which means that all Templates for that view must define an identical set of columns. - If there are any columns in the first Template that may not be defined in future Templates, those columns must be defined as
<nullable>true</nullable>in the first Template. - If there are any columns not defined in the first Template that will be defined in a future Template, those columns must be defined as
<nullable>true</nullable>in the future Template.
Query using SQL
Now that you’ve “extracted” rows, they are accessible via SQL, in all the usual ways – from Query Console in SQL mode; from XQuery via the xdmp:sql() function; from Server-side JavaScript using the xdmp.sql() function; and via ODBC using some tool that uses ODBC (such as a BI tool). We’ll run through simple examples of all these except the last.
SQL Query: from Query Console in SQL mode
select * from matches
SQL Query: from XQuery via the xdmp:sql() function
This is the simplest possible SQL query:
xdmp:sql('select * from matches')
Note that you can write an ad hoc SQL query in the argument to xdmp:sql(). MarkLogic 9.0-1 supports SQL92 plus some popular extensions.
But there’s more: you can also do a combination query — that is, you can run an ad hoc SQL query and only return rows where the originating document matches some cts.query. For example, if you want the id and league of every document that mentions “Dimitri Payet”, you can get it like this:
xdmp.sql(
"select id, league from matches where date > cast ('2016-01-10' as date)",
null,
null,
cts.wordQuery("Dimitri Payet")
)
xdmp:sql(
"select id, league from matches where date > cast ('2016-01-10' as date)",
(),
(),
cts:word-query("Dimitri Payet")
)
That cts:query restriction can be any cts:query — so you could restrict the contributing documents by metadata values, by a full-text search, bitemporal attributes, collection, geospatial — anything that you can express in a cts:query.
Making triples example
We can also use templates to index triples. Take a look at our next template:
var tde = require("/MarkLogic/tde.xqy");
var myTriplesTemplate =
xdmp.toJSON({
"template": {
"context": "/match",
"collections": [ "source1", "source2" ],
"vars": [
{
"name": "prefix-soccer",
"val": "'https://example.org/soccer'"
},
{
"name": "prefix-predicates",
"val": "'https://example.org/predicates/'"
},
{
"name": "home-team",
"val": "sem:iri($prefix-soccer || '/' || fn:replace(teams/home, ' ', '_'))"
},
{
"name": "away-team",
"val": "sem:iri($prefix-soccer || '/' || fn:replace(teams/away, ' ', '_'))"
},
{
"name": "doc-id",
"val": "sem:iri($prefix-soccer || xdmp:node-uri(.))"
}
],
"triples": [
{
"subject": { "val": "$doc-id" },
"predicate": {
"val":
"sem:iri($prefix-predicates || ( " +
" if (score/home eq score/away) then 'draw' " +
" else 'win' " +
"))"
},
"object": { "val": "if (score/home ge score/away) then $home-team else $away-team" }
},
{
"subject": { "val": "$doc-id" },
"predicate": {
"val":
"sem:iri($prefix-predicates || ( " +
" if (score/home eq score/away) then 'draw' " +
" else 'loss' " +
"))"
},
"object": { "val": "if (score/home ge score/away) then $away-team else $home-team" }
}
]
}
});
tde.templateInsert(
"/test/myTriplesTemplate.json" ,
myTriplesTemplate,
xdmp.defaultPermissions(),
["TDE"]
)
import module namespace tde = "http://marklogic.com/xdmp/tde" at "/MarkLogic/tde.xqy";
let $my-triples-template :=
<template xmlns="http://marklogic.com/xdmp/tde">
<context>/match</context>
<collections>
<collection>source1</collection>
<collection>source2</collection>
</collections>
<vars>
<var>
<name>prefix-soccer</name>
<val>"https://example.org/soccer"</val>
</var>
<var>
<name>prefix-predicates</name>
<val>"https://example.org/predicates/"</val>
</var>
<var>
<name>home-team</name>
<val>sem:iri($prefix-soccer || "/" || fn:replace(teams/home, " ", "_"))</val>
</var>
<var>
<name>away-team</name>
<val>sem:iri($prefix-soccer || "/" || fn:replace(teams/away, " ", "_"))</val>
</var>
<var>
<name>doc-id</name>
<val>sem:iri($prefix-soccer || xdmp:node-uri(.))</val>
</var>
</vars>
<triples>
<triple>
<subject>
<val>$doc-id</val>
</subject>
<predicate>
<val>
sem:iri($prefix-predicates || (
if (score/home eq score/away) then "draw"
else "win"
))
</val>
</predicate>
<object>
<val>
if (score/home ge score/away) then $home-team
else $away-team
</val>
</object>
</triple>
<triple>
<subject>
<val>$doc-id</val>
</subject>
<predicate>
<val>
sem:iri($prefix-predicates || (
if (score/home eq score/away) then "draw"
else "loss"
))
</val>
</predicate>
<object>
<val>
if (score/home ge score/away) then $away-team
else $home-team
</val>
</object>
</triple>
</triples>
</template>
return
tde:template-insert(
"/test/my-triples-template.xml" ,
$my-triples-template,
xdmp:default-permissions()
)
There are a couple things to notice here. First, we’re specifying both the “source1” and “source2” collections. That’s because the information we care about (for this template) is found in the same place in both formats. In this case, I could have left the collection out (thus applying to all collections), but by including them I’m future-proofing the template for the day when we get a new, non-conforming format.
Instead of specifying rows, this template specifies <triples>. Looking at the <val> elements, you’ll see that we have some XQuery source code (yes, we’re using XQuery code for the <val> element in both the JavaScript and XQuery versions of the templates). This allows us to calculate interesting values for the triples. In this case, we’re comparing the scores to record the result of the match. This ability to do calculations means that we can record facts that are not explicitly mentioned in the document. Note that we can calculate values with XQuery code for rows as well.
We’ve also introduced vars in this template. These place holders let us do more complex things once, then reuse the values. Here we’ve constructed variables with the IRIs of the home and away teams, rather than copying the string manipulation code into each part of the triple where it’s needed.
As a best practice, you should validate your templates and ensure that they retrieve the values you expect before inserting them. I’ve done that already and gone straight to the insert here.
Having inserted the template, let’s run the data extract command again:
tde.nodeDataExtract( [cts.doc( "/soccer/match/1234567.json" )] )
tde:node-data-extract( fn:doc( "/soccer/match/1234567.xml" ) )
This command specifies a document to run against, but not a template to run, so any matching template will be applied. The results give both row and triples results, showing what will go into the index.
{
"/soccer/match/1234567.json": [
{
"row": {
"schema": "soccer",
"view": "matches",
"data": {
"rownum": "1",
"id": 1234567,
"document": "/soccer/match/1234567.json",
"date":"2016-01-12",
"league":"Premier"
}
}
},
{
"triple": {
"subject": "https://example.org/soccer/soccer/match/1234567.json",
"predicate": "https://example.org/predicates/win",
"object": "https://example.org/soccer/West_Ham_United"
}
},
{
"triple": {
"subject": "https://example.org/soccer/soccer/match/1234567.json",
"predicate": "https://example.org/predicates/loss",
"object": "https://example.org/soccer/Bournemouth"
}
}
]
}
{
"/soccer/match/1234567.xml": [
{
"row": {
"schema": "soccer",
"view": "matches",
"data": {
"rownum": "1",
"id": 1234567,
"document": "/soccer/match/1234567.xml",
"date":"2016-01-12",
"league":"Premier"
}
}
},
{
"triple": {
"subject": "https://example.org/soccer/soccer/match/1234567.xml",
"predicate": "https://example.org/predicates/win",
"object": "https://example.org/soccer/West_Ham_United"
}
},
{
"triple": {
"subject": "https://example.org/soccer/soccer/match/1234567.xml",
"predicate": "https://example.org/predicates/loss",
"object": "https://example.org/soccer/Bournemouth"
}
}
]
}
In summary, Template Driven Extraction lets you put content directly into the indexes, without having to modify your document structure.