Entity Services is a way to design applications around real-world concepts, or entities, such as Customers and Orders, or Trades and Counter Parties, or Providers and Outcomes. This provides better alignment between business analysts who define the entities and the developers who combine them in application code.
Entity Services is made up of three core capabilities that work together to simplify data integration and application development with MarkLogic.
- Entity Type Model: The entity type model describes entities, their properties, and relationships to other entities. Entity Services provides a vocabulary for describing, validating, and querying entity models. Data owners and domain experts describe the semantics, or meaning, of the data and the rules that govern it using the extensible entity model.
- Persistence convention: Using the entity type model, Entity Services provides a default data model for storing and versioning entity instances, their metadata, and even the raw data from which the entities are derived. This convention is designed for extensibility to accomodate different types of data and a wide range of data governance practices.
- Code Generation APIs: Using the entity type model, Entity Services can generate code and configuration to speed up development and reduce translation errors.
In a seminal paper published in 1976, Peter Chen, the renowned computer scientist, put forward the idea of capturing information about the real world as entities and relationships. The idea was that you could use this analysis to unify multiple storage and transaction models to better represent the real world across different systems.
“A data model, called the entity-relationship model, is proposed. This model incorporates some of the important semantic information about the real world…The entity-relationship model can be used as a basis for unification of different views of data…Semantic ambiguities in these models are analyzed. Possible ways to derive their views of data from the entity-relationship model are presented.”
However, the relational model that has dominated the database industry over the last 40 years was ill suited to handle the complexities and unpredictability of real-world concepts. Instead, pragmatic data modelers have focused on what is achievable within the constraints of relational, pushing the mapping of concepts off to external ETL processing and application code. The dominance of relational over the last 40 has improved what is possible with the relational model, but has not addressed the fundamental mismatch between relational and increasingly complex concepts and interactions that developers code into software and analysts devise to run a business or achieve a mission.
The context of the data—its meaning—is stored in SharePoint or Excel or a ragged ERD printout in some DBA’s cube—everywhere (and nowhere) except for the database where the data is stored. Making sense of it within one database is difficult. Across different databases, each purpose-built for a specific application can be impossible.
What does a Customer mean? What are its defining properties? How is it related to other things that are important to my business or mission? Which systems can generate customers? How do I represent customers to my applications? How many customers do I know about? Which ones do not adhere to the rules of my business?…
Answering these questions today typically involves complex point-to-point integration to bridge different representations of the data and different interpretations of its meaning. This is brittle and expensive in today’s environment, dominated by relational databases.
With a single greenfield application, it is possible to build a data model that represents the concepts behind a particular business process. For example, in a relational database you might have Customer, Sales Orders, and Products tables to capture the fact that customers order products. From the perspective of this order fulfillment application, a customer has a shipping and a billing address and can be easily related to the orders she has placed. However, within a real organization a Customer is much more than just an address to ship sales.
That customer would have interacted with marketing programs, technical support, or might even be selling services or products back to you. In most enterprises this data is spread throughout the organization, typically in silos that handle a particular aspect of a customer. The simple customer concept above is now made up of disparate, sometimes conflicting data, whose context and meaning is trapped in database queries, application code, and outdated application specs and entity-relation diagrams (ERDs).
Entity Services with MarkLogic provides a better way to manage entities and the messy, changing data from which they are derived.
Main Points
- Modeling as documents and triples: Define a basic entity model — entities, properties, and relationships — using the out-of-the-box JSON or XML vocabulary. Extend that model with your own ontologies and query it with SPARQL.
- Conversion templates: Generate code templates from entity models to build entity instances from any source data.
- Tuple indexing: Template-driven extraction (TDE) rules to project tuples out of entity instance documents for querying from the Optic API or with SQL.
An Entity Services API reference and developer’s guide are available in the docs.
Entity Type Model
At the core of Entity Services is an entity type model, or “model” for short. The model describes concepts, like Customer, in as little or as much detail as you need. Unlike a relational schema, you do not need to model all of your data before you can load it or query it in MarkLogic. You use your model to characterize the specific parts of the data that you want to query by its canonical representation. This process is designed to be iterative, evolving as you better understand your data and requirements.
The model describes entities (“nouns”), their properties (“adjectives”), and the relationships between entities (“verbs”). For example, a Customer entity has a first name and is related to an Order, by its id. (More about how you can be more specific about the nature of the relationship later.)
Entity Services provides a JSON or XML vocabulary to describe models. This vocabulary is the bare minimum you would need in a compact, readable format. You can persist this document, just like any other JSON or XML document, in your database along with your data. The document format also lends itself to editing workflows that speak JSON or XML, for example, a browser-based model editor.
The model document format is only a convenience for quickly and compactly describing an entity model. Once a model document is persisted to a configured MarkLogic database, it is automatically converted to semantic triples. Triples are a (WC3) standard way of capturing atomic facts.
Each assertion in the model is converted to a graph of related triples. You can query these graphs with SPARQL. For example, to discover all of the entity types or infer that a customer purchases products, even though that relationship is never explicitly declared: Customers place orders, orders have line items, line items contain products.
The following is a query that catalogs all of the entity types declared in a model.
select ?s
where
{
?s ?p <https://marklogic.com/entity-services#EntityType>
}
A semantic model allows you to add your own facts to extend the built-in vocabulary. For example, the out-of-the-box model allows you to assert that a Customer is an entity type. You could add another fact to assert that all Customer types are subclasses of Party, along with Partner and Vendor types. You could then write a query across all Party types.
The entity type model not only documents the canonical entities represented in your data, but, because it is data itself, it can be queried and transformed into other artifacts. This allows a true “model-driven” workflow and a means to separate the data rules from application code. Applications are ephemeral; data is forever. Your database and governance policies should reflect that.
Use cases
Entity Services provides utilities for transforming models into application components, saving time and reducing translation errors.
- Generate code to transform source documents into canonical representations, by default wrapped in an “envelope” document to preserve the original source alongside the canonical representation.
- Generate template-drive extraction (TDE) templates to project canonical model instances out of documents into the new row index for use with the Optic API, SQL, or SPARQL.
- Generate XML Schemas to validate entity instances and provide data typing for XQuery code.
- Generate database index settings for range indexes and word lexicons. Use the Management REST API to apply these changes.
- Generate Search API options to customize the behavior of the Search API, specific to your entity model.
- Generate transformation code to translate from one version of an entity model to another, for example to handle breaking changes to an entity definition.
Integrating Running Race Data Example
The following examples use the sample data included in the Entity Services repository on GitHub. By default, the Entity Services libraries, in the es namespace, are bundled with your MarkLogic 9 installation. You will only need to access the GitHub repository to run through the examples.
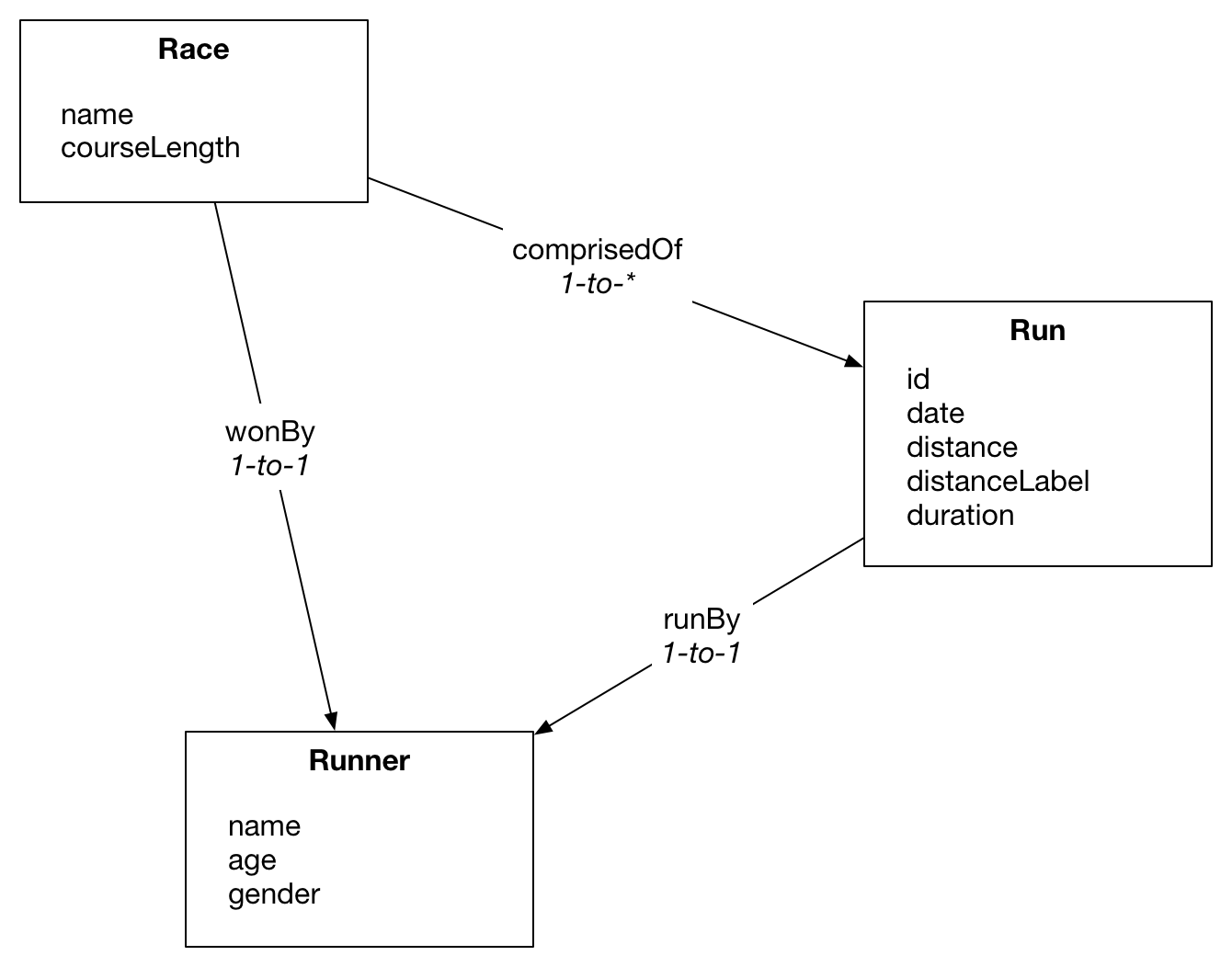
The example Entity Services implementation included in the repository covers three entities: Runner, Race, and Run, sourced from two different data sources. Conceptually, a runner participates in a run. A race is made of of many runs and has a winning runner. (The data is partially synthesized, so actual times and distances may not be entirely realistic.) You can see the raw JSON and CSV in the entity-services-examples/data/race-data and entity-services-examples/data/third-party/csv directories.
The following walk-through will create an entity type model to describe these key entities, transform the raw data to reflect the canonical model, and then query that model using the Optic API and SQL.
Setup
You will need to MarkLogic 9, git, and Java 8 to run the samples below.
- Clone the marklogic/entity-services project from GitHub.
git clone https://github.com/marklogic/entity-services.git - Navigate to the
entity-services-examplesdirectory. - In
gradle.propertiesthere, change themlUsernameandmlPasswordproperties to reflect an admin user in your environment. The admin use is only to configure the initial security settings. - From within the entity-services-examples directory (not the top-level entity-services directory), run the Gradle script to bootstrap a new environment.
./gradlew -PexampleDir=example-races mlDeploy
This bootstrapping uses Gradle and the open-source ml-app-deployer framework.
You should see three new databases in your MarkLogic instance: entity-services-content, entity-services-modules, and entity-services-schemas. Let’s put some data in there and use Entity Services to integrate it.
Staging Source Data
The raw source data for the examples is located in the data directory. It is formatted as JSON and CSV, for example, as if you had exported it from a real race tracking system. The data and business rules are simplified from what you would typically encounter in a complex enterprise integration project for the sake of illustration. However, all of these concepts will extend to larger, more sophisticated projects.
From the entity-services-examples directory run
./gradlew runExampleRaces
This will run through the entire scenario: loading both data sets, generating the transformation artifacts, and bulk transforming the raw inputs to reflect the canonical entities.
To verify what you just loaded open Query Console in your browser. From the workspace drop-down on the right, import a new workpace from races-qc.xml in the entity-services-examples directory. Run the query in the tab 01. load-report. This gives you a summary of what you just loaded. It should return something like:
Raw docs: 1354 Non raw: 1310 Race envelopes: 4 Run envelopes: 1300 Collection names angel-island csv https://marklogic.com/entity-services/models race-envelopes raw reference run-envelopes
These examples use the new Data Movement SDK to load files from the file system. However, the same concepts apply for data that you load through a REST API, mlcp, or any of the other ingest interfaces that MarkLogic provides.
The initial load puts the JSON and processed CSV, representing two different data sources, into the raw collection in the entity-services-examples-content database. You can think of this as a staging area. (You could also stage raw data into a separate database; Entity Services does not dictate a processing workflow.)
The raw data is persisted in the database, thus it is secured and indexed for discovery queries, but it is not necessarily ready to be consumed by applications. In particular, “Runs” are represented differently in the two different source systems.
In one data set a Run is captured as:
{
"Place": "12",
"Bib": "246",
"Name": "Terisa Tokarski",
"First name": "Terisa",
"Last name": "Tokarski",
"Team name": "San Francisco CA",
"Distance": "Half Marathon",
"Category": "M3034",
"Age": "32",
"Gender": "Male",
"Time": "1:44:30.8",
"Difference": "+15:02.8",
"% Back": "+16.82%",
"% Winning": "85.60%",
"% Average": "22.00%"
}
versus:
{
"id": 33,
"date": "2015-04-09",
"distance": 9.8,
"distanceLabel": "9.8 miles",
"duration": 91.14,
"runByRunner": "Floretta"
}
extracted from a different system.
Both convey similar information about a the real-world concept of a “Run” and the differences provide important context about how the data is used upstream. We don’t want to lose this context just so we can get a harmonized view.
A person reading this data could figure out that "duration": 91.14 and "Time": "1:44:30.8" both indicate the amount of time it took to complete a particular run. However, computers (today, at least) don’t have enough context to connect those two keys, not to mention interpret the values as time durations. As such, we need to tell the database how to treat duration in one data set the same as Time in the other, such that we can query unambiguously for the concept of how long a run took, rather than requiring every query be aware of the specifics of the source systems.
Before we write any code, though, it is important to document the meaning of the data. Entity Services provides a set of tools and techniques to:
- Capture assertions about your data,
- Manage those assertions along with the data they describe, using the same security and governance policies, and
- Use that context to build better applications, faster.
Creating a Model
Now that you have loaded the source data as is, you can begin mapping it to the business entities that it represents. For our simple data and data models, the modeling step may feel like extra, unnecessary work. However, for more complex and messy data, the rigor of the modeling phase is vital. One important benefit that an entity type model brings is the separation between the rules that define the real-world concepts and physical representations in code and data. The entity type model allows a domain expert to specify the entities independent of any particular application. The model itself is data and thus can be used by developers to implement business logic in code.
Core Aspects
Entity Services provides a document format to describe entity type models. This JSON or XML representation captures the three core aspects of the model:
- Entity types
- Entity properties
- Relationships between entities
Below is the fully-formed model for the example race data. In practice, you would probably iterate over this model many times as you understand your data and business requirements. MarkLogic makes it possible to co-locate raw data along with transformed data and the models that describe them. This means that you can begin getting value out of your data even before you have modeled it and manage and govern all aspects of your data throughout its lifecycle.
{
"info": {
"title": "Race",
"version": "0.0.1",
"baseUri": "https://grechaw.github.io/entity-types",
"description":"This schema represents a Runner who runs Runs and has the potential of winning Races. We'll start with this entity-type, then decide on and populate instances, tie the data in with an external RDF-based model, and query it. There are interesting problems with the bare-bones approach in this entity-type."
},
"definitions": {
"Race": {
"properties": {
"name": {
"datatype": "string",
"description":"The name of the race."
},
"comprisedOfRuns": {
"datatype": "array",
"description":"An array of Runs that comprise the race.",
"items":{
"$ref": "#/definitions/Run"
}
},
"wonByRunner": {
"$ref":"#/definitions/Runner",
"description":"The (single) winner of the race. (rule) Should match the run of shortest duration."
},
"courseLength": {
"datatype":"decimal",
"description":"Length of the course in a scalar unit (decimal miles)"
}
},
"primaryKey":"name"
},
"Run": {
"properties": {
"id": {
"datatype": "string",
"description":"A unique id for the run. maybe date/runByRunner (assumes one run per day per person)"
},
"date": {
"datatype": "date",
"description":"The date on which the run occurred."
},
"distance": {
"datatype": "decimal",
"description":"The distance covered, in a scalar value."
},
"distanceLabel": {
"datatype": "string",
"description":"The distance covered, in a conventional notation."
},
"duration": {
"datatype": "dayTimeDuration",
"description":"The duration of the run."
},
"runByRunner": {
"$ref": "#/definitions/Runner"
}
},
"primaryKey":"id",
"required":["date","distance","duration","runByRunner"],
"rangeIndex":["date", "distance", "duration", "runByRunner"]
},
"Runner": {
"properties": {
"name": {
"datatype": "string",
"description":"The name of the runner. In this early model, unique and a PK."
},
"age": {
"datatype": "int",
"description":"age, in years."
},
"gender" : {
"datatype" : "string",
"description": "The gender of the runner (for the purposes of race categories.)"
}
},
"primaryKey": "name",
"wordLexicon": ["name"],
"required": ["name", "age"]
}
}
}
The model description covers the basics of entities, properties, and relationships. This document is designed to be the starting point of your entity modeling. The modeling vocabulary was inspired by Swagger and the Open API Initiative.
The bootstrapping that you did above saved the model into the entity-services-examples-content database, the same one in which we loaded the source data earlier. This allows you to easily query across the raw data and the models, for example to build model-driven transformations.
Also notice how the model document is loaded into the https://marklogic.com/entity-services/entity-types collection. This is a special collection. Documents in this collection that conform to the model descriptor specification above will automatically be processed into semantic triples as they are inserted or updated. You can extend the core model with your own triples.
Generating Components
There are many benefits to loading the source data as is: It can be secured and queried without losing any of its original context. This is incredibly valuable for data whose structure and values are not fully understood or are changing. Being able to manage and query this data without having to do up-front modeling is a key benefit of MarkLogic. However, by projecting the source data through the lens of a well specified model, you can ensure consistency, centralizing the meaning of the data into a well defined set of assertions, rather than application code or requirements specified in a Word document.
Using the model you loaded earlier, Entity Services can generate model-driven components useful for development. The following example generates a conversion module, an extraction template (TDE), an XML Schema, and database configuration that support the race model defined above. It saves these artifacts to the file system, in the same place the Gradle bootstrap used above.
Thus, ../gradlew mlDeploy will deploy these to the correct place in MarkLogic—code to the modules database, schema to the schemas database, and configuration applied to the appropriate management interface.
- es:instance-converter-generate Generates XQuery code that convert raw source data into canonical entity representations, wrapped in an envelope document along with the raw source. The code is a starting point and is intended to be customized to suit the specific business rules and transformation logic for your particular data. Like any XQuery library, the generated code can be imported into a Server-Side JavaScript module and invoked as JavaScript.
- <es:database-properties-generate Generates database index configuration that can be fed to the Management REST API.
- <es:extraction-template-generate Generates a TDE template that projects entities as rows into the row index. This is useful for querying entities with the Optic API or SQL.
- es:schema-generate Generates an XML Schema that validates entity instances generated as XML from
es:instance-converter-generate. The generated schema only reflects the information captured in the model. If youres:instance-converter-generateimplementation changes how the canonical instances are materialized you’ll need to customize your schema as well. - <es:search-options-generate Generates default configuration for the Search API.
- es:version-translator-generate Generates XQuery code to translate entity instances between two versions of the type model.
Generating Canonical Entities from Raw Sources
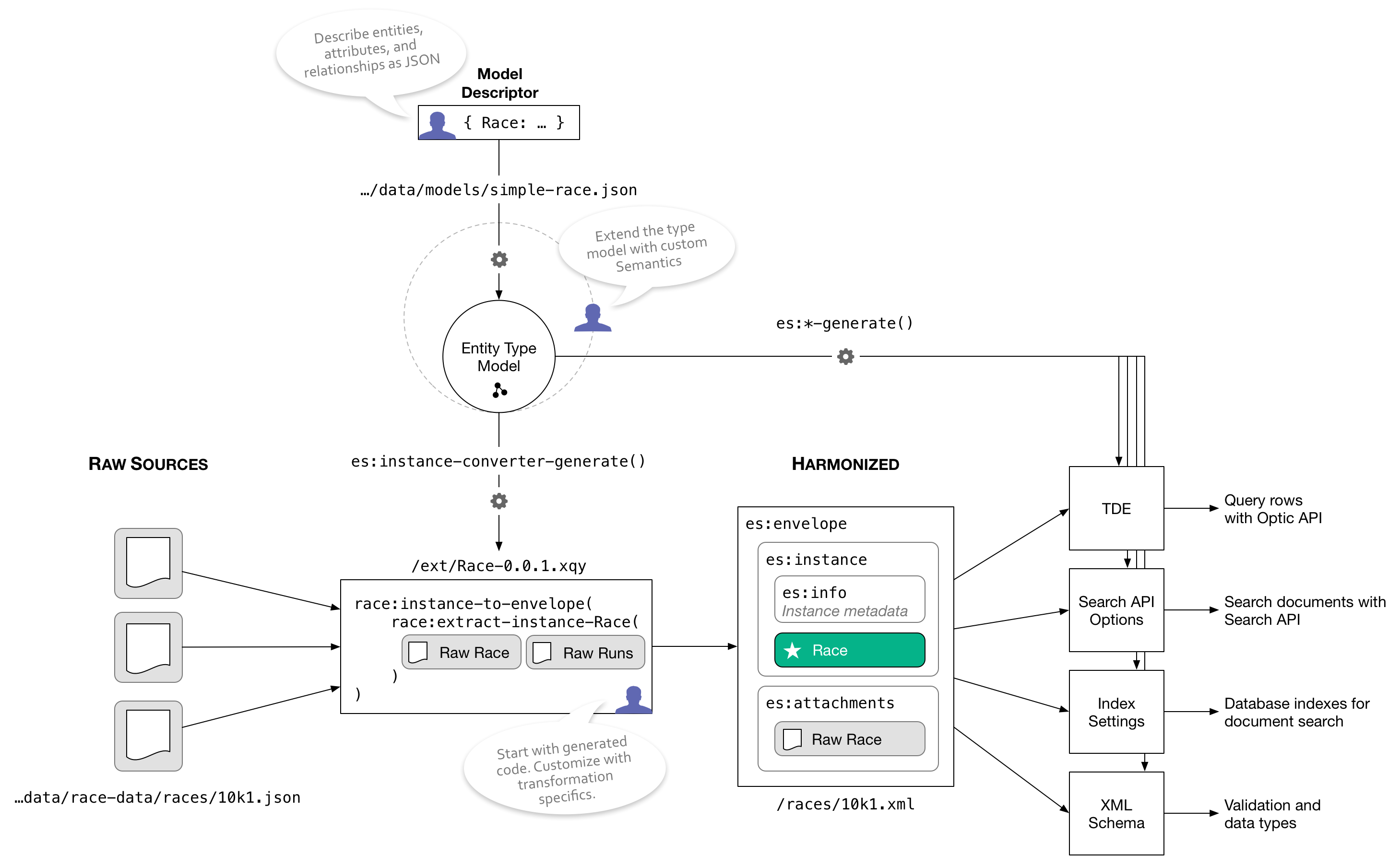
For example, the es:instance-converter-generate($d) function generates the XQuery module below. This code transforms source data into a canonical representation based on the model and wraps the harmonized instance with the source data in an “envelope” wrapper document. In a real-world application, you would change the code in the race:extract-instance-Race() function to accommodate the specific transformation logic that your source data requires.
The default assumes simple field mappings. More realistic data might require reformatting values, merging multiple source documents, looking up values from other documents/entities, or any of the other sophisticated transformation tasks that MarkLogic handles with aplomb. The generated code will run as is, but it is designed as a template and intended to be modified. It provides some generally useful patterns, but is by no means the only way to leverage an entity type model in MarkLogic.
xquery version "1.0-ml";
(: This module was generated by MarkLogic Entity Services.
: The source entity type document was Race-0.0.1
:
: Modification History:
: Generated at timestamp: 2016-04-13T13:41:03.235074-07:00
: Modified to lookup/denormalize runner into run, and source from JSON raw,
: For EA-3, revised to conform to new styles, enhancements, and bugfixes.
: Persisted by Charles Greer
: Date: 2016-07-20
:)
module namespace race = "https://grechaw.github.io/entity-types#Race-0.0.1";
import module namespace functx = "https://www.functx.com" at "/MarkLogic/functx/functx-1.0-nodoc-2007-01.xqy";
import module namespace es = "https://marklogic.com/entity-services"
at "/MarkLogic/entity-services/entity-services.xqy";
(:~
: Creates a map:map representation of an entity instance from some source
: document.
: @param $source-node A document or node that contains data for populating a Race
: @return A map:map instance that holds the data for this entity type.
:)
declare function race:extract-instance-Race(
$source-node as node()
) as map:map
{
let $runner-name := string($source-node/wonByRunner)
let $runnerDoc := cts:search( collection("raw"), cts:json-property-value-query("name", $runner-name))
let $_ := xdmp:log(("WINNER", $runner-name, $runnerDoc))
return json:object()
(: This line identifies the type of this instance. Do not change it. :)
=>map:with('$type', 'Race')
(: This line adds the original source document as an attachment.
: If this entity type is not the root of a document, you should remove this.
: If the source document is JSON, you should wrap the $source-node in xdmp:quote()
: because you cannot preserve JSON nodes with the XML envelope verbatim.
:)
=> map:with('name', xs:string($source-node/name))
(: The following property is a local reference. :)
=>es:optional('comprisedOfRuns', race:extract-array($source-node/comprisedOfRuns, function($x) { json:object()=>map:with("$type", "Run")=>map:with("$ref", xs:string($x)) } ))
(: The following property is a local reference. :)
=>es:optional('wonByRunner', race:extract-instance-Runner($runnerDoc))
=>es:optional('courseLength', xs:decimal($source-node/courseLength))
=>map:with('$attachments', xdmp:quote($source-node))
};
(:~
TODO make descriptive comment for extract-instance-Run
:)
declare function race:extract-instance-Run(
$source-node as node()
) as map:map
{
let $runner-name := string($source-node/runByRunner)
let $runnerDoc := cts:search( collection("raw"), cts:json-property-value-query("name", $runner-name))
return
json:object()
=>map:with('$type', 'Run')
=>map:with('$attachments', xdmp:quote($source-node))
=>map:with('id', xs:string($source-node/id))
=>map:with('date', xs:date($source-node/date))
=>map:with('distance', xs:decimal($source-node/distance))
=>map:with('distanceLabel', xs:string($source-node/distanceLabel))
=>map:with('duration', functx:dayTimeDuration((), (), xs:decimal($source-node/duration), ()))
=>map:with('runByRunner', race:extract-instance-Runner($runnerDoc))
};
(: modifying this one for JSON inputs, each a separate file :)
declare function race:extract-instance-Runner(
$source-node as node()
) as map:map
{
json:object()
=>map:with('$type', 'Runner')
=>map:with('name', xs:string($source-node/name))
=>map:with('age', xs:int($source-node/age))
=>map:with('gender', xs:string($source-node/gender))
};
(:~
: This function includes an array if there are items to put in it.
: If there are no such items, then it returns an empty sequence.
:)
declare function race:extract-array(
$path-to-property as item()*,
$fn as function(*)
) as json:array?
{
if (empty($path-to-property))
then ()
else json:to-array($path-to-property ! $fn(.))
};
(:~
: Turns an entity instance into an XML structure.
: This out-of-the box implementation traverses a map structure
: and turns it deterministically into an XML tree.
: Using this function as-is should be sufficient for most use
: cases, and will play well with other generated artifacts.
: @param $entity-instance A map:map instance returned from one of the extract-instance
: functions.
: @return An XML element that encodes the instance.
:)
declare function race:instance-to-canonical-xml(
$entity-instance as map:map
) as element()
{
(: Construct an element that is named the same as the Entity Type :)
element { map:get($entity-instance, "$type") } {
if ( map:contains($entity-instance, "$ref") )
then map:get($entity-instance, "$ref")
else
for $key in map:keys($entity-instance)
let $instance-property := map:get($entity-instance, $key)
where ($key castable as xs:NCName and $key ne "$type")
return
typeswitch ($instance-property)
(: This branch handles embedded objects. You can choose to prune
an entity's representation of extend it with lookups here. :)
case json:object+
return
for $prop in $instance-property
return element { $key } { race:instance-to-canonical-xml($prop) }
(: An array can also treated as multiple elements :)
case json:array
return
for $val in json:array-values($instance-property)
return
if ($val instance of json:object)
then element { $key } { race:instance-to-canonical-xml($val) }
else element { $key } { $val }
(: A sequence of values should be simply treated as multiple elements :)
case item()+
return
for $val in $instance-property
return element { $key } { $val }
default return element { $key } { $instance-property }
}
};
(:
: Wraps a canonical instance (returned by instance-to-canonical-xml())
: within an envelope patterned document, along with the source
: document, which is stored in an attachments section.
: @param $entity-instance an instance, as returned by an extract-instance
: function
: @return A document which wraps both the canonical instance and source docs.
:)
declare function race:instance-to-envelope(
$entity-instance as map:map
) as document-node()
{
document {
element es:envelope {
element es:instance {
element es:info {
element es:title { map:get($entity-instance, '$type') },
element es:version { "0.0.1" }
},
race:instance-to-canonical-xml($entity-instance)
},
element es:attachments {
map:get($entity-instance, "$attachments")
}
}
}
};
The default transformation logic defined in es:instance-converter-generate, materializes canonical representations of entities, wraps them in an envelope XML document (in the https://marklogic.com/entity-services namespace), and attaches the raw source document as well.
This allows you to use any of MarkLogic’s query capabilities to find data from the canonical data, the raw data, or both. The envelope pattern also provides an extensible means to track other metadata about the entity, for example, its provenance.
Why is it necessary to generate canonical representations of the entities?
It is not necessary to materialize canonical forms of the entities. Application code could rewrite a query against the entity type model to negotiate however the source data is stored. (Or do away with a fixed model altogether.)
That would provide flexibility to store your data in whatever form is convenient, resolving it to a model at runtime. While possible, this approach has several drawbacks:
- Rewriting queries and mapping/joining/projecting at runtime impose extra work, potentially slowing down queries.
- It also means your developers need to be aware of both source and canonical representations in order to write any queries against the logical entities.
- Most importantly, though, materialization allows you to keep an accurate history of your data. As your data changes, you can store the actual data before and after the change along with the metadata about how and why the change was made all together. Queries can access any or all of those aspects.
By materializing canonical entities, developers can use all of MarkLogic’s existing query capabilities against the entity instances themselves. The materialization logic only needs to happen at ingest (or update) time, likely as part of a larger data processing workflow.
In this example, a Java application uses the Data Movement SDK to apply the transformation to the raw source documents, storing the results into the the race-envelopes and run-envelopes collections.
/*
* Copyright 2016 MarkLogic Corporation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.marklogic.entityservices.examples.race;
import java.io.IOException;
import com.marklogic.entityservices.examples.CodeGenerator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* Runs the load methods for entity services, rdf, and json instances.
*/
public class ExamplesLoader {
private static Logger logger = LoggerFactory.getLogger(ExamplesLoader.class);
public static void main(String[] args) throws IOException, InterruptedException {
AsIsLoader loader = new AsIsLoader();
loader.loadAsIs();
CSVLoader integrator = new CSVLoader();
integrator.go();
logger.info("Starting harmonize");
Harmonizer harmonizer = new Harmonizer();
harmonizer.harmonize();
harmonizer.secondSourceHarmonize();
logger.info("Starting translate of Races");
Translator translator = new Translator();
translator.translate();
}
}
And the actual harmonization logic, orchestrated in Java,
/*
* Copyright 2016 MarkLogic Corporation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.marklogic.entityservices.examples.race;
import com.marklogic.client.document.ServerTransform;
import com.marklogic.client.query.StructuredQueryBuilder;
import com.marklogic.client.query.StructuredQueryDefinition;
import com.marklogic.client.datamovement.ApplyTransformListener;
import com.marklogic.client.datamovement.JobTicket;
import com.marklogic.client.datamovement.QueryBatcher;
import com.marklogic.entityservices.examples.ExamplesBase;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
/**
* Created by cgreer on 8/25/16.
*/
public class Harmonizer extends ExamplesBase {
private static Logger logger = LoggerFactory.getLogger(Harmonizer.class);
public void harmonize() throws InterruptedException {
StructuredQueryBuilder qb = new StructuredQueryBuilder();
StructuredQueryDefinition qdef = qb.collection("raw");
ServerTransform ingester = new ServerTransform("ingester");
ApplyTransformListener listener = new ApplyTransformListener().withTransform(ingester)
.withApplyResult(ApplyTransformListener.ApplyResult.IGNORE).onSuccess(inPlaceBatch -> {
logger.debug("Batch transform SUCCESS");
}).onBatchFailure((inPlaceBatch, throwable) -> {
// logger.warn("FAILURE on batch:" + inPlaceBatch.toString()
// + "\n", throwable);
// throwable.printStackTrace();
System.err.println(throwable.getMessage());
System.err.print(String.join("\n", inPlaceBatch.getItems()) + "\n");
});
QueryBatcher queryBatcher = moveMgr.newQueryBatcher(qdef).withBatchSize(100)
.withThreadCount(5).onUrisReady(listener).onQueryFailure(exception -> {
logger.error("Query error");
});
JobTicket ticket = moveMgr.startJob(queryBatcher);
queryBatcher.awaitCompletion();
moveMgr.stopJob(ticket);
}
public void secondSourceHarmonize() throws InterruptedException {
StructuredQueryBuilder qb = new StructuredQueryBuilder();
StructuredQueryDefinition qdef = qb.collection("raw", "csv");
ServerTransform ingester = new ServerTransform("ingester-angel-island");
ApplyTransformListener listener = new ApplyTransformListener().withTransform(ingester)
.withApplyResult(ApplyTransformListener.ApplyResult.IGNORE).onSuccess(inPlaceBatch -> {
logger.debug("batch transform SUCCESS");
}).onBatchFailure((inPlaceBatch, throwable) -> {
logger.error("FAILURE on batch:" + inPlaceBatch.toString() + "\n", throwable);
//System.err.println(throwable.getMessage());
//System.err.print(String.join("\n", inPlaceBatch.getItems()) + "\n");
});
QueryBatcher queryBatcher = moveMgr //
.newQueryBatcher(qdef) //
.withBatchSize(100) //
.withThreadCount(5) //
.onUrisReady(listener) //
.onQueryFailure(exception -> {
logger.error("Query error");
});
JobTicket ticket = moveMgr.startJob(queryBatcher);
queryBatcher.awaitCompletion();
moveMgr.stopJob(ticket);
}
}
Running the simplified bulk transformation app, yields Run and Race document types, with Runner entities denormalized into the Run documents.
Indexing and querying entities as rows
Because entities, by default, are materialized as documents, you can use all of MarkLogic’s query capabilities against them directly, such the Search API or JSearch. As of MarkLogic 9, you can also index and query documents as rows.
As you saw above, Entity Services can generate an extraction template (TDE) from an entity type model. The template tells the indexer how to project rows from documents. Because Entity Services can drive the entity materialization, it is also able to programmatically generate a TDE from the entity type model.
You can verify the TDE that you generated and loaded into the entity-services-examples-schemas database with the tde:node-data-extract() function.
(: Using database entity-services-examples-content :)
xquery version "1.0-ml";
import module namespace es = "https://marklogic.com/entity-services" at "/MarkLogic/entity-services/entity-services.xqy";
(: this is a manual run of tde functionality to verify generated extraction tempaltes :)
let $tde := xdmp:eval('fn:doc("/Race-0.0.1.tdex")', (), map:entry("database", xdmp:database("entity-services-examples-schemas")))
let $doc := (//es:instance/Run/id/root())[1]
let $extract := tde:node-data-extract($doc, xdmp:unquote($tde)/node())
return $extract
The above report lists the rows the TDE matches in your database. This is a handy technique for verifying that your (generated) TDE is, in fact, extracting the rows you expect.
{
"/runs//entity-services-examples/example-races/data/third-party/csv/2016-angel-island.csv-30.xml": [
{
"row": {
"schema": "Race",
"view": "Run",
"data": {
"rownum": "1",
"id": "540",
"date": "2016-07-23",
"distance": 13.1,
"distanceLabel": "Half Marathon",
"duration": "PT1H57M31.2S",
"runnerName": "Lara Louden",
"runnerAge": 41,
"runnerGender": "Male"
}
}
},
{
"triple": {
"subject": "https://grechaw.github.io/entity-types/Race-0.0.1/Runner/Lara%20Louden",
"predicate": "https://www.w3.org/1999/02/22-rdf-syntax-ns#type",
"object": "https://grechaw.github.io/entity-types/Race-0.0.1/Runner"
}
},
{
"triple": {
"subject": "https://grechaw.github.io/entity-types/Race-0.0.1/Runner/Lara%20Louden",
"predicate": "https://www.w3.org/2000/01/rdf-schema#isDefinedBy",
"object": {
"datatype": "https://www.w3.org/2001/XMLSchema#anyURI",
"value": "/runs//entity-services-examples/example-races/data/third-party/csv/2016-angel-island.csv-30.xml"
}
}
}
]
}
Querying with the Optic API
MarkLogic 9 provides an API for querying the row index relationally. The Optic API is a fluent JavaScript interface that provides a relational lens through which you can query the row index. It represents a super-set of SQL and provides a nice, developer-friendly interface for building queries and aggregates.
Recall that the TDE above extracts rows from the entities that we stored as XML documents in the database. Using the Optic API, you can write sophisticated queries over these rows. Because the rows are stored in the indexes and distributed among data nodes in a MarkLogic cluster, most queries can be parallelized and evaluated directly out of the indexes.
The following two examples give you a brief taste of what is possible with the Optic API.
import module namespace op = "https://marklogic.com/optic" at "/MarkLogic/optic.xqy";
let $rv := op:from-view("Race", "Race")
let $join-table := op:from-view("Race", "Race_comprisedOfRuns")
let $joined := op:join-inner($rv,
$join-table,
op:on(op:view-col("Race","name"), op:view-col("Race_comprisedOfRuns", "name")))
let $final-join :=
op:join-inner($joined, op:from-view("Race", "Run"),
op:on("comprisedOfRuns", "id"))
=>op:order-by(op:view-col("Race", "name"))
return $final-join=>op:result()
Querying with SQL
Finally, in addition to the Optic API, you can use standard SQL to query the rows extracted into the row index. For example, all “Half Marathon One” races,
-- USE entity-services-examples-content; SELECT Race.name, Race.wonByRunner, Race.courseLength, Run.id, Run.distance, Run.duration, Run.runnerName, Run.runnerAge, Run.runnerGender FROM Race JOIN Race_comprisedOfRuns AS r ON Race.name = r.name JOIN RUN ON r.comprisedOfRuns = Run.id ORDER BY Run.duration
or counts of runs grouped by distance:
-- USE entity-services-examples-content; SELECT distance, count(*) FROM Race.Run GROUP by distance ORDER by distance DESC