Introduction
The Optic API’s processing model enables you, the developer, to query and process a variety of modern information models within an intuitive “pipeline” framework while leveraging the best aspects of traditional data processing concepts. In so doing, Optic abstracts away the underlying implementation details, letting you focus on transforming information into value.
The Optic API lets you query any data model within MarkLogic then process it in an independent, row-and-column-based data space. This way, you can acquire document, graph, and tabular data views, then join, filter, sort, and select results in a straightforward, consistent manner.
A Single Data Space
All queries start by accessing a data source. Optic’s primary data accessors use the entire range of indexes available within MarkLogic (universal, element, field, geospatial, path, range and triple indexes, and the lexicons) and produce a row sequence as their result:
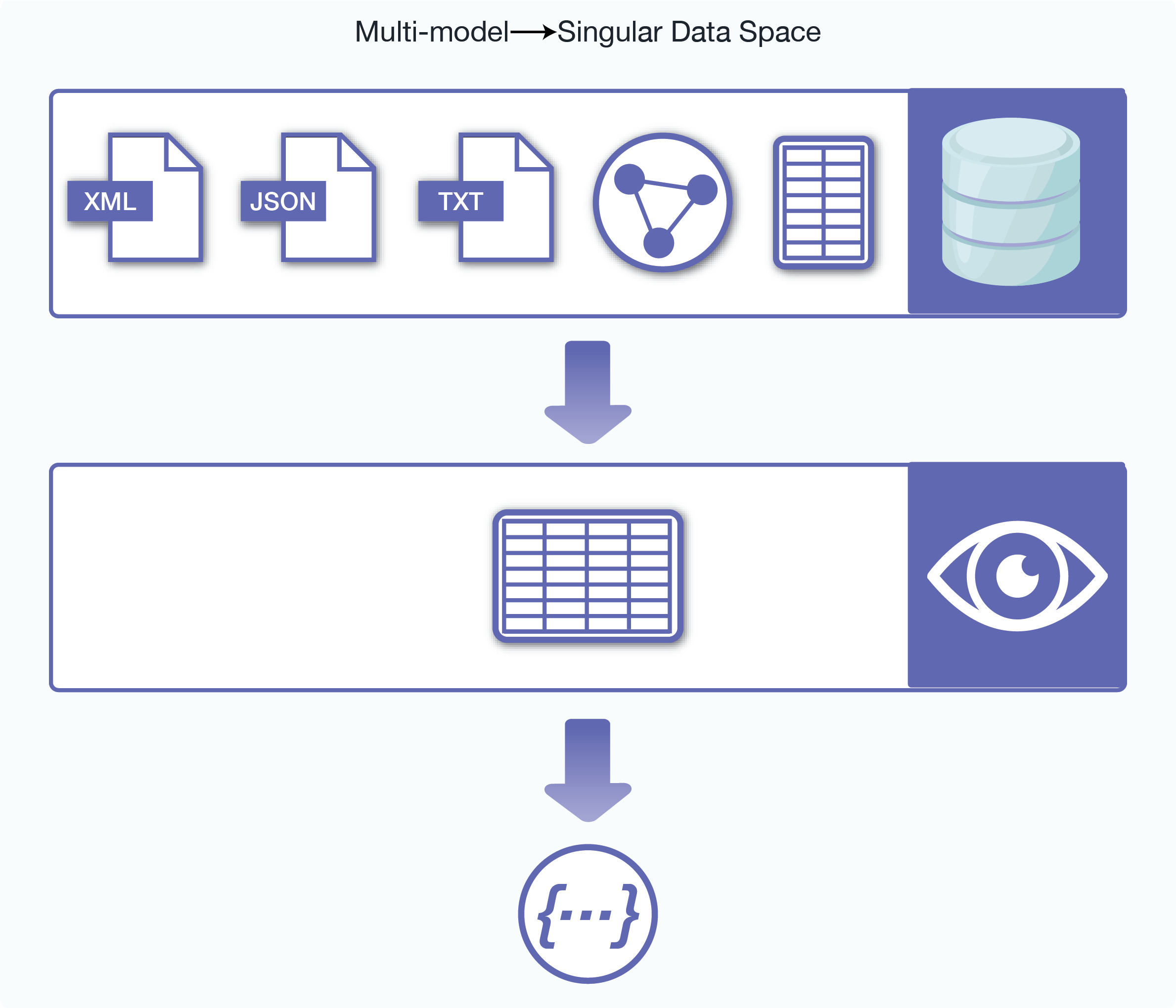
The row sequence, with its table-like rows and columns, was chosen because it is both the most convenient structure within which to process multi-model information and the most accessible concept for anyone approaching the Optic API for the first time—especially for those familiar with relational database tables.
Each row represents a single result, with its columns containing both the actual data retrieved plus any metadata relevant to that result. A column can contain simple types like strings, dates, and numbers as well as complex types like nodes and objects—in fact any of the MarkLogic Server Data Types.
Optic then processes the row sequence from the data accessor by applying various operators in a cumulative manner to modify and manipulate the rows and the information they contain.
Query Pipelines
Think of the process of constructing an Optic query as building a pipeline through which the row sequence is passed, each operator applying its modifications then passing the results on, accumulating in a final result:
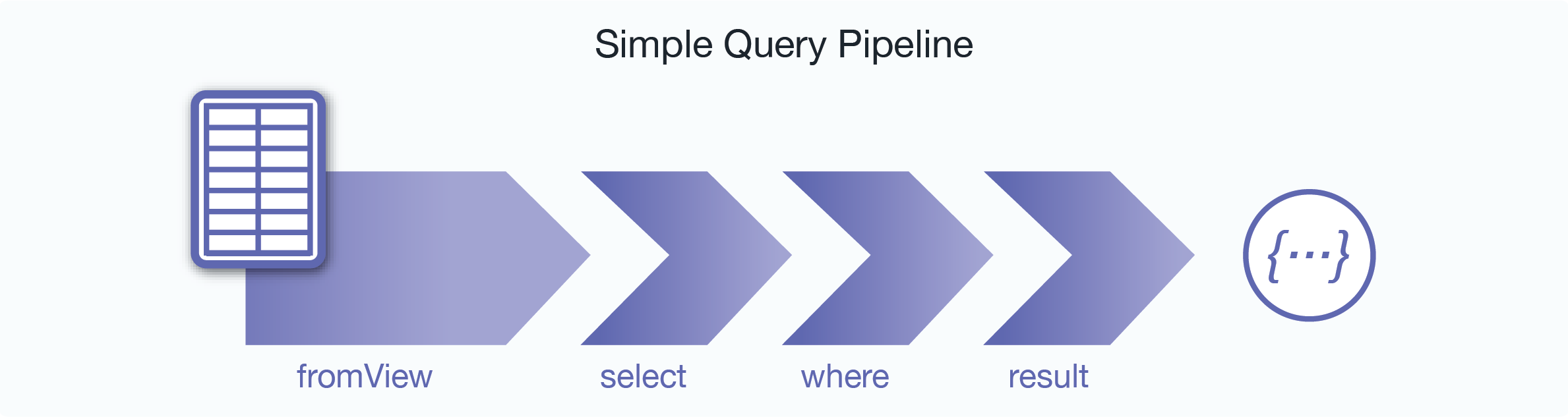
Optic, as an API, is a set of functions. These functions are bound to both the JavaScript and XQuery scripting languages that MarkLogic supports. Chaining together the function calls is what creates the pipeline effect. This chaining is achieved through the language binding’s respective function “chaining” features:
op.fromView('Finserve', 'Trades')
.select('tradeId')
.where(op.gt(op.col('tradeId'), '0001'))
.result()
op:from-view('Finserve', 'Trades')
=> op:select('tradeId')
=> op:where(op:gt(op:col('tradeId'), '0001'))
=> op:result()
For XQuery, read Arrow Operator to learn about the XQuery arrow operator.
Processing the Pipeline
In abstract terms, a pipeline is a linear sequence of steps, of modules, that perform a processing function on their input and return the altered results as output. This framework of multiple steps and multiple sources feeding into a pipeline allows the simple construction of complex queries.
The Optic API utilizes this principle, applying a sequence of relational-style operations to the rows and columns of the input row sequence. These are the basic functions used in an Optic query:
- All data accessor functions produce an output row sequence.
- All operator functions take an input row sequence and produce an altered output row sequence. Composing operators allow two input row sequences and produce one output row sequence.
- All expression functions are built-in functions that process column values.
- All iterator functions manipulate or provide access to the underlying query plan that tells the Optic engine how to execute the query.
Metadata Columns
Metadata columns, some hidden by default, are also returned with results to provide extra information. Here are two common metadata columns:
- result relevancy: a value indicating how relevant a particular result row is with respect to the query. For example, in a full-text search, a row from a document containing more instances of the searched string would have a higher result relevancy than one with fewer, leading to returning more useful and actionable results.
- fragment identifier: an internal identifier that links the results to its related document. Because MarkLogic is a document database, knowing which document contains the data in the row currently being processed is sometimes necessary and often useful. For example, when joining complex queries together, it is the fragment identifier—combined with the URI lexicon or other query results—that provides the key to joining such queries.
Query Plans
From your perspective as a developer, you are visualizing the construction of a query-processing pipeline that links functions together. In reality, the API functions are constructing a “plan” of how to execute the query pipeline.
It is important to understand this because, as well as directly executing the plan to get results, you can
- View the Optic Execution Plan for diagnostic and debugging purposes.
- Serialize an Optic query for Exporting and Importing as a JSON document that can be persisted in the database and/or used as a REST API payload to the search services.
- Generate Query-Based Views (QBVs), which can then be referenced as any other views.
Query Execution
Executing the plan produces the final result: a row sequence containing the culmination of all the processing steps in the pipeline. It is important to know that the pipeline that you construct is not necessarily the pipeline that Optic executes. The underlying query optimizer can look for alternative solutions, manipulating the plan to optimize it on the principal of cost-based analysis. Optic will attempt to find a solution that minimizes memory usage and maximizes performance.
In Summary
Using the familiar concepts of the row sequence as its common data space and the pipeline as its processing model, the Optic API enables you to accomplish the kind of advanced search capabilities difficult to realize with conventional and disparate data repositories.