Prelude
When Google first introduced their Knowledge Graph in 2012, it was hailed as an advancement that “could change search forever.”1 Before Knowledge Graph, users searching for “Abraham Lincoln” expected no more than a list of web pages mentioning the term “Abraham Lincoln”, ranked by relevancy. Knowledge Graph, building on the Linked Open Data work, provides facts about Abraham Lincoln alongside the usual Google search results. Indeed, many of us now take for granted how our search results are ‘smart’. As humans, we interact with persons, places, or things. Therefore, it is unsurprising that when we search, we are often looking for information about real-world entities rather than pure textual, keyword-matching queries. We are searching for the underlying semantic (with a little ‘s’2) meaning we attach to Abraham Lincoln as the name of a past U.S. President and want to know facts about him — not just for the text strings of ‘Abraham’ and ‘Lincoln’ occurring frequently in a document.
Semantics (with a big ‘S’3) gives context and meaning to real-world information. It defines the relationships between people, places, and things that the average person knows and understands but in a form that computers can process. For example, semantic data might describe Kazakhstan as being a country, located in Central Asia, and with a population of 17 million. Each fact about Kazakhstan can be defined as a semantic triple that includes a subject, predicate, and object (e.g. “Kazakhstan,” “has population,” and “17 million”). These triples interconnect to form a semantic graph of related information.
MarkLogic’s Semantics capabilities provide a way for enterprises to build search applications that bring back ‘smart’ results beyond the traditional keyword-match results. While Semantics has a broad set of use cases beyond search, in this recipe, we’ll focus on a common use case for Semantics as a way to implement infoboxes when building search applications.
The goal of this recipes is to:
- Generate discussion on ways to use MarkLogic’s Semantics features
- Provide material that makes it easier for developers (who are new to Semantics) to build Semantics applications
Please note we assume a few details about the readers of our recipe:
- …that you are a developer with at least a basic understanding of JavaScript
- …that you have at least a basic understanding of MarkLogic, but are relative ‘newbies’ to MarkLogic’s Semantic capabilities (you may want to conquer Semantics Hello World, at least)
- …that you have at least an elementary understanding of SPARQL, RDF, and RDFS (for a list of resources, refer to Getting Started with Semantics)
Introduction
Use Case
Using Semantics, we want to build a search application such that when a user searches for a country (e.g. Kazakhstan), the user is presented with an ‘infobox’ that contains a bunch of facts (e.g. short summary of Kazakhstan) related to the search term. Assume the facts are stored as managed or unmanaged triples in MarkLogic. Alongside the infobox, the search will also return results of documents that contain the seed search term (similar to Google).
An example application for this use case is a search application used by researchers who are looking for economic and development research studies conducted by the World Bank in certain countries; an infobox on the right-hand side would provide key pieces of high-level information about the country in question.
Other Applications
Other problems/examples that this use case could be applied to include….
- A search application for drug research studies, where an infobox is provided for the drug and/or drug compound being searched
- A search application for cooking recipes, where an infobox with nutrition information is provided when a user searches for a specific ingredient
The Recipe
Strategy
For the recipe, documents in the database are first pre-processed and “annotated” with relevant metadata; we will refer to this metadata as annotations. For example, we may enrich documents with annotations regarding topics or countries that are related to the document’s content.
When a user types a search term into the search box and clicks the Search button, a traditional search query is fired off, and the results are all documents that contain that keyword term. Then, certain document annotations in this result set are ‘picked up’ and are fed as parameters into SPARQL queries. These SPARQL queries then return triples that are used to construct infoboxes.
Hence, the search query first returns document results, and then the contents of those results are queried to generate infoboxes using Semantics.
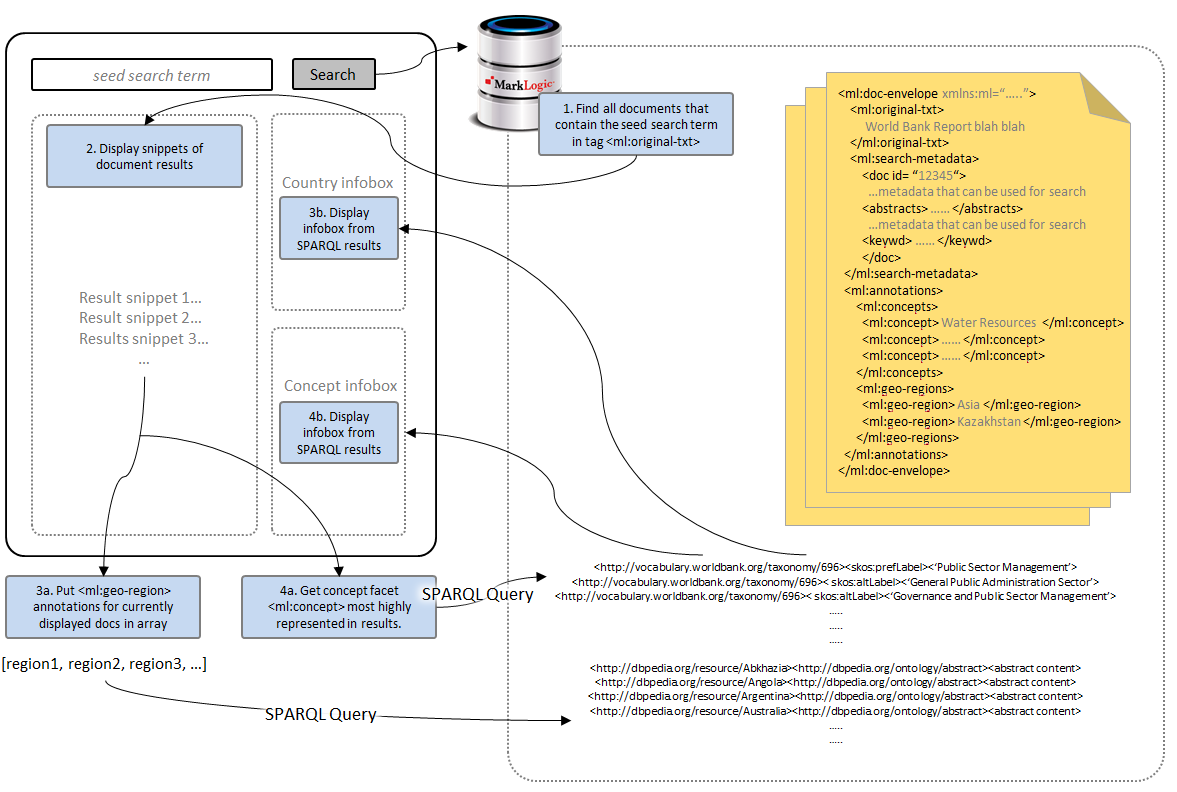
Figure 1: This high-level diagram illustrates how the query is executed to generate an infobox.
Example
We’ve built a small example application to illustrate and talk through the recipe.
Setup Instructions
MarkLogic Setup
- Download, install and run MarkLogic (version 8.0-4 or later)
Application Setup
- Go to the project’s GitHub repository
- Check the branch — make sure you’re on the worldbank branch (on the branch dropdown, select ‘worldbank’)
- Clone or download the repository
- Follow instructions 1-3 in the GitHub repository for setup (Again, make sure you’re on the worldbank branch before you run the setup. You can check by running ‘git branch’ in a terminal; the starred branch is the branch you are in.)
- Once you successfully complete the setup, you should be able to see the application at https://localhost:8554. Try doing a simple keyword search (e.g. Slovakia).
*Note: The setup process uses Node.js, npm, request-promise, and MarkLogic’s REST API. To learn more about how the REST API is used for database configuration and loading of documents, look at the project file setup.js.
Dataset
- Document Dataset: We used reports from The World Bank (source) for our document data. While we could have ingested this data directly into MarkLogic, we did not want to use the data as-is. Instead, we enriched each document (which corresponds to a single World Bank report) with two types of metadata: search metadata and annotations. The search metadata allows us to preserve interesting information about each report (e.g. source url, external publication date, etc.) that can be used for provenance tracking, as well as search. The annotations are topics or countries related to the document’s content — specifically, the topics (which we’ll refer to as “concepts” going forward) are from the World Bank Group taxonomy(see Ontology section below). While these annotations could be used for search, we specifically use the information for creating infoboxes.Figure 2 illustrates the XML structure of a document. The
<ml:original-txt>element contains the original text of the World Bank report.

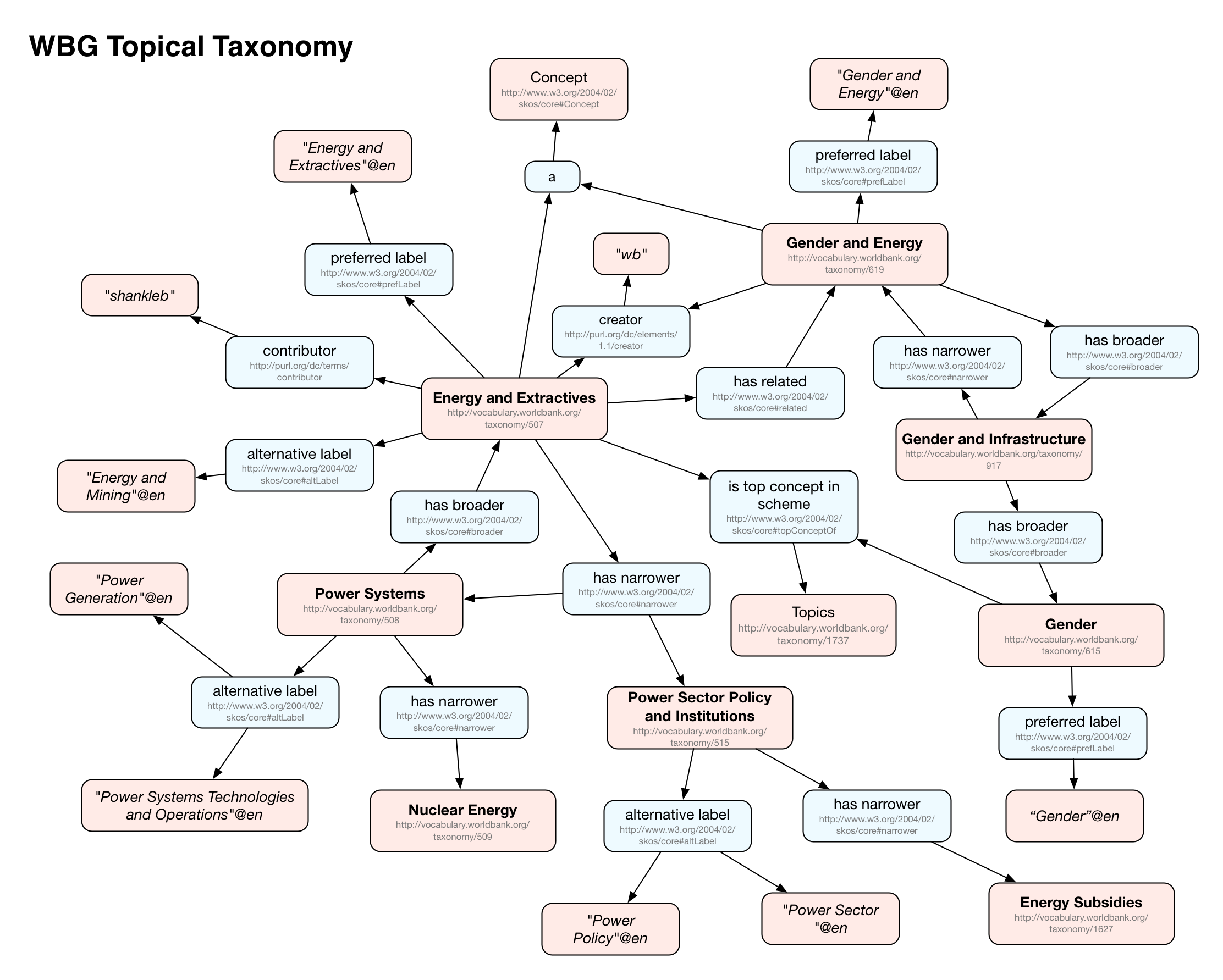
- Ontology4 Dataset: Our project uses triples from a number of open data sources: the World Bank Group (WBG) Topical Taxonomy (source), the Geographic Thesaurus from Geonames (source), and DBPedia (source).Similar to the document dataset, additional enrichment was done here. PoolParty, one of MarkLogic’s technology partners, provides a robust product suite of Semantic technology tools, such as ontology management and entity extraction. They enriched the original dataset of triples to include mappings between the WBG taxonomy, DBPedia, and documents, as well as new ‘concepts’ derived through corpus analysis. While we will not take advantage of the triples added through Semantic enrichment in this particular recipe, we will cover in the Discussion section how the enriched triples could have been used for an alternative design approach.Again, similar to the document dataset, the fully enriched ontology dataset will be loaded via the REST Management API when you run the setup procedures for the GitHub project.
All of the data was loaded into the application’s database infobox when you ran node setup in the setup process. You can explore the data in MarkLogic via Query Console at https://localhost:8000/qconsole by choosing database infobox as your content source and clicking “explore”. When you click “explore”, you should see all the data in the database. All documents are loaded with unique document names known as URIs (Uniform Resource Identifiers), which contain a prefix to indicate what directory they are in. You can click on one of the URI links to take a look at the document structure. For example, the World Bank report documents are loaded so that the URIs have the prefix “/worldbank/documents/” and thus are in that directory. Documents containing The World Bank, Geonames, and enriched triples are in directory “/worldbank/triples/”. The DBPedia triples were directly loaded as graphs to the triple store and can be found in the directory “/triplestore/”. MarkLogic’s xdmp:directory() makes it easy to find all the documents that live in a particular directory (sample code).
Analysis
Let’s walk through the application code to understand how it follows the design reflected in Figure 1. All of the code snippets are extracted from script.js (unless otherwise specified), which was loaded into a database called “infobox-modules” when you ran node setup. You can find the original file in the GitHub project folder “app.” Although I’ve extracted the relevant code snippet examples for you, I would recommend studying the original file to see how they fit holistically into the application code.
1. Find all documents that contain the seed search term in <ml:original-txt>
MarkLogic supports out-of-the-box search capabilities. Developers can choose from multiple interfaces to build their search application. (To learn more, please read the Search Developer’s Guide in MarkLogic’s documentation.) For this project, we are using Structured Queries to search against the REST API. We’re taking this approach because structured queries are easy to use and popular among MarkLogic search applications.
The following code builds a structured query to find all documents in the database that contain the search term in the element <ml:original-txt>. As you may remember, <ml:original-txt> contains the actual text of the World Bank report, so we are restricting our search to only look for the term in that portion of the document.
The structured query is POSTed to MarkLogic’s REST API endpoint /v1/search with the following parameters:
- options=infobox –The infobox query options were configured during the setup process (see the function definition for
function createOptions()in filesetup.jsand theconfig.searchSetupJavaScript object in fileconfig.js) when you rannode setup. To learn more about configuring query options, for the REST API, see Configuring Query Options in MarkLogic Documentation. - directory=/worldbank/documents/ — As previously mentioned in the Dataset discussion, the World Bank report documents are loaded so that the URIs have the prefix “/worldbank/documents/” and thus live in this directory. Here, we specify that our structured query is only searching for documents in this directory.
- format=json — Our application is written in JavaScript, so it is more natural to work with with a JSON response output.
// Build structured query
var term = $('#query').val(); // term from search box
// Match all documents containing an <original-txt></original-txt> element
// (with the namespace "https://marklogic.com/poolparty/worldbank"), whose contents match the search box term
var query = {
"query": {
"queries": [{
"and-query": {
"queries": [
{
"container-query": {
// constrain query to element containing original World Bank report text
"element": {
"name": "original-txt",
"ns": "https://marklogic.com/poolparty/worldbank"
},
// with search-box term
"term-query": {
"text": [ term ]
}
}
}
]
}
}]
}
};
// Get search results
$.ajax({
method: 'POST',
url: '/v1/search?options=infobox&directory=/worldbank/documents/&format=json',
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json'
},
data: JSON.stringify(query)
}).done(
......
structuredquery.js2. Display snippets of document results
We won’t spend much time on how to format the displayed results, but there are a few interesting things to take note of. The display titles in the results are taken from the <display_title> element in the search metadata of each document. Also, a function called formatSnippet() is called to highlight the search term in the built-in snippeting of search results, and that snippet is then appended to the result display. (See also Modifying Your Snippet Results for more details.)
...
}).done(
function(data) {
console.dir(data);
$('#spinner').hide();
$('#test').text(data);
$('#summary').html('Results found: ' + data.total);
if (data.total > 0) {
var regions = getRegions(data.results); //see 3a discussion below
var topic = getTopic(data.facets); //see 3b discussion below
console.dir('Region: ' + regions);
for (var res of data.results) {
results += '<div class="result">';
results += '<div class="result-title">';
results += res.metadata[0].display_title + ' - "' + res.metadata[1].lang + '"'; //display title taken from search metadata
results += '</div>';
results += '<div class="result-uri">' + res.uri + '</div>';
results += formatSnippet(res.matches); //snippet with matched term is appended to display of result
results += formatMeta(res.metadata); //annotation concepts are appended to display of result
results += '</div>';
}
...
formatsnippets.js3a (country infobox). Grab country annotations from document results to generate SPARQL query (Put <ml:geo-region> tags for currently displayed docs in array –> SPARQL query)
We want to generate an infobox for countries to display alongside the rest of the results. First, we look at the current documents displayed on the page (so, up to 10 based on our query option configuration infobox). Then, we get all the data items for those documents from the <ml:geo-region> tags and put them in an array.
/**
* Get array of region metadata strings from results.
* @param {object} results - search results.
*/
function getRegions(results) {
var result = [];
// Cycle through result items
for (var r in results) {
var metadata = results[r].metadata;
for (var m in metadata) {
if (metadata[m]["region"]) {
result.push(metadata[m]["region"]);
}
}
}
return result;
}
regionarray.jsThen, we run a SPARQL query that gets country information for the first item in the array where information is available. This will most likely be the information related to the first result (unless the first result is tagged too generally — e.g. World, North America — or the country doesn’t have triples). To do this, we first construct a SPARQL query that finds the label, abstract, thumbnail, and link for all RDF resources (represented by variable ?geo) that are of type (i.e.<https://www.w3.org/1999/02/22-rdf-syntax-ns#type>) country. We use the FILTER construct to filter results to only include RDF resources whose labels include the country of interest and whose labels and abstracts are in English.
Then, the SPARQL query is POSTed to MarkLogic’s REST API endpoint for Semantics /v1/graphs/sparql.
// Get GEO infobox data
var newArr = regions.map(function (curr, index, arr) {
return '"' + curr + '"@en';
});
var regionsStr = newArr.join(', ');
var results2 = '';
var sparql = 'SELECT ?label ?geo ?abstract ?thumbnail ?externalLink ' +
'WHERE { ' +
'?geo <https://www.w3.org/2000/01/rdf-schema#label> ?label ; ' +
'<https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <https://dbpedia.org/ontology/Country> ; ' +
'<https://dbpedia.org/ontology/abstract> ?abstract ; ' +
'<https://dbpedia.org/ontology/thumbnail> ?thumbnail ; ' +
'<https://www.w3.org/ns/prov#wasDerivedFrom> ?externalLink . ' +
'FILTER (?label IN (' + regionsStr + ')) . ' +
'FILTER (lang(?label) = "en") . ' +
'FILTER (lang(?abstract) = "en") . ' +
'}';
$.ajax({
method: 'POST',
url: '/v1/graphs/sparql',
headers: {
'Accept': 'application/rdf+json',
'Content-Type': 'application/sparql-query'
},
data: sparql
}).done(
...
regionSPARQL.jsIt may be useful to run portions of the SPARQL query in Query Console against the infobox database to understand the logic behind the filtering, as our approach for filtering is due to the makeup of our triples. It will also help you understand how the SPARQL query resolves. Here is a cleaned up version of the SPARQL query seen above (i.e. removed the JavaScript syntax) that you can run in Query Console:
#First, bring back all the labels, abstracts, thumbnails, and links for resources that are of type Country.
SELECT ?label ?geo ?abstract ?thumbnail ?externalLink
WHERE {?geo <https://www.w3.org/2000/01/rdf-schema#label> ?label ;
<https://www.w3.org/1999/02/22-rdf-syntax-ns#type> <https://dbpedia.org/ontology/Country> ;
<https://dbpedia.org/ontology/abstract> ?abstract ;
<https://dbpedia.org/ontology/thumbnail> ?thumbnail ;
<https://www.w3.org/ns/prov#wasDerivedFrom> ?externalLink .
# FILTER (?label IN ("阿富汗"@en, "Afghanistan"@en, "Afganistan"@en)) . #Uncomment this line to filter for labels that occur in the string
# FILTER (lang(?label) = "en") . #Uncomment this line to filter for labels with an English language tag
# FILTER (lang(?abstract) = "en"). #Uncomment this line to filter for abstracts with an English language tag
}
#SPARQL IN function definition: https://www.w3.org/TR/sparql11-query/#func-in
#SPARQL lang function definition: https://www.w3.org/TR/sparql11-query/#func-lang
regionSPARQL.rq
3b (country infobox). Display infobox from SPARQL results
We display the country’s label and the first 300 characters of the abstract in the infobox.
...
function(data2) {
if (data2.results) {
var results = data2.results.bindings[0];
if (results) {
$('#info_region').show();
results2 += '<div class="infobox-heading">Related</div>';
results2 += '<div class="infobox-title">' + results.label.value + '</div>';
var desc = $.trim(results.abstract.value).substring(0, 300)
.split(' ').slice(0, -1).join(' ') + '...';
results2 += '<div class="infobox-desc">' + desc + '</div>';
$('#info_region').html(results2);
}
}
}).fail(function(jqXHR2, textStatus2) {
console.dir(jqXHR2);
});
...
regioninfobox.js
4a (concept infobox). Analyze concept annotations from document results to generate SPARQL query
(i.e., Get concept facet <ml:concept> most highly represented in results –> SPARQL query)
As you may recall, in addition to each document being annotated with countries related to the World Bank report content, each document is also annotated with concepts from the World Bank taxonomy.
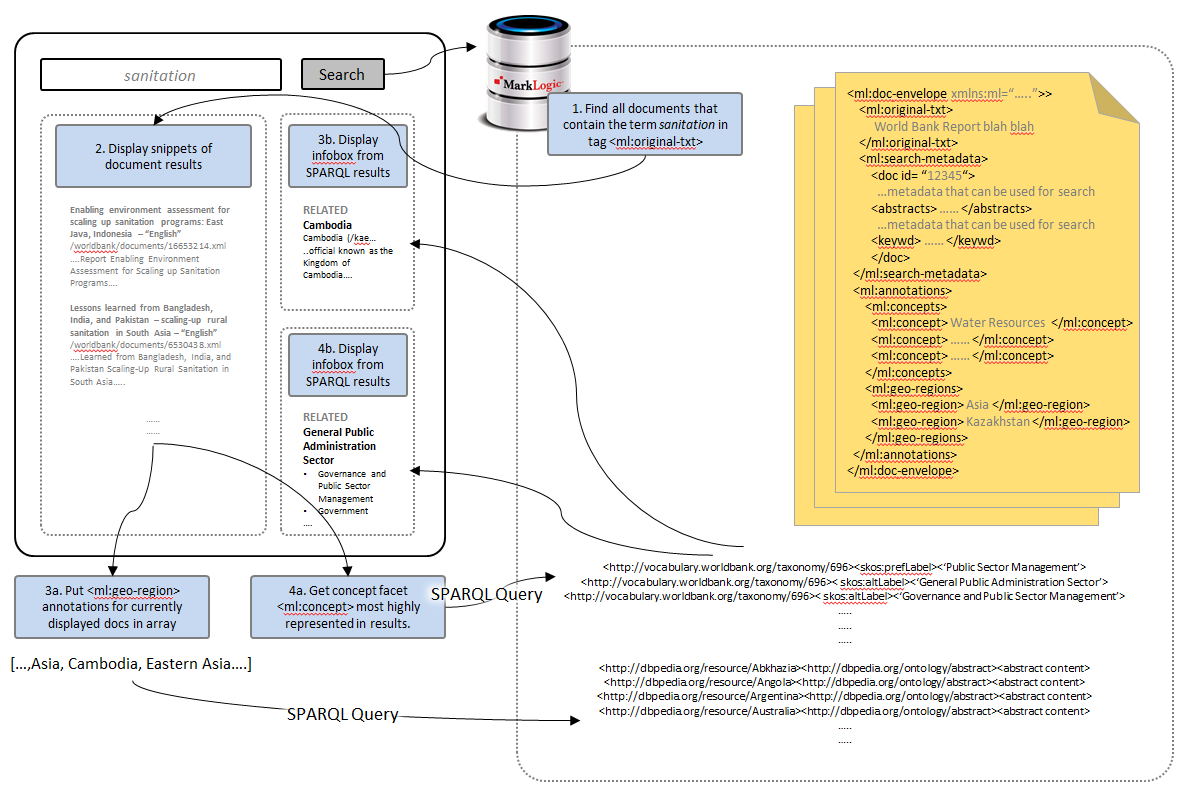
For our concept infoboxes, we include facets in the search results and get the <ml:concept> facet that is the most highly represented from the entire search result (not just the first 10 results displayed on the page). For example, if we search for the term “water”, we want to look at all our search results and get facet data that looks something like this:

…where each facet is a <ml:concept> value and the numbers indicate how many results contained that value. By ordering the facets in descending order, we can quickly identify the most represented concept by grabbing the value at the top.
How do we include the facets, you ask? MarkLogic’s Search API provides the ability to generate facets based on constraints.* To do this, we needed to setup a range index on element <ml:concept> (see JavaScript object config.databaseSetup in config.js). Then, we needed to setup a constraint on that same element (see JavaScript object config.searchSetup in config.js), where we specified that we want facets. Both of these database configurations in config.js were applied when you ran node setup.
(The below code snippet is part of the JavaScript object config.searchSetup in config.js. Notice the components used to define facets.)
config.searchSetup = {
"options": {
"search-option": [
"unfiltered"
],
....
"constraint": [
...
{
"name": "concept",
"range": {
"collation": "https://marklogic.com/collation/",
"type": "xs:string",
"facet": true,
"facet-option": [
"frequency-order",
"descending",
"limit=10"
],
"element": {
"ns": "https://marklogic.com/poolparty/worldbank",
"name": "concept"
}
}
}
],
...
conceptconstraint.js*Note: While you don’t need to fully understand constraints for this Semantics recipe, I highly recommend you read up on them after you finish going through this recipe material. Check out the 5-minute Guide to the Search API or read up on constraints in the MarkLogic Documentation.
With that configuration setup, facet results are included in our search results when /search is queried. For examples of what the result payload may look like, see Generating Facets. (To see an example payload specific to this application, here is what the facets payload looks like when you search for the term ‘sanitation’.) Because we specified in the facet options that we want the concept facet results ordered by frequency and in descending order, we know that the first facet is the most highly represented concept in the results. That makes it easy on our application code in script.js, which then only needs to grab the value of the first concept facet:
/**
* Get most important topic from result facets.
* @param {object} results - search results.
*/
function getTopic(facets) {
var result = '';
if (facets.concept) {
result = facets.concept.facetValues[0].name;
}
return result;
}
conceptfacet.jsThen, we pass that concept into a SPARQL query to find all World Bank taxonomy topics that have a label matching that concept, and then grab any alternative and/or preferred labels for those concepts that are in English. Our query also tries to grab abstracts, thumbnails, and links, but you’ll see later on that we don’t actually use that information.
... // conduct structured query and get the most highly represented concept in results
var topic = getTopic(data.facets);
...
// Get TOPIC infobox data
console.log(topic);
var topic_formatted = '"' + topic + '"@en';
var results3 = '';
console.log
var sparql2 = 'PREFIX skos:<https://www.w3.org/2004/02/skos/core#> ' +
'PREFIX dbo:<https://dbpedia.org/ontology/> ' +
'SELECT ?filterLabel ?abstract ?thumbnail ' +
'(GROUP_CONCAT(DISTINCT ?altLabel ; separator=", ") AS ?altLabels) ' +
'(GROUP_CONCAT(DISTINCT ?relLabel ; separator=", ") AS ?relLabels) ' +
'(GROUP_CONCAT(DISTINCT ?externalLink ; separator=", ") AS ?externalLinks) ' +
'WHERE { ' +
'BIND(' + topic_formatted + ' AS ?filterLabel) . ' +
'?concept skos:prefLabel|skos:altLabel ?filterLabel . ' +
'OPTIONAL { ' +
'?concept skos:prefLabel|skos:altLabel ?altLabel . ' +
'FILTER(?altLabel != ?filterLabel) ' +
'FILTER(lang(?altLabel) = "en") ' +
'} ' +
'OPTIONAL { ' +
'?concept skos:related ?related . ' +
'?related skos:prefLabel ?relLabel . ' +
'FILTER(lang(?relLabel) = "en") ' +
'} ' +
'OPTIONAL { ?concept skos:exactMatch ?dbpedia . ' +
'GRAPH <https://en.dbpedia.org> ' +
'{ OPTIONAL { ?dbpedia dbo:abstract ?abstract . } } ' +
'{ OPTIONAL { ?dbpedia dbo:thumbnail ?thumbnail . } } ' +
'{ OPTIONAL { ?dbpedia dbo:wikiPageExternalLink ?externalLink .} } ' +
'} ' +
'} LIMIT 5 ';
$.ajax({
method: 'POST',
url: '/v1/graphs/sparql',
headers: {
'Accept': 'application/rdf+json',
'Content-Type': 'application/sparql-query'
},
data: sparql2
}).done(
...
conceptSPARQL.js
Again, it may be useful to run portions of the SPARQL query in Query Console against the infobox database to understand the logic and the results of the query. Here is a cleaned up version of the SPARQL query, along with some explanatory comments, that you can run in Query Console:
PREFIX skos:<https://www.w3.org/2004/02/skos/core#>
PREFIX dbo:<https://dbpedia.org/ontology/>
SELECT ?filterLabel ?abstract ?thumbnail
(GROUP_CONCAT(DISTINCT ?altLabel ; separator=", ") AS ?altLabels) #Concatenate all the ?altLabel results together, separated by a comma, to be ?altLabels
(GROUP_CONCAT(DISTINCT ?relLabel ; separator=", ") AS ?relLabels) #Concatenate all the ?relLabel results together, separated by a comma, to be ?relLabels
(GROUP_CONCAT(DISTINCT ?externalLink ; separator=", ") AS ?externalLinks) #Concatenate all the ?externalLink results together, separated by a comma, to be ?externalLinks
WHERE {
BIND("General Public Administration Sector"@en AS ?filterLabel) . #Bind the top concept value to variable ?filterLabel
?concept skos:prefLabel|skos:altLabel ?filterLabel . #Find ?concept resources whose preferred labels and/or alternative labels match the ?filterLabel concept
OPTIONAL { #Optionally...
?concept skos:prefLabel|skos:altLabel ?altLabel . #...get those ?concept resources' other preferred labels and/or alternative labels...
FILTER(?altLabel != ?filterLabel) #...that aren't duplicates (i.e. that don't also match the concept)...
FILTER(lang(?altLabel) = "en") #... that have an English language tag.
}
OPTIONAL { #Optionally...
?concept skos:related ?related . #...get other resources that are related to the ?concept resources...
?related skos:prefLabel ?relLabel . #...and grab the preferred labels of those...
FILTER(lang(?relLabel) = "en") #...that have an English language tag.
}
OPTIONAL { ?concept skos:exactMatch ?dbpedia . #Optionally, get ?dbpedia resources that exactly match ?concept resources...
GRAPH <https://en.dbpedia.org> #...but restrict them to be from the DBpedia graph
{ OPTIONAL { ?dbpedia dbo:abstract ?abstract . } } #..and grab the abstract if available...
{ OPTIONAL { ?dbpedia dbo:thumbnail ?thumbnail . } } #...and grab the thumbnail if available...
{ OPTIONAL { ?dbpedia dbo:wikiPageExternalLink ?externalLink .} } #...and grab the wikiPageExternalLink if available.
} } LIMIT 5
#SPARQL GROUP_CONCAT function: https://www.w3.org/TR/sparql11-query/#defn_aggGroupConcat
#SPARQL BIND function: https://www.w3.org/TR/sparql11-query/#bind
#SPARQL | property path: https://www.w3.org/TR/sparql11-query/#propertypaths
#SPARQL OPTIONAL function: https://www.w3.org/TR/sparql11-query/#optionals
#SPARQL GRAPH: https://www.w3.org/TR/sparql11-query/#restrictByLabel
conceptSPARQL.rq4b (concept infobox). Display infobox from SPARQL results
We display an infobox that lists the most highly represented concept and its alternative labels.
...
function(data3) {
if (data3.results) {
var results = data3.results.bindings[0];
console.dir(results);
if (results && results.filterLabel) {
$('#info_topic').show();
results3 += '<div class="infobox-heading">Related</div>';
results3 += '<div class="infobox-title">' + results.filterLabel.value + '</div>';
var list = results.altLabels.value.split(',').reduce(function (prev, curr, index, arr) {
return prev + '<li>' + curr + '</li>';
}, '');
results3 += '<div>' + list + '</div>';
$('#info_topic').html(results3);
}
}
...
conceptinfobox.jsHere is an example diagram of an executed query:
Discussion
Key Takeaways
- Ontology4 management matters. A lot. When I refer to ontology management, I mean understanding what your triple dataset looks like, as well as the managing the quality of that data. As with all application development, having a good understanding of what your data looks like is crucial to your development process. Because our triples came from multiple open data sources (The World Bank, Geonames, DBPedia), our understanding of the dataset from each source varied. The World Bank taxonomy is well-documented, which made it easier to work with. On the other hand, because of the complexity and size of DBPedia, it was hard to figure out how all the triples related to each other (i.e. what the graph looked like), let alone write SPARQL queries against. Similarly, data quality affected how many OPTIONAL values we used — the “messier” the data, the more OPTIONAL values in the SPARQL call. The unsurprising conclusion is that open data tends to be more difficult to work with, and if you can work with RDF that comes from a controlled environment, your life will be easier.
- Semantic infoboxes allow for flexibility. Part of the beauty of Semantics is that you can continually add triples to your graph, so it is easy to ‘evolve’ your infoboxes over time. In this recipe example for our country infoboxes, we hardcoded our SPARQL query (predicates) so that we grabbed abstracts, thumbnails, and links. Imagine if we had done a generic
WHERE {?geo ?predicate ?object}(but kept the filter by country and language labels). This would grab all triples directly related to our country, and it would be possible to generate an infobox that showed different facts about different countries based on whatever RDF data would be available. Now, this may not necessarily be a good idea if you have a huge data set, but it demonstrates the potential flexibility of using Semantics for infoboxes.
Advantages, Disadvantages, and Alternatives
Advantages
The current application generates infoboxes based on document contents returned by the search result. Arguably, this recipe pattern provides a more “prescriptive set of results” for your infobox, and even provides an easy path to “guarantee” that an infobox will always show up. The country infobox demonstrates this; you’ll almost always get a country infobox, regardless of the seed search term you typed in. Thus, the advantage of this pattern is predictability and the capability to be more prescriptive in infobox results. The upfront work required to make this “guarantee” that all documents have certain types of annotations and that there are triples that correlate to those annotations.
Disadvantages
That upfront work would be the first disadvantage of this design — you do have to model both your documents (enrich with annotations) and triples (SPARQL is hardcoded, so triples for countries/concepts need to look fairly uniform) to make this recipe work. The other drawback of this recipe is that the infobox may not always be meaningful for the user, depending on what information they are looking for. (e.g. A search for “sanitation” brings back infoboxes on “Cambodia” and “General Public Administration Sector”.) Hence, this recipe may be better for search applications with targeted purposes (and you can be confident that the prescribed infobox will always be relevant) and less suitable for generic search applications (e.g. Google), where users search for random topics.
Alternative Designs
An alternative approach is for the SPARQL query to run directly off of the search term rather than the search results. The advantage of this approach is “cleaner” separation of query resolution between your infobox results and traditional search results; your document results don’t influence your infobox results and vice versa. The disadvantage of this approach is that your SPARQL query can get very complex (especially once you begin trying to support multiple search terms, e.g. sub-Saharan economic development). Also, unless you have a very good idea of (1) the types of queries your users will ask AND (2) how your entire ontology looks, it is much more difficult to design the application to “guarantee” the presence of an infobox when a search is conducted.
We also could have taken alternative choices for enriching our data. For example, instead of using annotations (i.e. the enriched XML elements) to tag documents with concepts, what if we had triples that indicated what documents are related to what concepts (e.g. :docURI :relatedToConcept: :GeneralPublicAdministration)? We could then use the document URIs (aka the document IDs) from our search results and pass those to a SPARQL query to get back data for concept infoboxes. The advantage of such an approach may be easier maintenance when you are adding or removing information from your ontology. With our currently demonstrated design, if you want to add a concept topic, not only do you have to add it to your ontology dataset, but you have to update all relevant documents with a concept annotation. With this alternative design, your updates would be restricted only to the ontology; you would (1) add triples about the new concepts and (2) add triples linking document URIs to those concepts. (Previously, I mentioned that PoolParty performed some pre-processing on the ontology dataset that we didn’t make use of; some of the pre-processing included adding triples that related document URIs to concepts. If you’re adventurous, try this design approach out and let us know how it works for you!)
Conclusion
Why Semantics for infoboxes?
One general advantage for employing Semantics for infoboxes is flexibility, as previously mentioned. For example, adding new facts to your country infobox about population size can be easily done in three steps: (1) Ingest triple data about the populations of each country, (2) Add a line to your SPARQL query, and (3) Update the application code for generating the infobox UI to display that information.
What may be most unique and advantageous about using Semantics for infoboxes, though, is the ability to manifest relationships and information about data in the data itself, and how that enables you to navigate the relationships in your data in a way that would be difficult without Semantics. This can be seen with the concept infobox. For example, in our triples (and according to the World Bank taxonomy), “General Public Administration Sector” is simply an alternative label for “Public Sector Management”. When a user does a search query (e.g. say, they search for “sanitation”) and gets a concept infobox for “General Public Administration Sector”, he can see related topics such as “Public Sector Management”. Now, imagine enhancing the infobox so that a user can select related topics and refresh the search results with reports that specifically contain that annotation, allowing them to refine and navigate searches based on relationships.
“Can’t I just do this purely using Search API facets on range indexes?” Well, yes, you could visually deliver a similar experience to your end user….but from an application development perspective, you lose a lot of flexibility and relationships are now persisted in application code rather than directly in the data. For example, revisiting step 4a in the Recipe Example Analysis, pretend that instead of passing the most highly represented concept as a parameter (e.g. General Public Administration Sector) into a SPARQL query, you decided to build an infobox straight off of the facet information. How and where would you store the information regarding other labels related to “General Public Administration Sector”? Theoretically, you could construct an XML document with a hierarchical structure that includes that information (and then write some JavaScript code that creates infoboxes based off of those XML documents), but what if your ontology cannot be expressed in a hierarchical, tree-like manner? How would you mimic SPARQL OPTIONAL in your application code? Going too far down the path of thinking how to make this work without Semantics can definitely make your brain hurt.
Finally, the biggest reason you’d want to consider using Semantics for infoboxes is inherent to the way Semantic works — you store data as facts. Infoboxes are snippets of facts pieced together about a topic, so it’s a perfect use case for Semantics.