MarkLogicデータハブ5.1チュートリアルへようこそ。このチュートリアルでは、MarkLogicデータハブプラットフォームを使って、素早くアジャイルなデータ統合でデータサービスを実現し、カスタマーに価値をもたらす方法について学習していきます。
このチュートリアルの内容、またその理由を確実に理解できるよう、さまざまなデータ統合プロジェクトに取り組むための推奨アプローチをまず紹介しておきます。
「データサービスファースト」
MarkLogicデータハブプロジェクトのデザイン・構築には、「データサービスファースト」のアプローチが推奨されます。「データサービスファースト」では、解決すべきビジネス問題をまず取り上げ、そこから遡るように作業していきます。
例としてMarkLogicデータハブプラットフォームを見てみましょう。
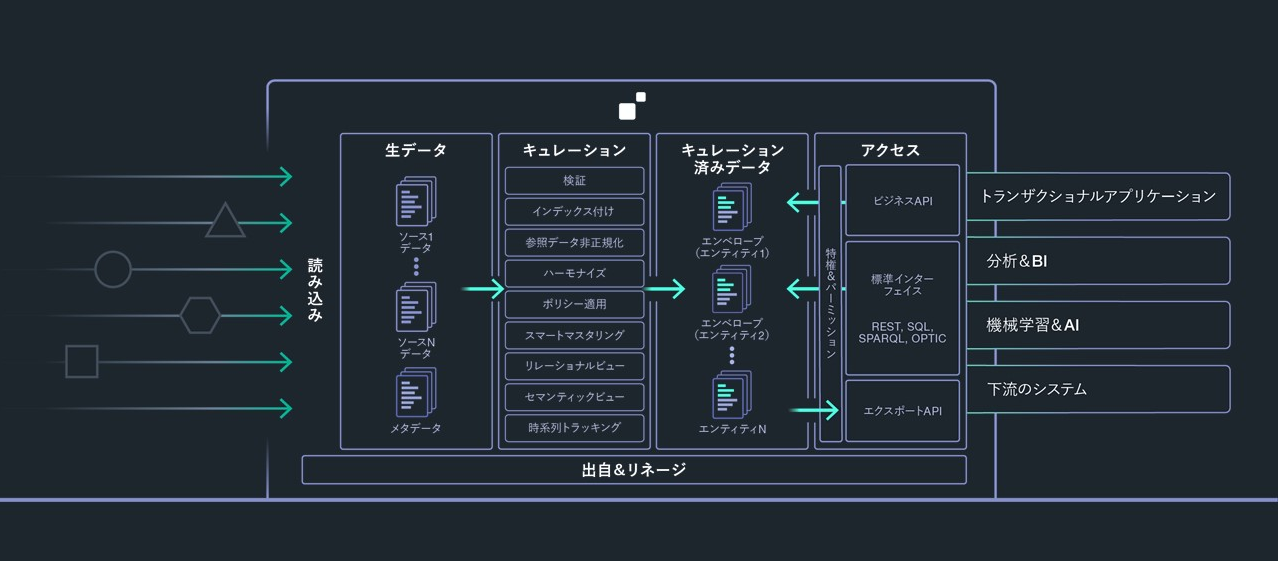
通常このような図は、左から右へと見ていくことが多いでしょう。しかし「データサービスファースト」では、これを右から見ていきます。そして以下を行います。
- 解決したいビジネス問題を特定します。すぐに価値を得るために必要なものを考えます。
- ここから、この問題に関連するビジネスエンティティを判断します。
- そしてこのエンティティに必要なデータソースに繋げていきます。
このアプローチはビジネスバリュー実現の事前作業を減らすようにデザインされています。これこそがアジャイルなソフトウェア開発の主要な目的です。
しかしこのようなアジャイルの目的を実現するには、きちんとしたデータレイヤーが必要です。ここにおいてMarkLogicデータハブプラットフォームのユニークなテクノロジーがその本領を発揮します。今回はその点に関してシンプルな例でご紹介していきます。
それではまず、今回のカスタマーと解決すべきビジネス課題を確認します。
カスタマー
「データサービスファースト」のアプローチを効率的に行うには、カスタマーおよび問題をきちんと理解しておく必要があります。もちろんここでは、解決時にカスタマーに大きな価値をもたらすようなビジネス問題を選択します。それではここで何を作るべきかをユーザーストーリーとして記述してみましょう。
カスタマーは「サンライズ保険」という架空の会社です。サンライズ保険のビジネスユーザーは、ある顧客の全体像の把握に苦労していました。というのも顧客データは企業内のあちこちに散在しているからです。
単純な例として、住宅保険と自動車保険の両方に加入している顧客の例を考えてみましょう。これらの保険契約データは別々のシステムに別々の形式で格納されています。
顧客がコールセンターに連絡してきた場合、この顧客および契約内容を確認するには、複数のシステムを移動しばらばらな情報をまとめなければなりません。これに加えて、別個のシステム内の多様なデータを担当者自身が処理する必要もあります。例えば、同一人物があるシステムでは「Joe Smith」、他のシステムでは「Joseph Smith」である場合などが想定されます。
また顧客データが、あるシステムでは最新だけれど他のシステムでは利用できないほど古いということも考えられます。この場合、担当者の貴重な時間が無駄になり、人的エラーの可能性がでてきたり、顧客がイライラすることになってしまいます。サンライズが提供する保険は多様かつ大量なので、この問題はさらに困難になります。
こういった複雑な状況に対応するため、サンライズではコールセンター担当者の業務を改善できるよう、これらのデータサイロを統合し顧客の全体像を把握する必要があります。
ユーザーストーリー
これらの課題について、私たちはサンライズ保険の人たちとミーティングをしました。そこで、コールセンター担当者用のカスタマーサポートアプリケーションが持つビジネスバリューは極めて大きいと判断しました。この議論に基づき、ユーザーストーリーを記述してみます。

今回のチュートリアルでは、以下のようなユーザーストーリーを考えることができます。
- コールセンターの担当者は、名前、メールアドレス、郵便番号で検索し、顧客の全体像を表示することで、カスタマーサポート業務を提供できる。
- コールセンターの担当者は、顧客のPIN(暗証)番号の下2桁だけを確認できればよい。これにより電話上で本人確認ができ、その際にデータのプライバシーやコンプライアンス規則にも準拠できる。
最終目的
ここでの目的は、さまざまな契約タイプにわたって散在している顧客データをコールセンター担当者が検索・発見できるアプリケーションのためのデータサービスを提供することです。今回の例では、特にデータベースティア部分を取り上げます。必要なデータ統合を行い、目的実現のためのデータサービスの例を確認していきますが、ミドルティア/ ブラウザティアの開発については取り上げません。
概念的には、ここで提供するデータサービスは、以下のようなワイヤーフレーム(webサイトの概要図)を実現するためのものです。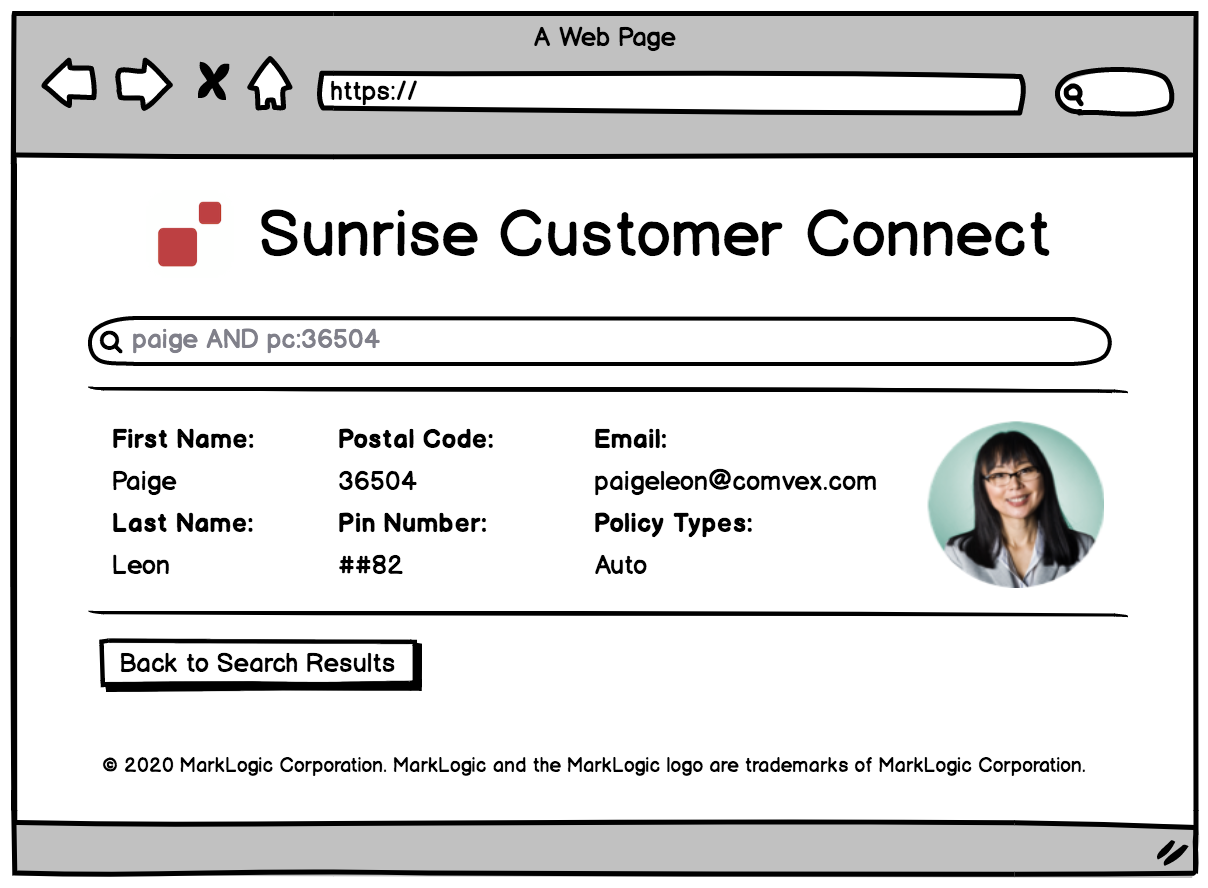
それでは始めましょう
このチュートリアルでは、実際にMarkLogicデータハブを使って一緒にやってみることで実践的な経験が得られるようになっています。このためには、まずマシン上にいくつか(無料のものを)セットアップする必要があります。
- MarkLogicデータハブプラットフォームでは基本的に以下が必要です。
- Java 9 JDK(あるいはそれ以降)。
- MarkLogicデータハブを実行するにはJavaが必要です。
- Gradle 4.6(あるいはそれ以降)。
- MarkLogicデータハブのデプロイタスクはGradleで自動化されます。
- ChromeあるいはFirefox。
- MarkLogicデータハブはQuickStartというツールを利用します。これはブラウザベースのツールで、これを使ってこのプロジェクトを構築していきます。
- Java 9 JDK(あるいはそれ以降)。
- MarkLogic自体も必要です。
- MarkLogic Server 9.0-10.3(あるいはそれ以降)。
- MarkLogic Data Hub 5.1 QuickStart *.warファイル
- Javaでこの *.warファイルを実行して、ハブの構築に利用するQuickStartインターフェイスにアクセスします。
- このチュートリアルに必要なもの。
- このチュートリアルで使うサンプルのデータとコードをダウンロードしてください。
- このフォルダをローカルマシン上の任意の場所で解凍します。
- 解凍したならば、*.warファイルを/quickstart-tutorial/project/ディレクトリに入れます。
- 準備が終わったら、ローカルフォルダは以下のようになっているはずです。
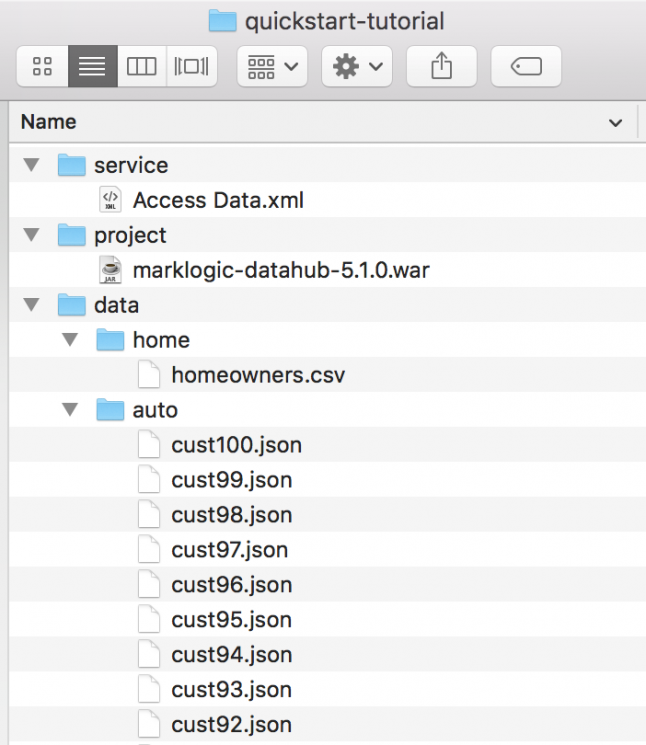
これでローカル環境の準備が終わりました。ではチュートリアルを始めましょう。
プロジェクトを作成する
まずQuickStartを実行し、新規プロジェクトを作成します。
- ターミナル(Linux / Mac)あるいはコマンドプロンプト(Windows)を開きます。
/quickstart-tutorial/project/ディレクトリに移動します(先ほどセットアップした場所にあります)。例えば、私のローカルマシン上では以下のようになっています。
- 以下のコマンドを使って、
/project/ ディレクトリからQuickStartを起動します。java -jar marklogic-datahub*.jar
- 起動すると以下のようになるはずです。

- ブラウザを開きます(FirefoxまたはChrome)。以下に移動します。
http://localhost:8080 - 以下が表示されます。

- [NEXT]ボタンをクリックします。
- [INITIALIZE]ボタンをクリックします。
- イニシャライズすると、このプロジェクトのハブのベースライン(基本)設定がファイルシステムに作成されます。この設定に基づき、QuickStartツールでハブを設定していきます。またこの設定は、他の環境あるいはクラウド(MarkLogicデータハブサービスによる)にもデプロイできます。本質的には、QuickStartツールはデータハブの設定を加速するためのものであり、これ自体はデータハブではありません。実際のところ、慣れればプロジェクト設定を直接IDEから管理することもできます。しかし今回の例では、まだみなさんが初心者だと想定し、QuickStartを使っていきます。このプロジェクトのイニシャライズが完了したら、以下のようなメッセージが表示されるはずです。
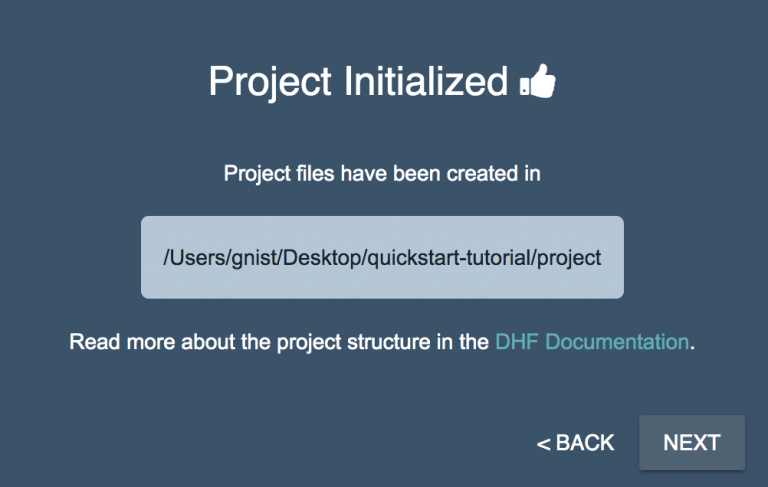
- [NEXT]ボタンをクリックします。
- プロジェクト環境を選択するように聞かれます。このチュートリアルでは、私たちは開発モードにおり、環境は1つ(ローカルコンピュータ)しかありません。デフォルト設定であるLOCALのままで、[NEXT]をクリックします。
- MarkLogicデータハブの構築には、適切なパーミッションを持つユーザーとして認証される必要があります。MarkLogicをインストール/イニシャライズする際に、MarkLogicの管理者(admin)ユーザーを作成することを求められます。MarkLogicデータハブの構築において、MarkLogicの管理者ユーザーである必要はありません。もしMarkLogicを使うのが今回初めてであれば、インストール時に作成した管理者ユーザーしかユーザーが存在しないはずです。話をシンプルにするため、ここでは管理者ユーザーとして作業を進めます。MarkLogic開発者用のトレーニングトラックでは、現実的なセキュリティモデルの実装についても学習できます。今回は、ローカルマシン上にMarkLogicをインストールした際に作成した管理者ユーザーとしてMarkLogicにログインします。
- 認証情報を入力し、[LOGIN]ボタンをクリックします。
- [INSTALL]ボタンをクリックします。
- このインストールによって、今回のMarkLogicデータハブに必要なリソースがすべて作成されます。このインストールでは、裏側でml-gradleを使ってデプロイを自動化しています。完了すると以下のようになります。
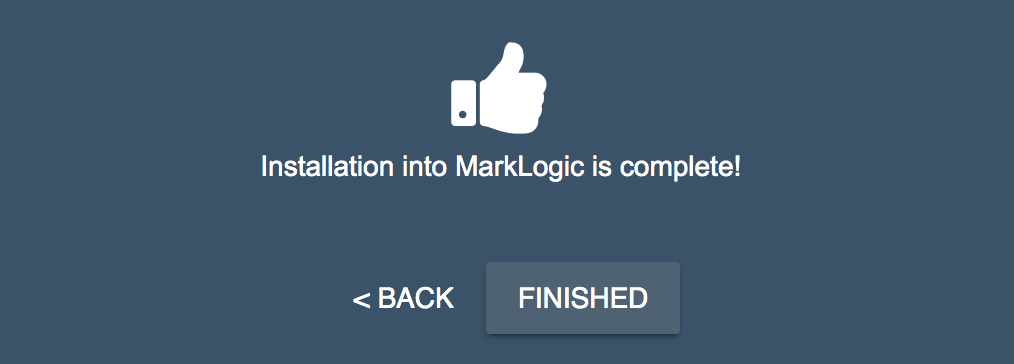
- [FINISHED]ボタンをクリックします。このMarkLogicデータハブのベースラインが、QuickStartダッシュボードに表示されます。
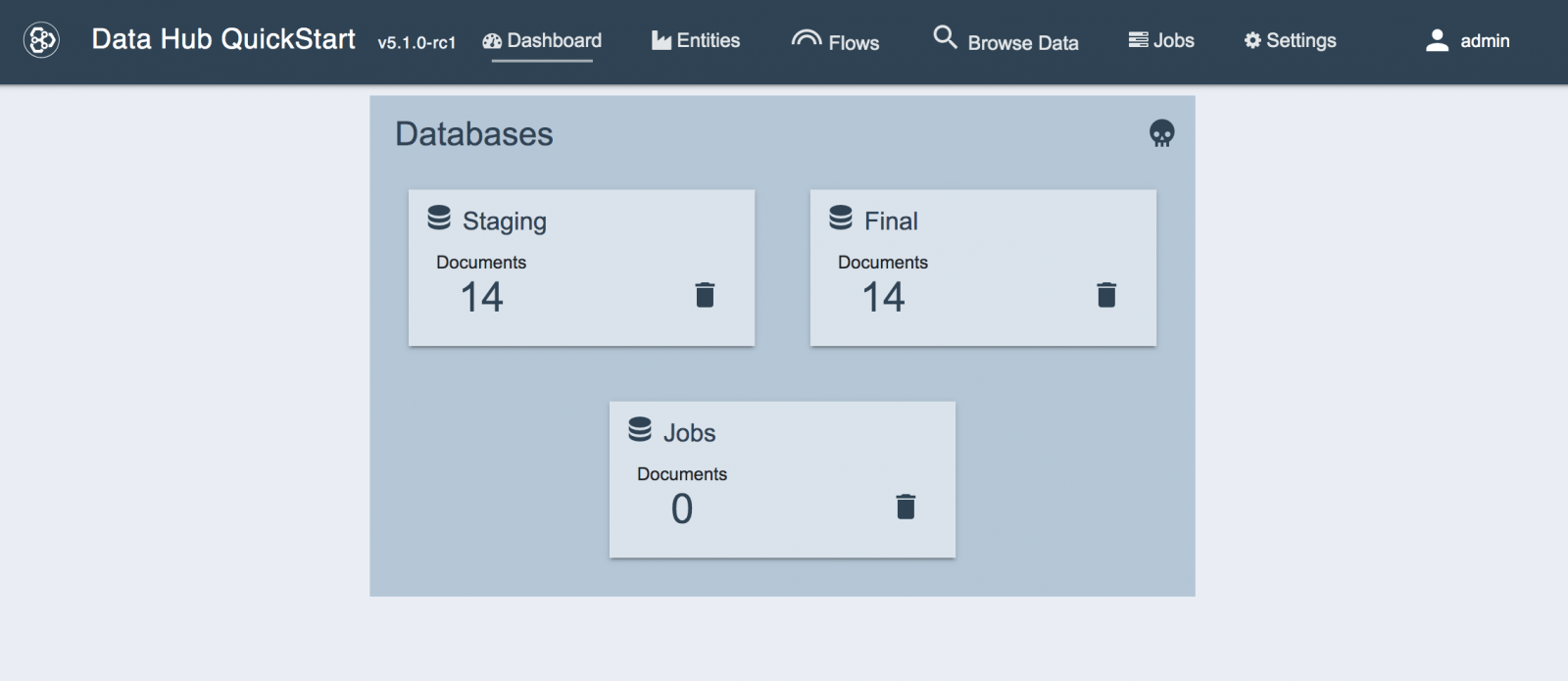
ここでいったんストップし、ここまで何をやったのかを確認してください。またここから何を作っていくのかについて考えてみてください。
これまでのところで、MarkLogicデータハブが作成されています。これはローカルのファイルシステム内のプロジェクト設定部分で定義されています。また関連するリソースは、ローカルマシン上で実行されているMarkLogicサーバーインスタンス上にセットアップ・設定されています。
しかし今のところ、これはベースラインの(叩き台となる)設定でしかありません。ここで、カスタマーが求めるデータサービス(先ほどユーザーストーリーとして記述したもの)に必要なデータソースを読み込む必要があります。
読み込み
MarkLogicデータハブは、柔軟であるようにできています。事前の大量のデータモデリング作業は不要です。データをそのままハブに読み込み、このデータのディスカバリーや活用をすぐに開始できます。
しかしこれはモデリングが重要ではないということではありません。もちろんモデリングは重要です。
MarkLogicでは、開発スプリントの中で迅速にモデルを追加できます。MarkLogicではデータをそのまま読み込み、その後キュレーションしていくので、カスタマーに何らかの価値を提供する時間が短縮されます。
それでは、この例で使用する住宅保険(home)および自動車保険(auto)のデータを読み込んでいきます。これにはフローを設定して実行する必要があります。フローはデータを処理するためのパイプラインです。フローはステップからできています。フロー内の各ステップは、データに対して何らかの処理を行う一連のトランザクションです。これは指定した設定に基づきます。
まず最初に、各データソース用の読み込みステップを含むフローを1つ作成します。その後、このフローを実行し、ハブにデータを入れます。
- データハブのQuickStartメニューから[Flows]を選択します。

- Manage Flows画面でNEW FLOWを選択します。
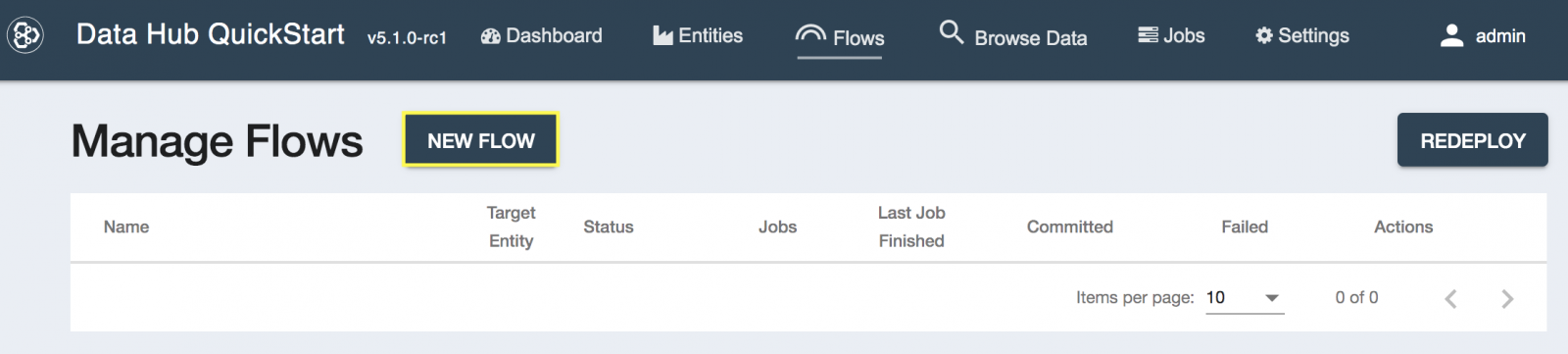
- 新しいフローを以下のように設定して[CREATE]をクリックします。
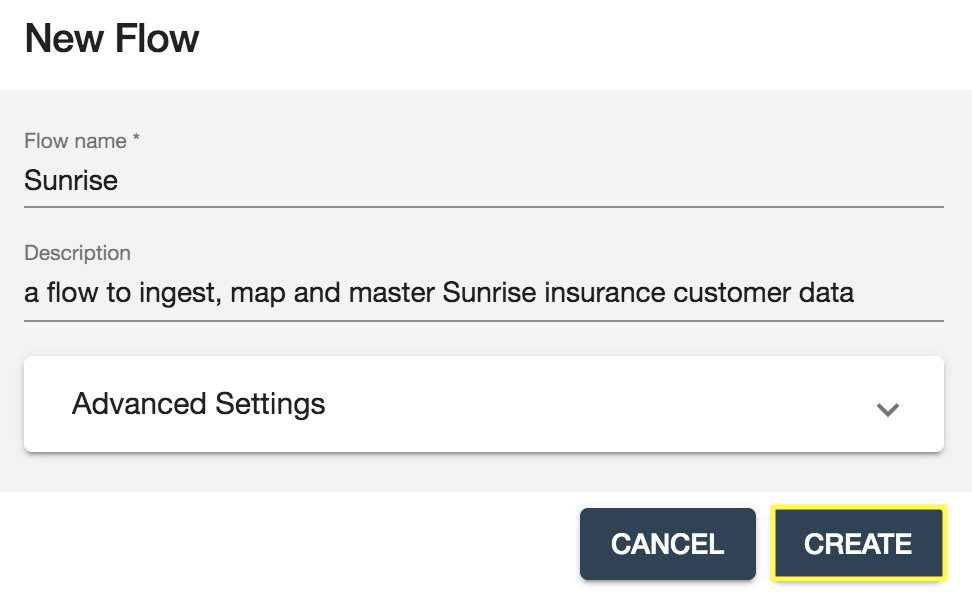
- 今作成したSunriseフローをクリックします。
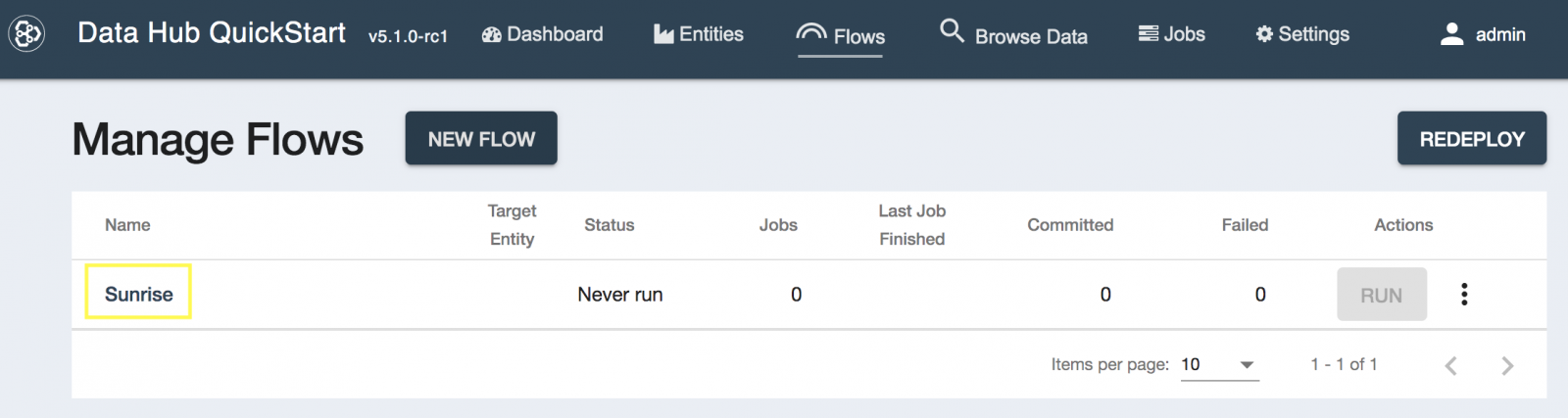
- [NEW STEP]をクリックします。
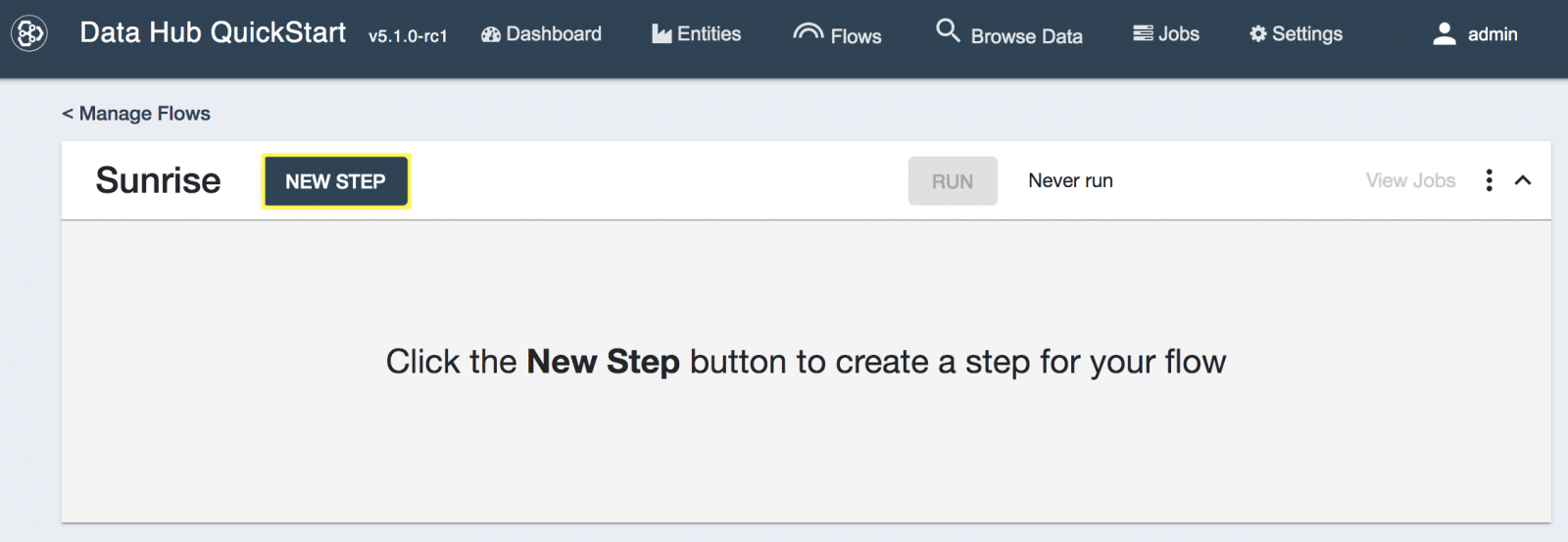
- ステップのタイプとしてIngestion(読み込み)を選択し、以下のように設定します(advanced settingsはデフォルトのままにしておきます)。[SAVE]ボタンをクリックします。

- 次に、loadHomeという読み込みステップを設定します。
- Source Directory Pathをローカルマシン上の
/quickstart-tutorial/data/home/ディレクトリに指定します。 - Source FormatをDelimited Textにします。
- Field Separatorをカンマ(,)にします。
- Target Formatはデフォルトのままにします(JSON)。
- Target Permissionsはデフォルトのままにします。
- Target URI Replacementを
^.*,'/customer/home'にします。URIは、データベース内のドキュメントの一意的な識別子です。設定をデフォルトのままにしておくと、元データのパス情報がURI内に含まれます。これだとURIが長くなってしまうだけでなく煩雑にもなります。この正規表現のマッチおよび置換により、URIがきれいになります。URI Previewセクションに、このインプット/パラメータによってどうなるのかが表示されます。この変更を反映するには、インプット部分の選択を外す(カーソルを移動する)必要があります。 - このステップ設定は以下のようになります。

- 次にこのフローを実行します。
- Sunriseフローの設定画面上で、[RUN]ボタンをクリックします。

- Run Flow画面上で、loadHomeステップだけを選択して、[RUN]ボタンをクリックします。

- このステップが完了したら、QuickStartメニューからBROWSE DATAを選択します。

- ステージングデータベースを確認します。loadHomeというコレクションにドキュメントが100件入っていることがわかります。このように、ドキュメントはステップ名に基づくコレクションで整理されます。
- 元のCSVファイルの1行が、1つのJSONドキュメントとなってデータベース内に入っています。任意のドキュメントを選択して、コンテンツを表示させます。データの出自(提供元)が自動的にトラッキングされ、エンベロープにラッピングされています。

- これで住宅保険データは読み込まれました。次に自動車保険データをこのSunriseフローにロードする、2つめの読み込みステップを追加します。
- QuickStartメニューから[Flows]を選択します。

- Sunriseフローをクリックします。
- [NEW STEP]ボタンをクリックします。
- 以下のように新しい読み込み(Ingestion)ステップをSunriseフローに追加し、[SAVE]ボタンをクリックします。
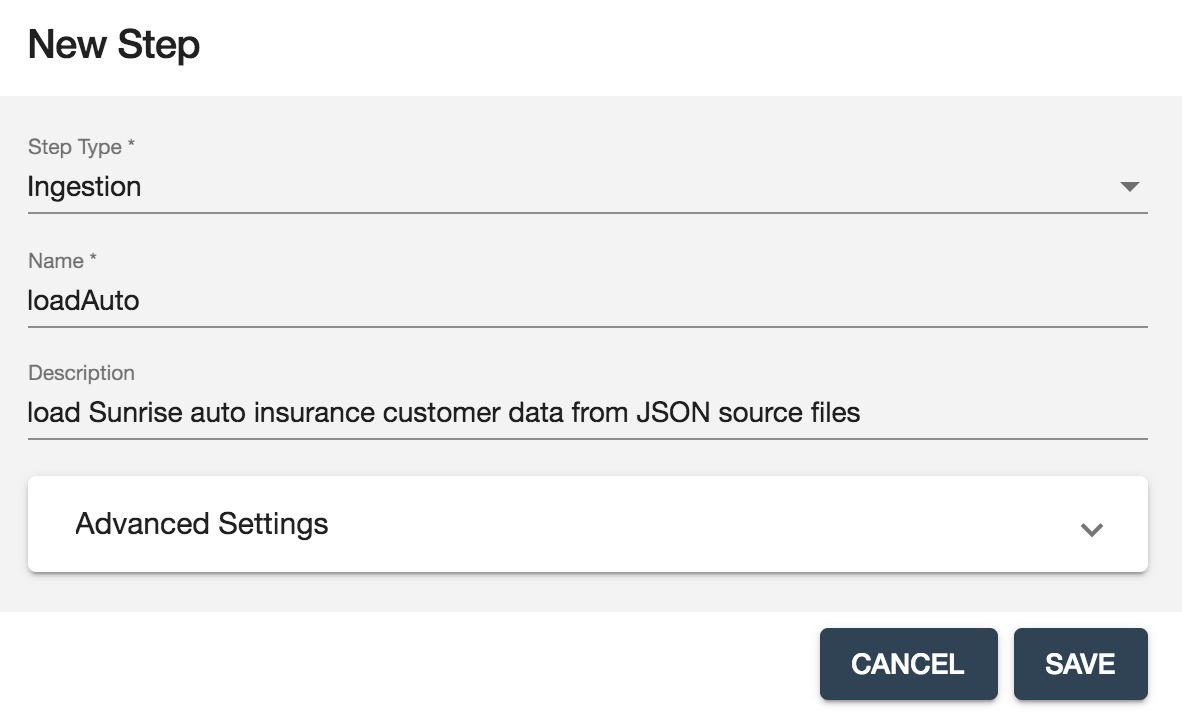
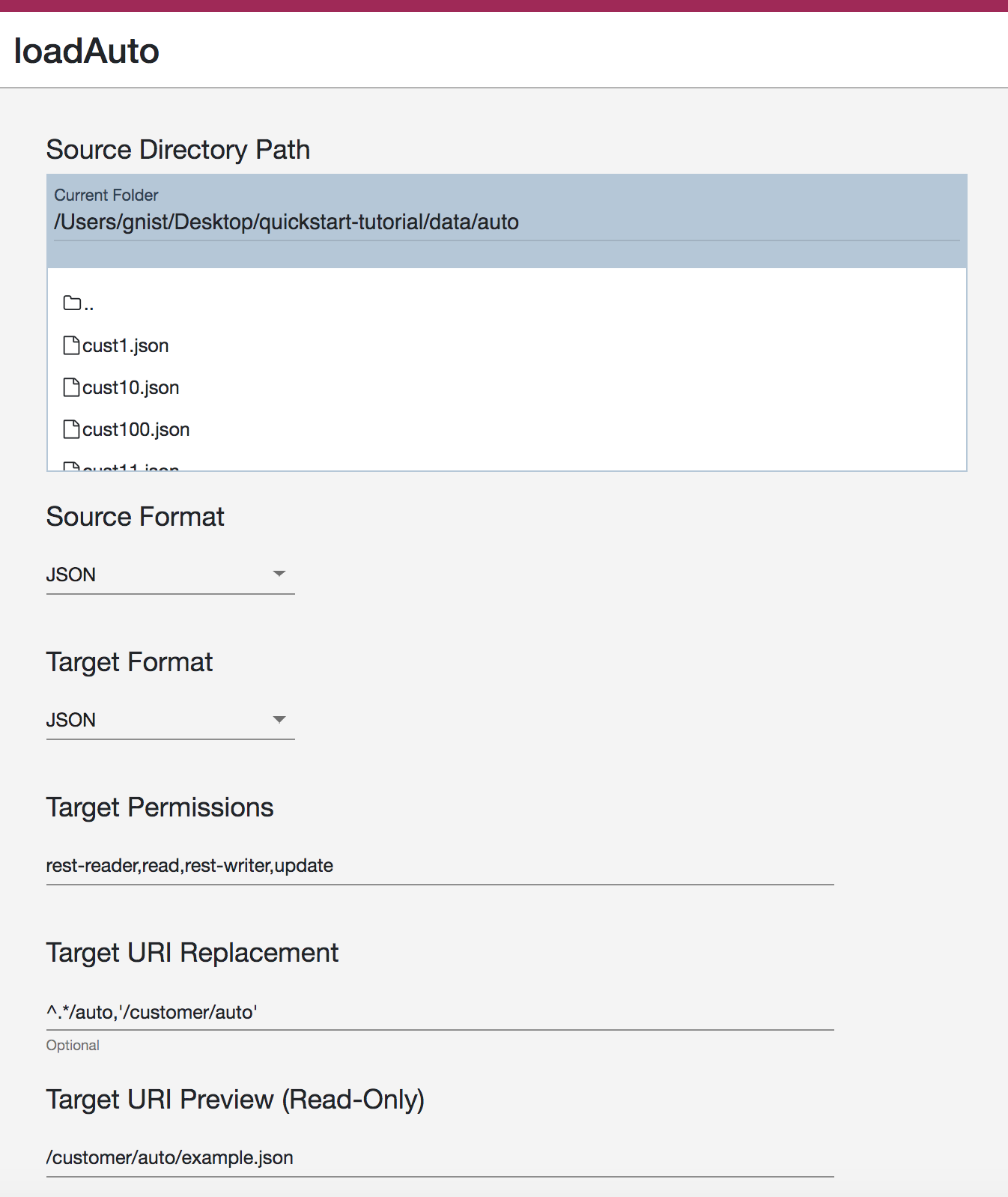
- 次に、loadAutoという読み込みステップを設定します。
- Source Directory Pathをローカルマシン上の
/quickstart-tutorial/data/auto/ディレクトリに指定します。 - Source FormatはJSONのままにしておきます。
- Target FormatはJSONのままにしておきます。
- Target Permissionsはデフォルトのままにしておきます。
- Target URI Replacementを次のようにします。
^.*/auto,'/customer/auto' - このステップの設定は以下のようになります。
- Sunriseフローの設定画面上で、[RUN]ボタンをクリックします。
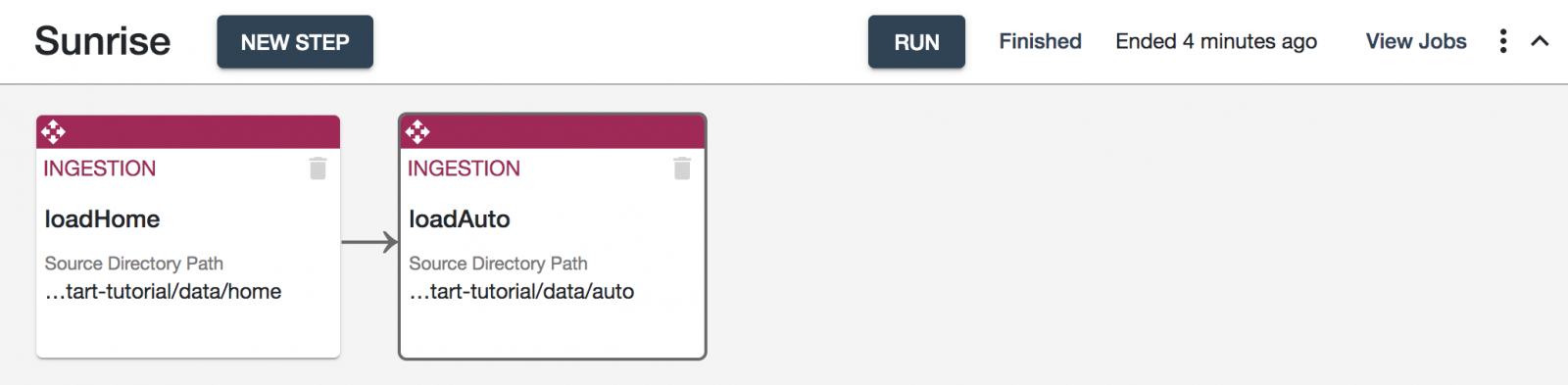
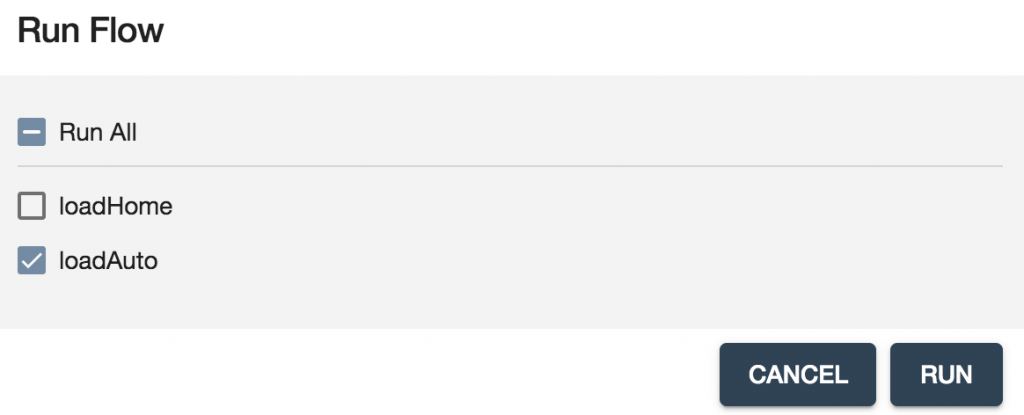
- Run Flow画面上で、loadAutoステップだけを選択します(homeデータはすでに読み込み済みです)。[RUN]ボタンをクリックします。
- このステップが完了したら、QuickStartメニューからBROWSE DATAを選択します。
- Stagingデータベースを確認します。loadAutoコレクションにドキュメントが100件入ったことがわかります。
- loadAutoコレクション内の任意のドキュメントを選択して、コンテンツを表示させます。

これで元のソースからステージングデータベースへのデータの読み込みが終わりました。ここでは作業をシンプルにするため、また自分のマシンで簡単に手順を追えるように、データをファイルシステムからロードしています。しかし実際のプロジェクトでは、データをさまざまなシステムから直接MarkLogicデータハブに入れることになるでしょう(Apache NiFiやMulesoftといったデータオーケストレーションツールを利用できます)。MarkLogic開発者用のトレーニングトラックでは、こういった内容も取り上げています。
ここでは、ファイルシステムからデータハブに読み込んだ住宅保険および自動車保険のデータを比較します。どちらのデータセットも一般的なビジネスオブジェクトである「カスタマー」に関するものです。どちらにも類似したプロパティ(顧客名など)があります。しかし各ソースのスキーマは違っています。例えば、顧客の下の名前はauto(自動車保険)データではFirstNameプロパティにあり、 home(住宅保険)データではfirst_nameプロパティにあります。
次のステップでは、カスタマーが求めるデータサービスの実現に必要なモデルとなるように、生データをキュレーションしていきます。これをさまざまな形の顧客データに対して行っていきます。
キュレーション:これは何か?
データキュレーションのプロセスでは、データのモデリングを行います。これはデータサービスを実現できるようにデータの形を整えるものです。キュレーションにより、顧客が求めるデータサービスを提供できるようにデータが「改善」されます。
キュレーションではまず最初に、エンティティを作成します。またデータサービスが利用する主要なデータプロパティを定義します。その後、さまざまなシステムから読み込んだ多様な形のデータの主要なプロパティを、エンティティの構成にマッピングしていきます。またデータのエンリッチという要件も想定されます。これはデータ内リファレンスの処理・特定・タグ付け、プロパティの変換、トリプルによるエンティティ間のモデリング、重複のマッチ・マージによるマスタリングなどを反復的に行うものです。
それでは、このチュートリアルのサンプルプロジェクトではどのようにデータをキュレーションしたら良いのかを考えてみましょう。
先ほどのユーザーストーリーおよびワイヤーフレームからわかるように、このデータサービスでは、顧客名、メール、郵便番号、契約タイプ、PIN番号の末尾2桁を扱う必要があります。また一元化された顧客像を生成する必要があります。つまり同一顧客が複数のシステムあるいは複数の契約タイプに存在している場合、これらの顧客ドキュメントをマッチ/マージし、一元化された顧客の全体像というビジネス目標を実現できるようにします。
大まかに言うと、以下を行う必要があります。
- これらのデータの主要プロパティを対象としたモデルを備えたエンティティを作成する。
- 元データをエンティティモデルにマッピングする、また要件を満たすためにデータを変換するためのマッピングステップを設定する。
- 重複する顧客をマッチ/マージするスマートマスタリングを設定する。
それでは始めましょう。
キュレーション:エンティティを作成する
このチュートリアルプロジェクトでは、シンプルにするためにエンティティを「カスタマー」だけにしています。ここでエンティティを作成し設定します。
- QuickStartメニューから[Entities]を選択します。

- レンチアイコンをクリックしNEW ENTITYを選択します。

- このエンティティのTitle(名前)をCustomerにし、説明(Description)を記述します。

- プロパティを追加し、以下のスクリーンショットのように設定します。ここでは、主キーアイコン(鍵の形)をcustomerIDプロパティに設定しています。主キーとして定義されたプロパティがあると、今後データハブエクスプローラというツールを使う際に便利です。また、要素レンジインデックスアイコン(稲妻の形)がpostalCodeプロパティおよびlastUpdateプロパティに付けられています。これにより、ユーザーストーリーに記述されたように郵便番号に特化した検索文法を設定できるようになります。またロジックの一部として最終更新の日時を利用することで重複した顧客データのマージを管理できるようになります(このチュートリアルの後半でマスタリングを行うときに出てきます)。また個人情報アイコン(南京錠の形)がfullPINプロパティについていることがわかります。これによりPINデータ全体を見るには、pii-readerという特別なロールが必要になります。プロパティの設定が終わったら、[SAVE]ボタンをクリックします。

- インデックスを更新するかどうか聞かれたら、[YES]を選択します。

- エンティティ設定が表示されます。これは必要に応じて移動、サイズ変更、編集できます。

キュレーション:マッピング
これでCustomerエンティティが作成・設定されたので、次のステップとしてそれぞれのデータソースをこのエンティティ定義にマッピングしていきます。これを行うために、Sunriseフローにマッピングステップを追加します。
- QuickStartメニューから[Flows]を選択します。
- Manage Flows画面でSunriseを選択します。
- [NEW STEP]ボタンをクリックします。
- ステップを以下のスクリーンショットのように設定し、[SAVE]ボタンをクリックします。UI内でAdvanced Settingsを展開する際に、コレクションのスコープおよびデフォルト設定を確認しておきます。ここではこのステップですべてのドキュメントをステージングデータベース(=ソースデータベース)で処理しています。これらはすべてloadHomeコレクションにあります(loadHomeステップを実行した際に読み込まれたドキュメントがすべてここにあります)。これらのドキュメントを、次に定義する設定に基づき処理/マッピングし、ファイナルデータベース(=ターゲットデータベース)に書き込みます。

- mapHomeステップを選択し、これを設定していきます。必要であれば、ステップをフロー内の別の場所にドラッグして移動できます。これはフロー全体を実行する際に、ステップを特定の順番で処理したい場合に便利です。今回のプロジェクトではこれはあまり関係ありません。というのもフロー内の各ステップを個別に実行するからです。
- マッピングステップを設定する際、処理対象となっているソースコレクションのサンプルドキュメントが自動的に選択されます。このサンプルを替えるには、ソースデータ設定オプション部分で別のドキュメントURIを入力します。今回の例では、デフォルトのサンプルのソースドキュメントで大丈夫です。
- ここで、エンティティ設定内の各プロパティごとにXPath式を定義する必要があります。プロパティ選択アイコンを使ってソース内のプロパティを選択し、エンティティで定義されたプロパティにマッピングできます。

- 関数選択アイコンを使って、エンティティマッピング時にデータプロパティを変換するための事前定義された関数を利用できます。

- マッピングステップを以下のスクリーンショットのように設定します。policyTypeには、‘home‘が決め打ちで入っています。またPINの末尾2桁はsubstring関数で生成されています。それ以外はすべて単純なプロパティ対プロパティのマッピングになっています。

- [TEST]ボタンをクリックし、このサンプルに基づくマッピングの結果を検証します。
- QuickStart画面の一番上にあるSunrise用のManage Flows部分に移動します。[RUN]ボタンをクリックします。
- mapHomeステップだけを選択し、[RUN]ボタンをクリックします。

- この結果を検証する必要があります。QuickStartメニューから[Browse Data]を選択します。
- stagingからfinalに切り替えます。

- ファイナルデータベース内にCustomerコレクションがあることがわかります(エンティティに基づいて命名されています)。Customerコレクション内の任意のドキュメントをクリックし、マッピングステップの結果を表示します。エンベロープのinstanceセクションにCustomerというプロパティがあることがわかります。ここにマッピングされたデータがすべて入っています。このキュレーション済みデータを今回のデータサービスで利用していきます。

- これで今回のデータサービス要件を満たすように住宅保険加入者のデータをマッピングできました。次に自動車保険加入者に関しても、同様にエンティティ定義にマッピングしていきます。
- QuickStartメニューから[Flows]を選択します。
- Manage Flows画面でSunriseを選択します。
- [NEW STEP]ボタンをクリックします。
- ステップを以下のスクリーンショットのように設定し、[SAVE]ボタンをクリックします。

- mapAutoステップを選択し、これを設定していきます。
- マッピングを以下のスクリーンショットのように設定します。この自動車保険データでは住宅保険データと違って、PINは数値として(文字列ではなく)モデリングしてあります。このため、このマッピングで末尾2桁だけを生成する前に、このPINを文字列に変換する必要があります。

- [TEST]ボタンをクリックし、このサンプルに基づくマッピングの結果を検証します。
- QuickStart画面の一番上にあるSunrise用のManage Flows部分に移動します。[RUN]ボタンをクリックします。
- mapAutoステップだけを選択し、[RUN]ボタンをクリックします。

- この結果を検証する必要があります。QuickStartメニューから[Browse Data]を選択します。
- 対象をstagingからfinalに替えます。
- Customerコレクション内の任意のautoドキュメントをクリックし、マッピングステップの結果を表示します。

これで、先ほど定義したエンティティデータに対する、異なるソースからの(スキーマが異なる)カスタマーデータのマッピングが終わりました。これで顧客が求めるアプリケーションに必要なデータサービスの実現にかなり近づきました。
次に、今回のビジネスユーザーであるコールセンター担当者に、一元化された完全な顧客の全体像(360ビュー)を提供できるようにしていきます。
キュレーション:マスタリング
顧客データの重複が発生する状況について考えてみます。同一顧客がサンライズの住宅保険と自動車保険の両方に入っていることもありえます。この場合、そのような顧客はこのデータハブに2回(さらに多くの顧客データを統合している場合にはそれ以上)含まれていることになります。
このような問題に対処するため、MarkLogicデータハブプラットフォームのスマートマスタリング機能があり、これによってビジネスユーザーが求める統合された顧客ビューを提供できます。スマートマスタリングでは容易にデータを分析し、設定されたロジックや規則に基づきマッチおよびマージします。
スマートマスタリングを導入するために、今回のフローにマッチおよびマージのステップを追加します。住宅保険と自動車保険の両方に加入する顧客を特定する規則を作成し、該当した顧客を1つのドキュメントにマージします。ここではデータの最新更新時期を考慮し、データのマージを設定します。これにより一番直近のデータの優先順位が高くなります。データキュレーションの最後にこれを行うことにより、ユーザーストーリーで定義した要件を満たすデータサービスが実現されます。
- QuickStartメニューから[Flows]を選択します。
- Manage Flows画面でSunriseを選択します。
- [NEW STEP]ボタンをクリックします。
- ステップを以下のスクリーンショットのように設定し、[SAVE]ボタンをクリックします。このステップはファイナルデータベースに対して実行されます。これによりCustomerコレクション内のすべてのドキュメントが処理されます。Customerコレクションには、マッピング済みの住宅保険と自動車保険の両方のデータが含まれています。

- 次にfindDuplicatesステップを設定していきます。これにはマッチオプションとそのしきい値があります。マッチオプションでは、マッチの際に重複と判断するためにデータのどの部分を対象とするのかを定義します。例えば、2つのドキュメントにおいてemailプロパティが完全に一致する場合、これらのドキュメントは同じ顧客に関するものだと言えるでしょう。また単なる完全一致だけでなく、よりインテリジェントかつ柔軟なマッチングも設定できます。例えば、2つのドキュメントのgivenNameプロパティを分析し、シソーラスで定義された同義語(シノニム)に基づいてこれらのマッチを判断できます。こうすれば、givenNameが「Joe」のドキュメントとgivenNameが「Joseph」のドキュメントをマッチとして扱えます。どれをマッチとして扱うのかの定義に関しては、強力なツールがさまざまあります(カスタムプログラミングしたロジックなど)。それぞれのマッチオプションには重み付けできます。重みを付けることで、それぞれのマッチ基準の影響力を変えられます。これはあるオプションは他のオプションよりも確実性が高い可能性があるためです。マッチオプションの定義が終わったら、マッチのしきい値を定義します。Match Thresholds(マッチのしきい値)では、定義したマッチオプションおよび総得点に基づいて分析し、「合致か否か」を判断します。マッチスコアの大きさに基づいて、異なるアクションを取ることもできます。例えば、このプロジェクトではスコアが特定の値を超えた場合、同一の顧客である可能性が十分高いとして、自動的にこれらのドキュメントをマージするアクションを取ります。他のアクションの例としては通知があります。これはマッチを示唆する要素がいくつかあるけれども、確信が持てないときに便利です。通知アクションでは、該当データをそのためのコレクションに入れ、後からユーザーが目検で判断できるようにします。これをアプリケーションの一部に組み込むこともできます。
- マッチのオプションおよびしきい値を追加して、以下の設定を作成します。

- QuickStart画面の一番上にあるSunrise用のManage Flows部分に移動します。[RUN]ボタンをクリックします。
- findDuplicatesステップだけを選択し、[RUN]ボタンをクリックします。
- 結果を確認します。QuickStartメニューから[Browse Data]を選択します。
- 対象をstagingからfinalに替えます。
- このマッチングステップに関連する新しいコレクションがいくつかファイナルデータベース内にできたことがわかります。

- findDuplicatesコレクションのファセットをクリックし、このステップの結果得られたドキュメントを確認します。
- マッチの要約に関するJSONドキュメントを確認してください。これらのドキュメントがCustomerコレクションに加わったことがわかります。
- 特にこれらのドキュメントのactionDetailsプロパティを確認してください。

- マッチした顧客はBarbara GatesとBrit McClarenであることがわかります。この結果は後ほど検証します。
- マッチングステップでは分析を行い、何をすべきなのかについてまで把握していますが、実際のアクションはまだ実行されていません。
- ここではこのアクションを完了させるために、フロー内にマージングステップを追加します。
- QuickStartメニューから[Flows]を選択します。
- Manage Flows画面でSunriseを選択します。
- [NEW STEP]ボタンをクリックします。
- ステップを以下のスクリーンショットのように設定し、[SAVE]ボタンをクリックします。ここではドキュメントのfindDuplicatesコレクションを処理したいとします。このコレクションには上述のマッチングステップから得られたマッチサマリードキュメントが含まれています。

- マージングステップには、どのようにデータをマージするのかを制御するための設定があります。今回のプロジェクトでは、エンティティ内の各プロパティ(policyTypeプロパティを除く)の値を1つだけ保持するようにマージオプションを作成していきます。エンティティ内で主キーとして定義されているプロパティ(今回の例ではidプロパティ)では、1つの値だけを保持するというのが要件です。それ以外のプロパティに関しては、すべての値を保持し、これを配列としてモデリングすることも可能です。しかし今回はデータ内にあるlastUpdateプロパティを使って、この顧客に関する最も直近のデータを保持することにします。一方、policyTypeに関してはすべての値(例えば最大5つまで)を保持し、この顧客が加入するサンライズ社の保険をすべて把握できるようにします。
- mergeDuplicatesステップを選択し、これを設定していきます。
- Merge Optionsを追加し、以下のように設定します。

- Merge Strategiesには何も設定する必要はありません。
- Timestamp Pathを以下のように設定して[SAVE]をクリックします。

- QuickStart画面の一番上にあるSunrise用のManage Flows部分に移動します。[RUN]ボタンをクリックします。
- mergeDuplicatesステップだけを選択し、[RUN]ボタンをクリックします。

- 結果を確認します。QuickStartメニューから[Browse Data]を選択します。
- 対象をstagingからfinalに替えます。
- このマージングステップから得られたコレクションがあります。

- ここで重要なのはマージングのステップは「破壊的」なものではないということです。つまりデータが失われることはありません。今回のプロジェクトでは、まず最初に顧客が200人いました。Barbara GatesおよびBrit McClarenはマッチングの基準を満たしたため、マージされています。つまり、Barbaraに関する2つのドキュメントが1つに、またBritに関する2つのドキュメントも1つにマージされています。このためsm-Customer-masteredコレクション内のドキュメント数は198件になりました。大切なこととして、この際、オリジナルのデータがなくなることはありません。これらのドキュメント4件は、sm-Customer-archivedコレクション内に保持されており、マージされたドキュメントだけを確認したい場合には、sm-Customer-mergedコレクションを見ればよいということになります。またsm-Customer-auditingコレクションではデータのガバナンスのリネージを把握できます。
- マージの結果を確認するために、sm-Customer-mergedコレクションを見てみます。例えば、Brit McClarenに関するキュレーション済みのカスタマーデータはこのようになります。

- sm-Customer-masteredコレクション内のデータを確認してみましょう。ここにキュレーション済みのカスタマーデータがすべて含まれていることがわかります。つまり、これが今回のデータサービスが利用するコレクションとなります。
これでデータのマスタリングが終わりました。今回のスプリントにおけるキュレーションプロセスおよびデータサービスの要件が完了しました。次のステップとして、ビジネスユーザーが求めるアプリケーションを実現するために、ハブからデータにアクセスできるデータサービスを構築します。
アクセス
MarkLogicでは、データハブ内のデータにアクセスし活用するためのインターフェイスが多数備わっています(Java、Node.js、REST、JavaScript、XQueryなど)。

MarkLogicプロジェクトで利用される一般的なテクノロジースタックは、MarkLogicデータハブとJavaScriptで記述されたデータサービスの組み合わせによるデータ層です(この組み合わせが必須あるいは唯一だというわけではありませんが)。このアプローチでは、IT部門に数人のMarkLogic開発者を置き、彼らにトレーニングを受けてもらうことでMarkLogicのエキスパートへと育てることができます。これらの開発者はハブを構築し、フローを作成し、ハブからデータにアクセスするためのデータサービスをプログラミングします。このアプローチにより、IT部門内の多くのミドルティアアプリケーションの開発者たちがMarkLogicデータハブを活用できるようになります。この際、使用するプログラミング言語は問いません。
MarkLogic開発者用のトレーニングトラックでは、MarkLogicデータハブプラットフォームを使ってデータサービスのプログラム、デプロイ、テストする際のJavaScript APIの使い方も学習できます。ここでは、ユーザーストリーに記述されている要件やワイヤーフレームとして表現されたアプリケーションを実現するために、必要なデータをハブから提供できることを示すシンプルな例を取り上げます。
これを証明するためにクエリコンソールを使ってみます。これはデータベースに対してアドホックなクエリを記述・実行するためにMarkLogicが提供しているツールです。
- クエリコンソールを開きます(ブラウザ内で新しいタブを開き、http://localhost:8000に移動します)。
- 話をシンプルにするために、MarkLogicの管理者としてログインします。繰り返しになりますが、管理者ユーザーとなることは必須ではありません。トレーニングをさらに受講することにより、プロジェクトごとに適切なセキュリティモデルを設定する方法を学習できます。
- ワークスペースをインポートします(下向き矢印をクリックし、Import Workspaceを選択します)。

/quickstart-tutorial/service/ディレクトリ内のQuickStart Tutorial.xmlファイルを特定します。- [Import]ボタンをクリックし、ワークスペースをクエリコンソールに読み込みます。

- ワークスペース内の[Customer Search]タブを確認します。Databaseがこのハブのfinalデータベースに設定されていることを確認してください。

- コメントおよびコードを確認します。このクエリを実行し、結果を表示させます。

- 返されたJSONを確認します。ユーザーが求めるものを実現するためのデータがすべて揃っていることがわかります。

これにより、JavaScriptのAPIを使って、顧客が求めるサービスを開発できることが証明されました。ここまでくると次のステップは、このデータハブおよびデータハブサービスをデプロイして利用可能にするということになります。
デプロイ
これでMarkLogicデータハブの開発が終わりました。これをどこにデプロイするのかについては柔軟に選択できます。ローカルのデータセンターにもデプロイできますが、おそらくはなんらかのクラウド(今日の企業の多くが選択しているように)にデプロイされる可能性の方が高いでしょう。
またMarkLogicデータハブサービスにより、クラウドへのデプロイが以前よりも容易になりました。インフラの購入や管理が必要ないので、必要に応じて拡張・縮退できます。これにより自分が得意なこと(革新的なサービスやアプリケーションの構築や提供)に注力できます。
このチュートリアルでは、MarkLogicデータハブサービスを使ってデータハブをクラウドにデプロイする手順を紹介しませんが、興味がある場合には役に立つリソースがいくつかあります。
レビュー
このチュートリアルの修了、おめでとうございます。それではここで今回学んだことを確認しておきましょう。
まず最初に、「データサービスファースト」に基づきMarkLogicデータハブを構築するという全体的なアプローチについて説明しました。このアプローチに基づき、何によって真のビジネスバリューが得れらるのかを特定し、これをユーザーストーリーとして表現しました。ここから遡って、要件やユーザーストーリーにあるデータサービスの実現に必要な、エンティティおよびデータソースを特定していきました。
ここでデータハブを構築し、フローの作成を始めました。まず、データサービスの提供に必要なデータだけを取り込むだけの読み込みステップを追加しました。このデータの読み込みは素早くでき、また容易なことを確認しました。事前のスキーマ定義は不要でした。
ここでデータのキュレーションを始めました。エンティティを定義し、異なる複数のデータソースをこのエンティティにマッピングしました。また今回のデータサービスで必要なデータに関する一貫性のあるビューを生成しました。
次にデータのマスタリングを行いました。ここで、定義したビジネス規則に基づき重複のマッチおよびマージができるようになりました。このマスタリングの結果として、顧客が求めるデータサービスの実現に必要なカスタマーの統合された全体像を提供できるキュレーション済みデータが得られました。
確認のために最終的なフローを提示しておきます。

いったん望ましい形でデータをキュレーションしたあとに、JavaScript APIでハブからデータにアクセスできることを確認しました。これにより、ここで行ったデータ統合やキュレーションにより、ユーザーストーリーで記述された要件をうまく満たせることが示されました。
最後に、MarkLogicデータハブおよびデータサービスを本番環境にデプロイする際のいくつかのオプションの概要を説明しました。
しかしみなさんのMarkLogicデータハブプラットフォームの旅は始まったばかりです。
次のステップ
まだまだ学ぶべきことはたくさんあります。
嬉しいことに、他にもたくさんの(無料です)リソースがあり、MarkLogicデータハブプラットフォームの理解を深めることができます。今後もっと複雑なプロジェクトを構築する機会もあることでしょう。その際にはMarkLogicの技術に関する深い知識があれば、今後の作業に対応できるでしょう。
まず最初に業務別のトレーニングトラックをチェックしてみてください。またMarkLogicコミュニティに参加し、製品、ブログ、ツール、チュートリアルを確認してみてください。それからもちろん、通常の製品マニュアルやデータハブのドキュメントを手元に置き、MarkLogicでの作業の際に役立ててください。
長い時間ありがとうございました。ハブを楽しんでください!