Amazon Web Service (AWS) accelerates a business’s ability to establish and maintain its internet presence by managing hardware infrastructure. This removes the need for companies to manage procurement, maintenance, monitoring, and replacement/upgrade of hardware. Now system administrators are tasked with monitoring these Elastic Compute Cloud (EC2) instances to guarantee availability, scaling, routing optimization, load balancing, software upgrades, and security patches. MarkLogic Data Hub Service makes systems administration in the cloud even easier.
MarkLogic Data Hub Service is a fully-automated cloud service to integrate data from silos. Delivered as a cloud service, it provides on-demand capacity, auto-scaling, automated database operations, and proven enterprise data security. As a result, agile teams can immediately start delivering business value by integrating and curating data for both operational and analytical use.
This tutorial gets users new to AWS up and running quickly by focusing on the specific components you need to get started. Further reading is recommended to fully understand all the technologies involved.
Data Hub Service Architectural Overview
The MarkLogic Data Hub Service on AWS sets up a Virtual Private Cloud (VPC) to allow MarkLogic to manage server and network resources.
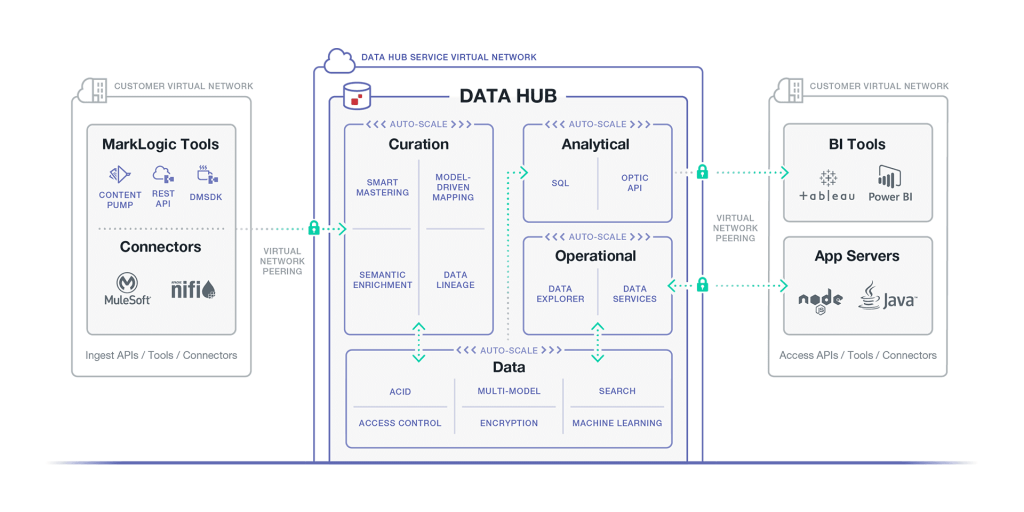
Figure 1: Overview of server and network resources managed by MarkLogic. Details on how this auto-scale feature works is available on the DHS product page.
A VPC is a virtual network of hosts that is isolated from all other virtual networks, providing more control over the hosts inside. Using a VPC reduces the risk of unauthorized communication to/from outside the network, and improves communication between hosts by removing the need to traverse the wider internet to talk to the host sitting nearby.
The MarkLogic Data Hub Service VPC employs auto-scaling configurations to increase and decrease the number of resources as usage spikes and drops automatically. This handles DevOps-related issues for the Data Hub Service user. A load balancer sits in front to coordinate incoming transactions for smooth communication between the ever-changing numbers of MarkLogic servers.
The MarkLogic Data Hub Service VPC can be configured as something publicly accessible, or configured as private, requiring peering to establish a connection with another VPC. For our purposes, we will focus on a publicly-accessible instance of the MarkLogic Data Hub Service. If you are interested in learning more about a private Data Hub Service instance, visit Setting Up MarkLogic Data Hub Service with a Private VPC.
Amazon Web Services
You will need to create an AWS account before creating a MarkLogic Cloud Service account. If you have already signed up for the accounts below, you may skip this section.
Creating an AWS account will display the screen below. Complete the process to create an AWS account, including your payment method and verification of your contact number.
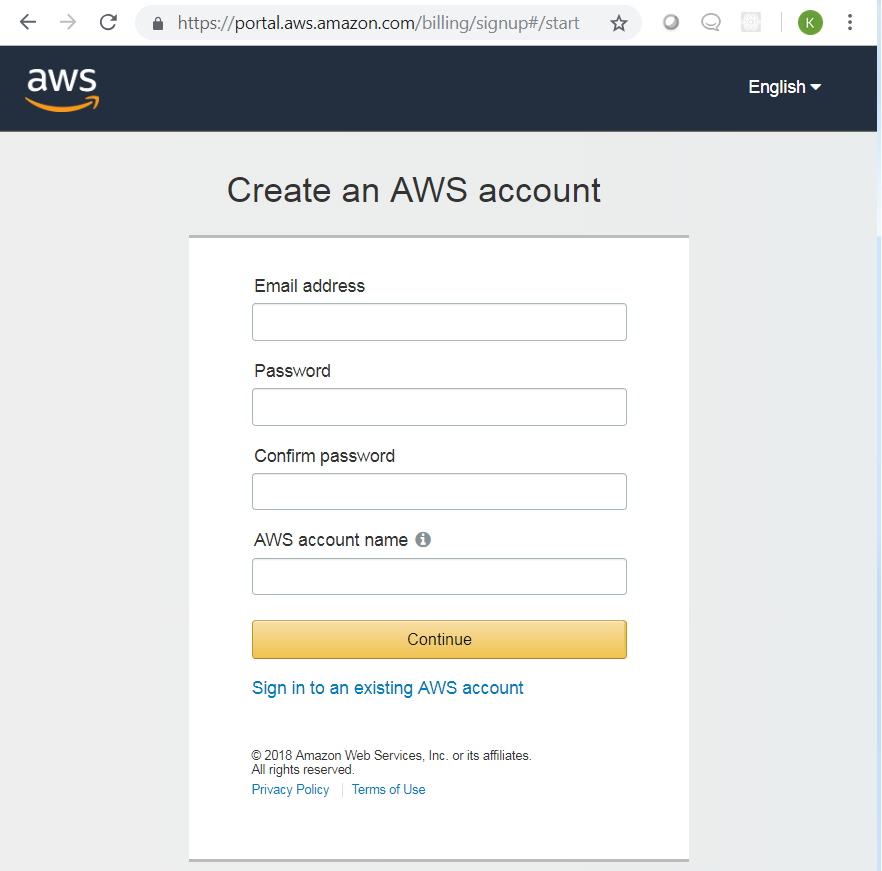
Figure 2: Create an AWS account
Proceed in registering the details required. Make sure to complete the registration including your payment method and verification of your contact number.
Sign up to MarkLogic as a Service
If you have already subscribed to MarkLogic Cloud Service, then you may skip this section of the guide.
Go to the Amazon marketplace and search for “MarkLogic data hub service”. Look for the “MarkLogic Data Hub Service” entry as shown below and click on “subscribe” on the loaded page.
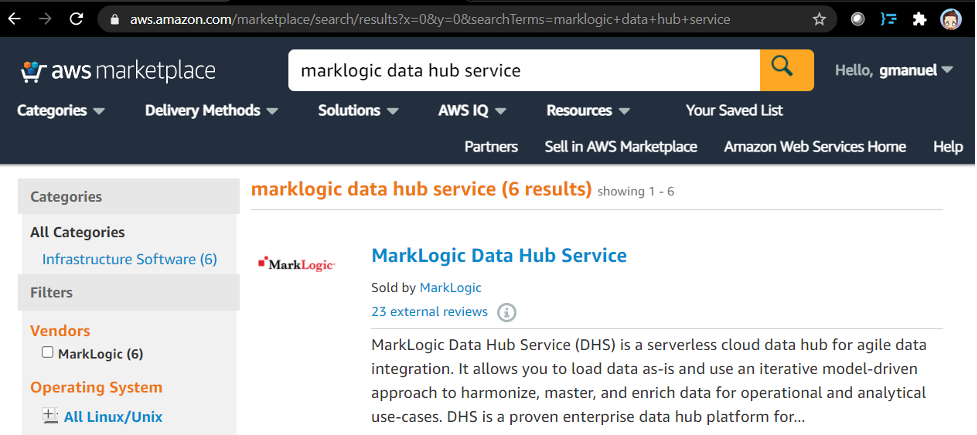
Click on “subscribe” on the loaded page.
MarkLogic Cloud Service Account
After subscribing, you should get redirected to the MarkLogic Cloud Service homepage. Note that this account is separate from your AWS account, so click on “Create a new Account” to proceed.
Create Network Configuration
A public cluster is easily set up and recommended for people trying to get familiar with the MarkLogic Data Hub Service.
- Go to MarkLogic Cloud Services and click on Network in the top navigation.

- Click on the “Add Network” button.

- Supply the “Name” and preferred “Region.” Do NOT check the VPC peering option.
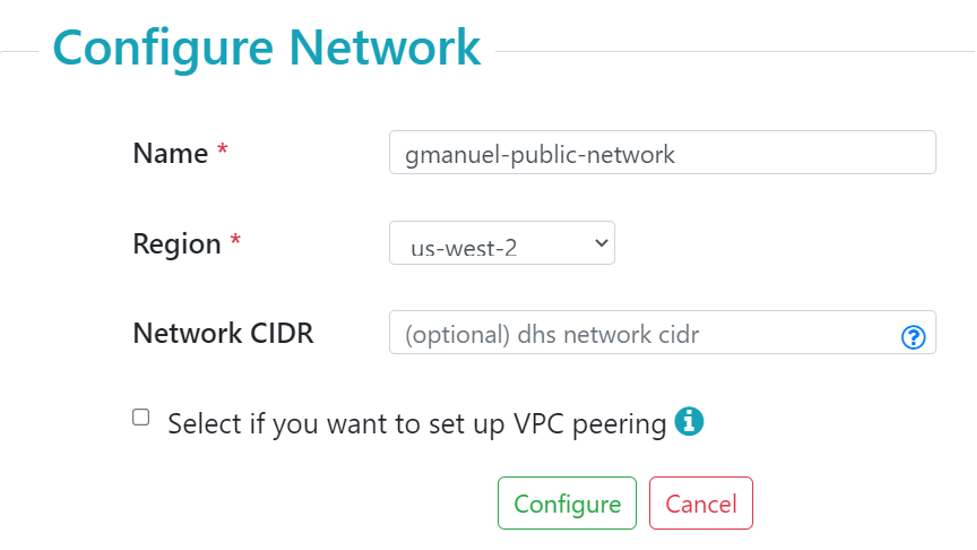 You may opt to provide your Network CIDR if you wish the generated IPv4 address to fall into a certain range.
You may opt to provide your Network CIDR if you wish the generated IPv4 address to fall into a certain range. - Click on the “Configure” button.
- Wait for the provisioning to complete. Make sure to click the refresh icon every so often.
You should end up with a NETWORK CREATED status, like the following:
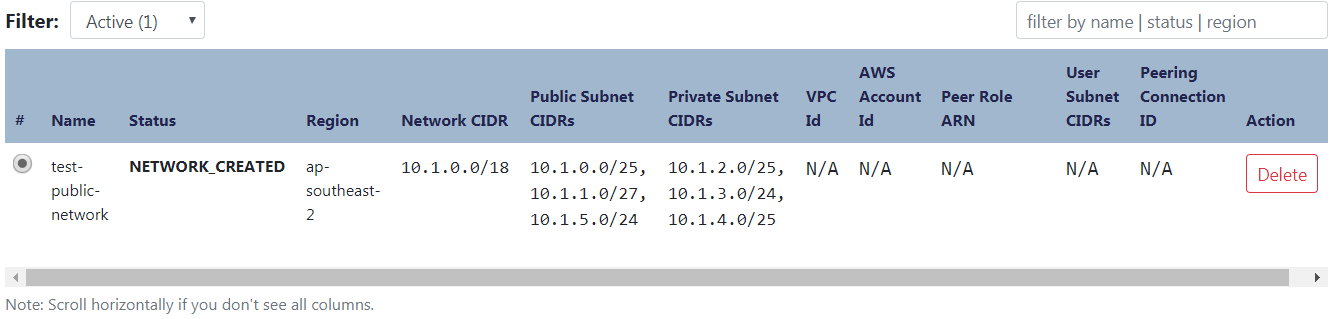
Figure 3: Network created confirmation screen
Create the MarkLogic Data Hub Service Instance
On the MarkLogic Cloud Services homepage, click on the “+ Data Hub Service” tab and supply the following information:
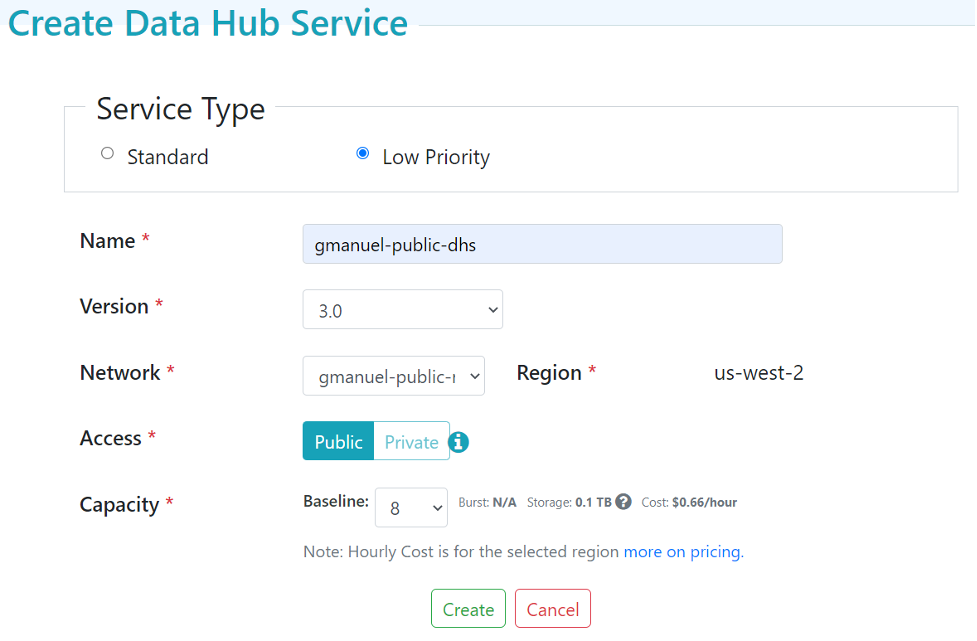
Figure 4: “Create Data Hub Service” interface, with Low Priority service type and Public access selected
“Service Type” of “Low Priority” will have the least amount of charges, but also the least amount of resources. This is recommended for the purposes of exploration and POC’s. This type of service will still have all the other features of DHS except the auto-scaling of resources and high-availability.
“Standard” on the other hand will have auto-scaling in effect and high-availability in effect. Cost relative to capacity is also higher on “Standard” service type. For the purposes of this guide, we will use the “Low Priority” type of service.
Version allows you to choose between 2.x and 3.x of DHS. At the moment the main differentiator is the version of Data Hub Framework installed. 2.x uses 5.2.x, while 3.x is using 5.4.x. Note that 5.2 may not accommodate the use of Hub Central.
Network lists down all the pre-configured networks available. For now, we would be using the public network we just configured.
Capacity describes how much resource is allocated and, for standard service type instances, up to how much it could get boosted (burst). Do note that the cost per MCU Is different between low priority and standard service types.
“Private” access is only applicable to networks that have configured “Peering” information. We will discuss details of the “Private Network” in part 2 of this series.
Clicking on “Create” will spawn the MarkLogic VPC as described in the Data Hub Service Architectural Overview. This can take a while, around ten minutes or so. You can hit the “refresh” icon on the upper left to get updates every now and then until you get something like the following:

Clicking on the service name link will take you to the Data Hub Service details page:
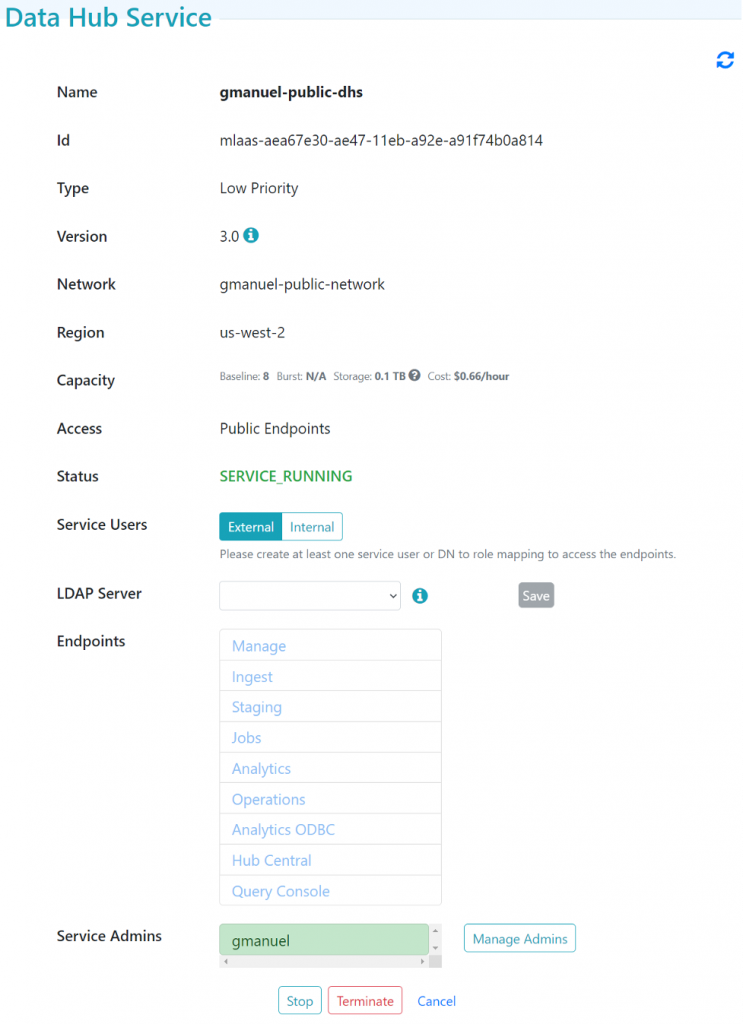
Figure 5: Data Hub Service details
Manage MarkLogic Data Hub Service Access
The links under “Endpoints” are disabled until users are created. To proceed in using your Data Hub Service instance, you need to specify users. Click on the “Internal” button to expose the “Manage Users” button. Click on the “Manager Users” button to add users with specific roles.

Figure 6: Users and roles for the Data Hub Service
“Service Users” are different from “Service Admins”. Service Users are credentials used to talk to the underlying MarkLogic instance, while Service Admins are credentials used to access the cloud services portal.
Note that the users created in Figure 6 above will not have SSH access to your servers. These users are MarkLogic accounts created to connect to the endpoints. These roles are described as follows:
| Role | Can do… |
| Data Hub Developer | Deploy modules, run flows |
| Data Hub Security Admin | Deploy custom roles |
| Data Hub Admin | Can do both of the above |
| Data Hub Operator | Run flows |
| PII Reader | Can view document element/properties flagged as PII in the entity configuration. |
| Data Hub ODBC User | Can access the Final DB using an ODBC client |
| Flow Developer | Can load modules into MarkLogic modules database, load TDE templates, and update indexes.
Basically your gradle task executor. |
| Flow Operator | Can do the ingest and run your flows. |
| Endpoint Developer | A subset of “Flow Developer”. Can load modules that would not overwrite any existing modules that he/she did not upload.
Cannot upload TDE templates nor update indexes. Meant as “Data Service” developer. |
| Endpoint User | For users that would consume the “Data Services” developed by the “Endpoint Developer” |
| ODBC User | Meant to be used for port 5432. Typically your business intelligence tool credentials or perhaps your Koop instance credentials. |
| Service Security Admin | For users that would configure your external security via LDAP |
The following table details the available endpoints provided by the MarkLogic Data Hub Service:
| Endpoints | Details | Description |
| Manage | Port: 8002
Content Database: App-Services Server: Curation |
Port to be used when loading modules, updating indexes and uploading your TDE templates. This is your standard Manage server as available in your local install of MarkLogic. Links to Monitoring Dashboard and History is available here along with Configuration Manager and QConsole. |
| Ingest | Port: 8005
Content Database: data-hub-STAGING Server: Curation |
XDBC App server to be used by MLCP. |
| Staging |
Port: 8010 Content Database: data-hub-STAGING Server: Curation |
Supports MarkLogic’s built in REST API. This allows you to confirm what got loaded to your STAGING database. |
| Jobs | Port: 8013
Content Database: data-hub-JOBS Server: Curation |
This port allows the user to view jobs and traces. |
| Query Console | Port: 8002
Content Database: App-Services Server: Curation |
Available for Low Priority only. |
| Analytics | Port: 8012
Content Database: data-hub-FINAL Server: Analytics |
Supports MarkLogic’s built in REST API. This allows you to confirm what got loaded to your FINAL database. |
| Operations | Port: 8011
Content Database: data-hub-FINAL Server: Analytics |
Supports MarkLogic’s built in REST API. This allows you to confirm what got loaded to your FINAL database. |
| Hub Central | Port: 8020
Content Database: n/a Server: n/a |
The endpoint launches the Data Hub Central application, which is the Data Hub graphical user interface designed for Data Hub Service (DHS). Use Data Hub Central to ingest raw data into your service and then curate and explore data directly in the cloud. To learn more, see About Hub Central. |
| ODBC | Port: 5432
Content Database: data-hub-FINAL Server: Curation |
Port to be used by your BI tools. |
Figure 8: Available Data Hub Service endpoints (please note that “Query Console” is only applicable to a “Low Priority” type of Data Hub Service instance)
Developer Access to the Data Hub Service
The following sections will provide some guidelines on what needs to be done and what can be done to load your modules to the Data Hub Service instance.
Note that you cannot currently use the Data Hub Developer Quickstart to directly develop on top of the MarkLogic Data Hub Service instance.
Confirm Initial Configuration
To confirm the availability of the initial configuration, load the Configuration Manager application at the “Manage” endpoint. You would have to adjust the path to include /manage. When prompted for credentials, use the configured user account with the “Flow Developer” role.
Project configuration
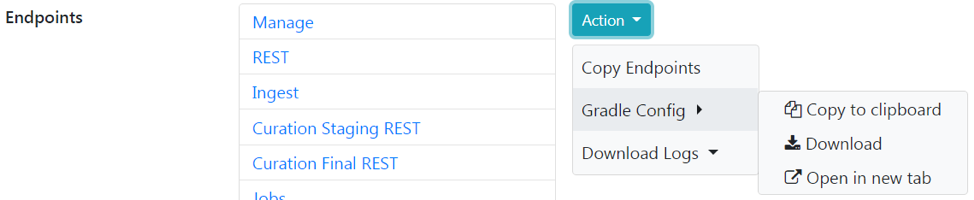
Gradle configuration for your DataHub project can be downloaded by doing the following steps:
- Click on the “Action” button
- Hover over “Gradle Config”
- Click on “Download” and save to your project folder
Gradle tasks
The table below lists the Gradle tasks available. These tasks are for a Data Hub Framework project, not your vanilla ml-gradle project.
| Task | Purpose |
hubInstall |
Install DHF modules. |
mlLoadModules |
Deploy your code custom code beyond the default code of DHF |
mlUpdateIndexes |
Deploy your indexes as defined in <project-root>/src/hub-internal-config/databases/your-db.json |
mlDeployViewSchemas |
Deploy your TDE templates as defined in <project-root>/src/hub-internal-config/schemas/tde/your-template.json |
hubRunFlow |
Run your harmonization flow. |
hubDeployAsSecurityAdmin |
Deploy custom roles. |
hubDeployAsDeveloper |
Deploy modules, entity definitions, tasks, triggers, etc. |
hubDeploy |
Deploy/publish your entire project into a DHS instance. |
Figure 9: Gradle tasks and purposes
Other ml-gradle tasks are also supported, e.g. mlLoadModules, mlUpdateIndexes, etc. The ‘mlDeploy’ task is unavailable for MarkLogic Data Hub Service users since users do not have the full admin role. More Data Hub specific tasks are listed in the Data Hub documentation.
Access for Data Services
“Staging”, “Analytics” and “Operations” support both the built-in MarkLogic REST API and the Data Services First (DSF) endpoints. DSF modules would have to reside in a ‘ds’ folder as noted in the docs. Conversely, these endpoints would have to be accessed with a ‘/ds’ path prefix.
If you run into issues using MarkLogic Data Hub Service, contact Support. MarkLogic engineers and enthusiasts are also active in Stack Overflow, just tag your questions as ‘marklogic’.
Ready for more? If you are interested in learning more about a private Data Hub Service instance, visit Setting Up MarkLogic Data Hub Service with a Private VPC.